Chapter 22 Cassandra
Paper: https://docs.datastax.com/en/articles/cassandra/cassandrathenandnow.html
22.1 IDE
ant generate-idea-files
https://wiki.apache.org/cassandra/RunningCassandraInIDEA
If you take a look at the Readme file at Apache Cassandra git repo, it says that,
Cassandra is a partitioned row store. Rows are organized into tables with a required primary key.
Partitioning means that Cassandra can distribute your data across multiple machines in an application-transparent matter. Cassandra will automatically repartition as machines are added and removed from the cluster.
Row store means that like relational databases, Cassandra organizes data by rows and columns.
- Column oriented or columnar databases are stored on disk column wise.
e.g: Table Bonuses table
ID Last First Bonus
1 Doe John 8000
2 Smith Jane 4000
3 Beck Sam 1000In a row-oriented database management system, the data would be stored like this:
1,Doe,John,8000;2,Smith,Jane,4000;3,Beck,Sam,1000;
In a column-oriented database management system, the data would be stored like this:
1,2,3;Doe,Smith,Beck;John,Jane,Sam;8000,4000,1000;
Cassandra is basically a column-family store
Cassandra would store the above data as,
"Bounses" : {
row1 : { "ID":1, "Last":"Doe", "First":"John", "Bonus":8000},
row2 : { "ID":2, "Last":"Smith", "First":"Jane", "Bonus":4000}
...
}22.2 Start and Stop
- start new cassandra:
ansible cassandra -a "rm -fr /var/lib/cassandra/"
ansible cassandra -a "mkdir -p /var/lib/cassandra/data"
ansible cassandra -a "mkdir -p /var/lib/cassandra/saved_caches"
ansible cassandra -a "mkdir -p /var/lib/cassandra/hints"
ansible cassandra -a "mkdir -p /var/lib/cassandra/commitlog"
ansible cassandra -a "mkdir -p /var/lib/cassandra/log"
for i in `seq 0 3`;do ssh u$i "cassandra -R"; done- jps:
$ansible cassandra -a "jps"
192.168.0.100 | SUCCESS | rc=0 >>
13678 Jps
13182 CassandraDaemon
192.168.0.102 | SUCCESS | rc=0 >>
12374 Jps
11898 CassandraDaemon
192.168.0.101 | SUCCESS | rc=0 >>
11733 CassandraDaemon
12221 Jps
192.168.0.103 | SUCCESS | rc=0 >>
12017 CassandraDaemon
12505 Jps- stop cassandra:
for i in `seq 0 3`; do ssh u$i "stop-cassandra"; donehttps://svn.apache.org/repos/asf/cassandra/tags/cassandra-0.3.0-final/
https://www.zhihu.com/question/19592244
http://blog.csdn.net/firecoder/article/details/7012993
http://blog.csdn.net/firecoder/article/details/7019435
http://distributeddatastore.blogspot.com/2013/08/cassandra-sstable-storage-format.html
 Packt.Real-time.Analytics.with.Storm.and.Cassandra.pdf
Packt.Real-time.Analytics.with.Storm.and.Cassandra.pdf
Cassandra_3.x_High_Availability,_2nd_Edition.pdf
使用Spark+Cassandra打造高性能数据分析平台(一)
Paper: http://www.read.seas.harvard.edu/~kohler/class/cs239-w08/decandia07dynamo.pdf
Start as root:
[388][u3][0][-bash](19:52:43)[0](root) : /usr/local/cassandra
$./bin/cassandra -R今天配置了一个cassandra集群:
create keyspace quant365 with \
replication ={'class':'SimpleStrategy','replication_factor':1};
use quant365;
CREATE TABLE IF NOT EXISTS words (word text PRIMARY KEY, count int);
TRUNCATE words;
INSERT INTO words(word, count) VALUES ('hadoop', 10);
INSERT INTO words(word, count) VALUES ('spark', 9);
SELECT * FROM words;Cassandra Architecture:
https://www.safaribooksonline.com/library/view/learning-apache-cassandra/9781787126190/video2_1.html
https://www.safaribooksonline.com/library/view/learning-apache-cassandra/9781787126190/video3_1.html
$cqlsh
Connected to HenryCassandra at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.1 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh> HELP
Documented shell commands:
===========================
CAPTURE CLS COPY DESCRIBE EXPAND LOGIN SERIAL SOURCE UNICODE
CLEAR CONSISTENCY DESC EXIT HELP PAGING SHOW TRACING
CQL help topics:
================
AGGREGATES CREATE_KEYSPACE DROP_TRIGGER TEXT
ALTER_KEYSPACE CREATE_MATERIALIZED_VIEW DROP_TYPE TIME
ALTER_MATERIALIZED_VIEW CREATE_ROLE DROP_USER TIMESTAMP
ALTER_TABLE CREATE_TABLE FUNCTIONS TRUNCATE
ALTER_TYPE CREATE_TRIGGER GRANT TYPES
ALTER_USER CREATE_TYPE INSERT UPDATE
APPLY CREATE_USER INSERT_JSON USE
ASCII DATE INT UUID
BATCH DELETE JSON
BEGIN DROP_AGGREGATE KEYWORDS
BLOB DROP_COLUMNFAMILY LIST_PERMISSIONS
BOOLEAN DROP_FUNCTION LIST_ROLES
COUNTER DROP_INDEX LIST_USERS
CREATE_AGGREGATE DROP_KEYSPACE PERMISSIONS
CREATE_COLUMNFAMILY DROP_MATERIALIZED_VIEW REVOKE
CREATE_FUNCTION DROP_ROLE SELECT
CREATE_INDEX DROP_TABLE SELECT_JSON
cqlsh> DESCRIBE CLUSTER;
Cluster: HenryCassandra
Partitioner: Murmur3Partitioner
cqlsh> 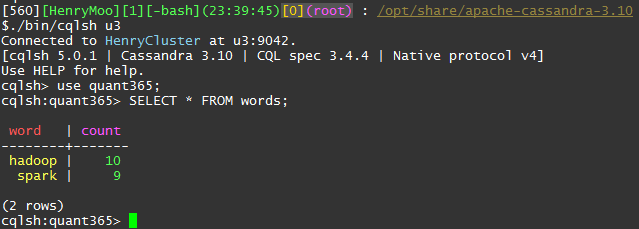
http://blog.csdn.net/limingjian/article/details/8836362
今天配置了Master,slave模式的cassandra.
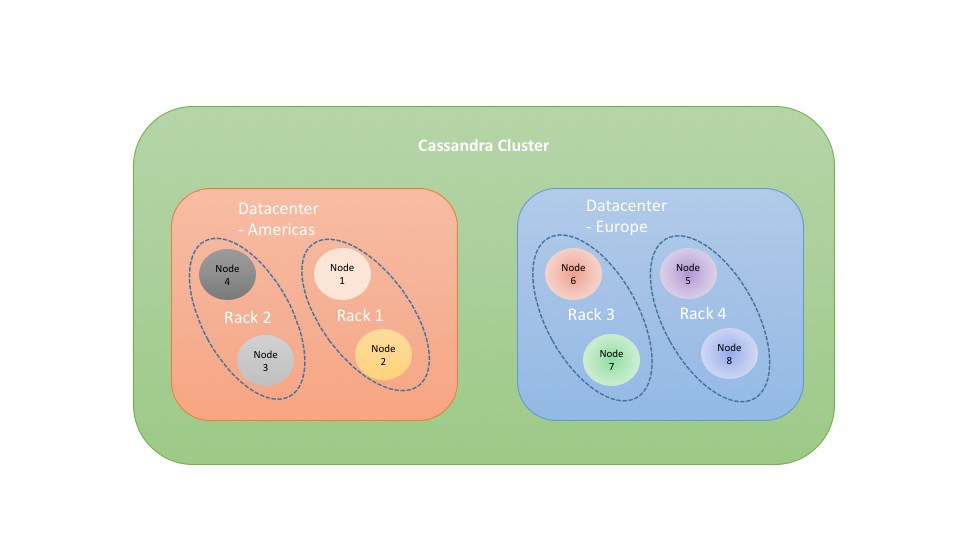
- Cassandra数据分布之1数据中心(DC)和机架(RACK)
http://blog.csdn.net/limingjian/article/details/8820841
https://github.com/datastax/spark-cassandra-connector
http://tangjiong.me/blog/bigdata/setup-cassandra-cluster
LSM Tree:
http://www.cnblogs.com/yanghuahui/p/3483754.html
http://www.cnblogs.com/siegfang/archive/2013/01/12/lsm-tree.html
从LSM-Tree、COLA-Tree谈到StackOverflow、OSQA: http://blog.csdn.net/v_JULY_v/article/details/7526689
Ansible:
[519][HenryMoo][22][-bash](00:17:07)[0](root) : /opt/share
$ansible cassandra -a "poweroff"
192.168.122.106 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh.",
"unreachable": true
}
192.168.122.105 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh.",
"unreachable": true
}
192.168.122.104 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh.",
"unreachable": true
}
192.168.122.103 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh.",
"unreachable": true
}22.3 Connection Pool
- BUILD
...
✔ /opt/share/cassandra_cpp_driver/build [master {origin/master}|✔]
08:00 # ll
total 8100
drwxr-xr-x 4 root root 4096 Feb 10 08:00 ./
drwxr-xr-x 13 root root 4096 Feb 10 07:57 ../
-rw-r--r-- 1 root root 281 Feb 10 07:57 cassandra.pc
-rw-r--r-- 1 root root 18748 Feb 10 07:58 CMakeCache.txt
drwxr-xr-x 7 root root 4096 Feb 10 08:00 CMakeFiles/
-rw-r--r-- 1 root root 3349 Feb 10 07:58 cmake_install.cmake
-rw-r--r-- 1 root root 1082 Feb 10 07:57 cmake_uninstall.cmake
-rw-r--r-- 1 root root 54608 Feb 10 07:58 compile_commands.json
-rw-r--r-- 1 root root 3650 Feb 10 07:57 CPackConfig.cmake
-rw-r--r-- 1 root root 4114 Feb 10 07:57 CPackSourceConfig.cmake
lrwxrwxrwx 1 root root 17 Feb 10 08:00 libcassandra.so -> libcassandra.so.2*
lrwxrwxrwx 1 root root 21 Feb 10 08:00 libcassandra.so.2 -> libcassandra.so.2.8.0*
-rwxr-xr-x 1 root root 8097304 Feb 10 08:00 libcassandra.so.2.8.0*
-rw-r--r-- 1 root root 74609 Feb 10 07:58 Makefile
drwxr-xr-x 3 root root 4096 Feb 10 07:57 src/
✔ /opt/share/cassandra_cpp_driver/build [master {origin/master}|✔]
08:00 # make install
[100%] Built target cassandra
Install the project...
-- Install configuration: ""
-- Installing: /usr/local/include/cassandra.h
-- Installing: /usr/local/lib/x86_64-linux-gnu/libcassandra.so.2.8.0
-- Installing: /usr/local/lib/x86_64-linux-gnu/libcassandra.so.2
-- Installing: /usr/local/lib/x86_64-linux-gnu/libcassandra.so
-- Installing: /usr/local/lib/x86_64-linux-gnu/pkgconfig/cassandra.pc- TEST
check cassandra_test.cpp
Build it with:
g++ cassandra_test.cpp -L /usr/local/lib/x86_64-linux-gnu/ \
-lcassandra -o cassandra_test- Python
08:38 # pip install cassandra-driver
Collecting cassandra-driver
Downloading cassandra-driver-3.13.0.tar.gz (224kB)
100% |████████████████████████████████| 225kB 3.8MB/s
Requirement already satisfied: six>=1.9 in /opt/share/software/hue/build/env/lib/python2.7/site-packages (from cassandra-driver)
Requirement already satisfied: futures in /usr/local/lib/python2.7/dist-packages (from cassandra-driver)
Building wheels for collected packages: cassandra-driver
Running setup.py bdist_wheel for cassandra-driver ... done
Stored in directory: /root/.cache/pip/wheels/15/5b/21/6dadc8f77b408b21f7047f40d79f94b02e6973fff6da427972
Successfully built cassandra-driver
Installing collected packages: cassandra-driver
Successfully installed cassandra-driver-3.13.0https://docs.datastax.com/en/drivers/python/3.4/getting_started.html
22.4 为什么 Cassandra 的写速度比 MySQL 快?
https://www.zhihu.com/question/19553452
- 异步写,先写commit log,然后异步(memtable 满后)到磁盘
- 顺序写,无论是commit log,sstable,都是顺序写
- 只添加不更新删除,数据用版本号和删除标识来确定最新状态,这个也是为什么sstable能够顺序写的根本.磁盘文件的定期重整,回收垃圾版本.
- cassandra没有sql解析层,这是个大块
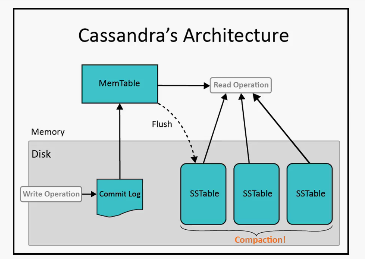
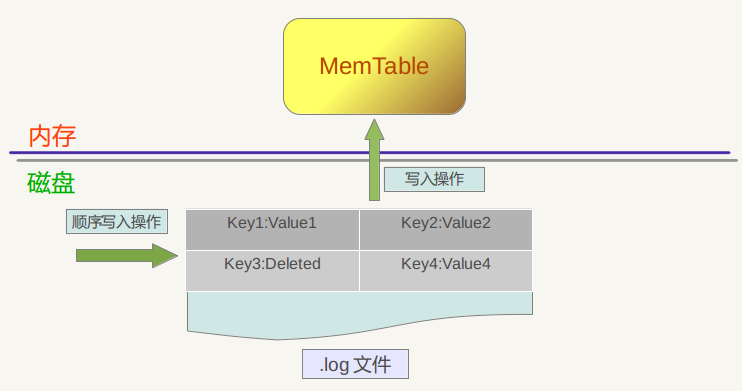
Commit Log tracks every write operation into the system. The aim of the commit log is to be able to successfully recover data that was not stored to disk via the Memtable.
22.5 Data Model
- How the data are organizaed?
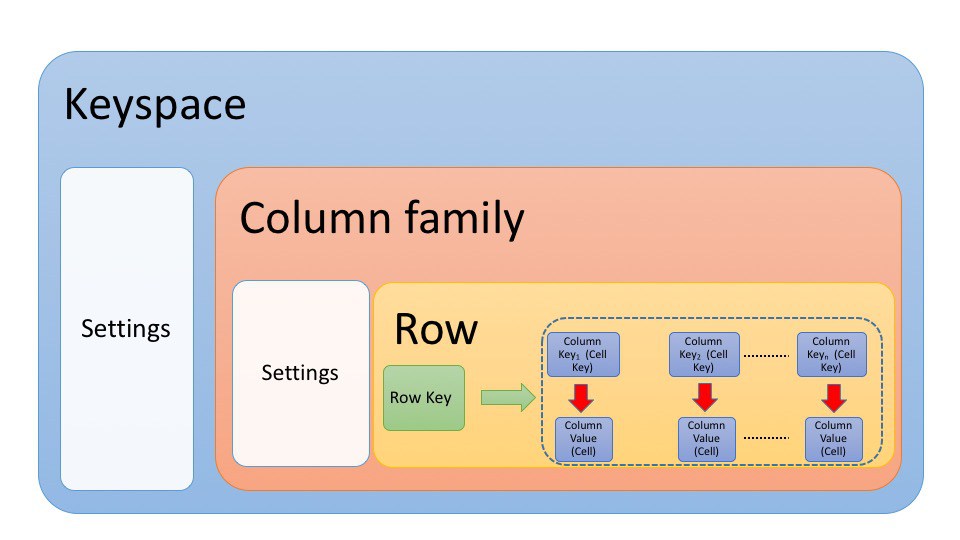
From: http://rene-ace.com/cassandra-101-understanding-what-is-cassandra/
22.6 LSM Tree, Skiplist, Memtable, SSTable
在 key-value store 中 Log-Structured Merge-Trees (LSM-trees) 应用得相当广泛.与其他的索引结构(如B-tree)相比,LSM-trees 的主要优点是能够维持顺序的写操作.在B树中小的更新会带来较多的随机写,为了提高性能,LSM-trees 可以批量处理 key-value 对,然后将他们顺序写入.
一个 LSM-tree 由一些大小成倍增加的小组件组成.如下图所示,C0层是驻留内存的原地更新的排序树,其他的层 C1-Cn 是驻留磁盘的只允许插入的B树.
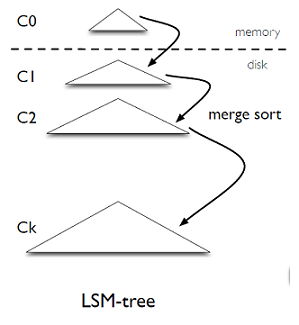
当插入一个 key-value 对到 LSM tree 中时,首先将其添加到磁盘的日志文件中用以在崩溃情况下的恢复.然后 key-value 对会被添加到内存中的 C0 中,且 C0 是有序的.一旦 C0 的大小达到一个限制值后,它会和磁盘上的 C1 数据利用归并算法进行有序地合并.新的合并的树会替代原来版本的 C1 并顺序地写到磁盘上.当磁盘上的 C1-Cn 中的任意一层的大小达到限制值时,都会进行类似的合并操作.合并的操作只能发生在相邻的层之间,并且他们可以在后台异步进行.

22.9 Data structure: DHT, Bloomfilter, Merkle Tree, Btree, HyperLogLog
 https://github.com/shadowwalker2718/cassandra/tree/3.11-dev/src/java/org/apache/cassandra
https://github.com/shadowwalker2718/cassandra/tree/3.11-dev/src/java/org/apache/cassandra
✔ /opt/share/git_cassandra [cassandra-3.11 {origin/cassandra-3.11}|✚ 3]
11:59 # git checkout -b 3.11-dev
M src/java/org/apache/cassandra/db/Memtable.java
M src/java/org/apache/cassandra/utils/BloomFilter.java
M src/java/org/apache/cassandra/utils/MerkleTrees.java
Switched to a new branch '3.11-dev'
22.12 Follow up
High performance server-side application framework: https://github.com/scylladb/seastar
C++ version: https://github.com/scylladb/scylla
22.13 LevelDB
https://github.com/google/leveldb
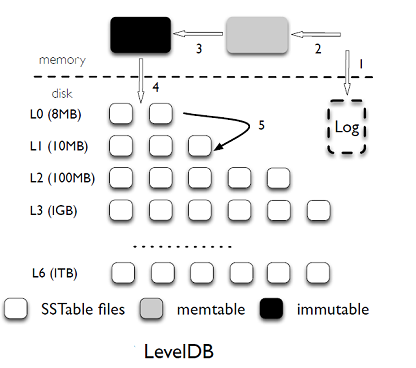
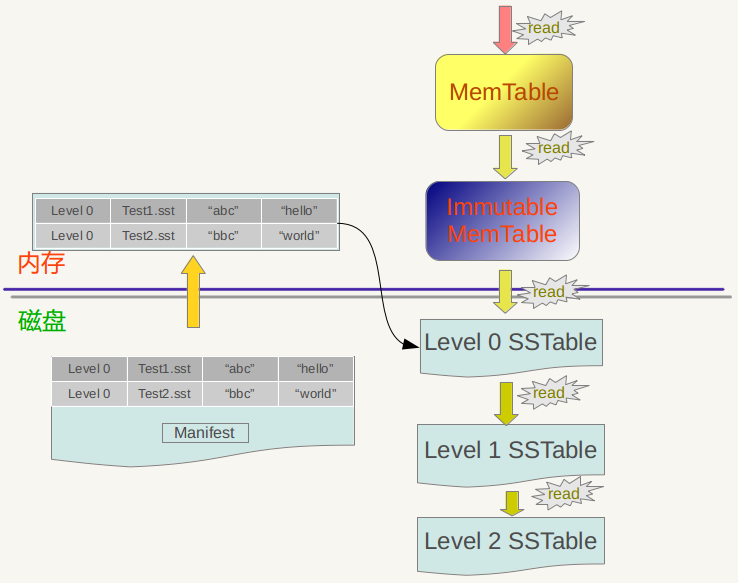
LevelDB 主要的数据结构是:磁盘上的日志文件,内存上的两个有序的跳表(memtable 和 immutable memtable) 和存储在磁盘上的7层的有序的字符串表(SSTable)文件.
- 写操作
当应用写入一条 key-value 记录的时候,LevelDB 会先往磁盘上的日志文件里写入,成功后将记录插进内存中的 memtable 中,这样基本就算完成了写入操作,因为一次写入操作只涉及一次磁盘顺序写和一次内存写入,这是 LevelDB写入速度极快的主要原因.
一旦 memtable 满了之后,LevelDB 会生成新的 memtable 和日志文件来处理用户接下来的请求.在后台,之前的 memtable 被转换成 immutable memtable,顾名思义,就是说这个 memtable 的内容是不可更改的,只能读不能写入或者删除,一个合并的线程会将它里面的内容刷新到磁盘上,产生一个大约 2M 大小的 SSTable 文件,并将其放在 level 0 层.同时,以前的日志文件将会被丢弃.
- 合并
每一层所有文件的大小是有限制的,大约是以10倍依次递增.当某一层的总大小超过了它的限制时,合并线程就会从该层选择一个文件将其和下一层的所有重叠的文件进行归并排序产生一个新的 SSTable 文件放在下一层中.合并线程会一直运行下去直到所有层的大小都在规定的限制内.当然,在合并的过程中,LevelDB 会保持除 level 0 之外的每一层上的所有文件的 key 的范围不会重叠,L0 层上文件的 key 的范围是可以重复的,因为它是直接从 memtable 上刷新过来的.
- 查找操作
对于查询操作,LevelDB 首先会查询 memtable,接下来是 immutable memtable,然后依次查询 L0-L6 中每一层的文件.确定一个随机的 key 的位置而需要搜索文件的次数的上界是由最大的层数来决定的,因为除了L0之外,每一层的所有文件中key的范围都是没有重叠的. 由于L0中文件的key的范围是有重叠的,所以在L0中进行查询时,可能会查询多个文件.为了降低查询操作的延迟,当L0层的文件数量超过8时,LevelDB 就会降低前台写操作的速度,这是为了等待合并线程将L0中的文件合并到L1中.
- 写放大
LevelDB 中的写放大是很严重的.假如,每一层的大小是上一层的10倍,那么当把 i-1 层中的一个文件合并到 i 层中时,LevelDB 需要读取 i 层中的文件的数量多达10个,排序后再将他们写回到 i 层中去.所以这个时候的写放大是10.对于一个很大的数据集,生成一个新的 table 文件可能会导致 L0-L6 中相邻层之间发生合并操作,这个时候的写放大就是50(L1-L6中每一层是10).
- 读放大
LevelDB 中的读放大也是一个主要的问题.读放大主要来源于两方面:
查找一个 key-value 对时,LevelDB 可能需要在多个层中去查找.在最坏的情况下,LevelDB 在 L0 中需要查找8个文件,在 L1-L6 每层中需要查找1个文件,累计就需要查找14个文件.
在一个 SSTable 文件中查找一个 key-value 对时,LevelDB 需要读取该文件的多个元数据块.所以实际读取的数据量应该是:index block + bloom-filter blocks + data block.例如,当查找 1KB 的 key-value 对时,LevelDB 需要读取 16KB 的 index block,4KB的 bloom-filter block 和 4KB 的 data block,总共要读取 24 KB 的数据.在最差的情况下需要读取 14 个 SSTable 文件,所以这个时候的写放大就是 24*14=336.较小的 key-value 对会带来更高的读放大.
Good read: http://cighao.com/2016/08/14/leveldb-source-analysis-02-structure/
https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
22.14 MongoDB
A monotonically increasing shard key (such as the date or an ObjectID) will guarantee that all inserts go into a single shard, thus creating a hot shard and limiting your ability to scale write load. There are other ways that you can create a hot shard, but using a monotonically increasing shard key is by far the most common mistake I’ve seen.
22.15 MySQL and MariaDB
https://mariadb.com/kb/en/mariadb/mariadb-vs-mysql-features/
https://mariadb.com/kb/en/mariadb/oqgraph-storage-engine/
22.16 Transaction
https://www.postgresql.org/docs/current/static/sql-prepare-transaction.html
https://www.citusdata.com/blog/2017/11/22/how-citus-executes-distributed-transactions/
2016(10-12月) 码农类General 硕士 全职Addepar - 校园招聘会 - 技术电面 Onsite | Fail | fresh grad应届毕业生
16年12月onsite的Addepar NYC office.
这家据说湾区office的bar很高,但是似乎NYC的低一点.公司做fintech,创始人是Palantir的co-founder
第一轮 on-campus career fair: 铅笔+白纸写题,一道字符串的backtracking + 一道字符串的iterator(用26进制做)
第二轮 电面:一道交易相关的题,本质是实现nosql 2-phase commit, 支持rollback
onsite#1 : 设计Google Calendar,讨论design.
onsite#2 : 上机debugging,应该是挂在这轮了.最后的bug不在client代码里,而是依赖的JSON parser的token有问题
onsite#3 : 一道交易相关的题,没有算法,按照要求模拟就可以,大概用hash存一些信息.
onsite#4 : manager behavior 问题 + subsets.http://www.jasongj.com/big_data/two_phase_commit/
二阶段提交的算法思路可以概括为:协调者询问参与者是否准备好了提交,并根据所有参与者的反馈情况决定向所有参与者发送commit或者rollback指令(协调者向所有参与者发送相同的指令).
所谓的两个阶段是指
准备阶段 又称投票阶段.在这一阶段,协调者询问所有参与者是否准备好提交,参与者如果已经准备好提交则回复Prepared,否则回复Non-Prepared.
提交阶段 又称执行阶段.协调者如果在上一阶段收到所有参与者回复的Prepared,则在此阶段向所有参与者发送commit指令,所有参与者立即执行commit操作;否则协调者向所有参与者发送rollback指令,参与者立即执行rollback操作.两阶段提交中,协调者和参与方的交互过程如下图所示. Two-phase commit 两阶段提交前提条件
网络通信是可信的.虽然网络并不可靠,但两阶段提交的主要目标并不是解决诸如拜占庭问题的网络问题.同时两阶段提交的主要网络通信危险期(In-doubt Time)在事务提交阶段,而该阶段非常短.
所有crash的节点最终都会恢复,不会一直处于crash状态.
每个分布式事务参与方都有WAL日志,并且该日志存于稳定的存储上.
各节点上的本地事务状态即使碰到机器crash都可从WAL日志上恢复.两阶段提交容错方式
两阶段提交中的异常主要分为如下三种情况
协调者正常,参与方crash
协调者crash,参与者正常
协调者和参与方都crash对于第一种情况,若参与方在准备阶段crash,则协调者收不到Prepared回复,协调方不会发送commit命令,事务不会真正提交.若参与方在提交阶段提交,当它恢复后可以通过从其它参与方或者协调方获取事务是否应该提交,并作出相应的响应.
第二种情况,可以通过选出新的协调者解决.
第三种情况,是两阶段提交无法完美解决的情况.尤其是当协调者发送出commit命令后,唯一收到commit命令的参与者也crash,此时其它参与方不能从协调者和已经crash的参与者那儿了解事务提交状态.但如同上一节两阶段提交前提条件所述,两阶段提交的前提条件之一是所有crash的节点最终都会恢复,所以当收到commit的参与方恢复后,其它节点可从它那里获取事务状态并作出相应操作.