Chapter 18 Design A Payment System
Design a scalable, reliable payment service which could be used by your company to process payment, it could read the account info and payment info from the user and make payment. Source of truth ledger system, reduce the total number of transactions(1-2% fee per transaction)
Pay per transaction: From rider to Uber
- Paid per-transaction: Amazon
- Paid post-transaction: Uber trip
Schedule batched monthly payment: pay to driver
18.1 Feature Requirements
18.1.1 Post-transaction: uber trip
- Account balance (uber credit), account info: saved payment methods (credit numbers, bank account, etc)
- Currency, localization? (USD, global: multiple dc across multiple regions)
- User has multiple accounts
18.1.2 Scheduled/Batch payments
- Monthly (configrable, hard-code is fine)
- Batch several accounts in one payment request?
- One account scheduled per month
Additionally, payment transaction to bank latency could be ~ 1 sec level.
18.1.3 What could go wrong:
- Lack of payment
No sufficient fund (bank denied it)
- Double spending/payout
Charge twice (it’s not you use the same money to pay for two things)
correctness/at-least-one transaction
- Incorrect currency conversion
n/a
- Dangling authorization
Don’t worry about auth, not client side auth?
Auth to the payment system
Auth from bank
PSP auth (username/password pass to bank)
- Incorrect payment
Discrepancy from downstream services??
- Incompatible IDs(only temporarily unique)
Idempotency key? Diff id system (tmp unique)
- 3rd party PSP outage
Any downstream service outages
- Data discrepancy of charges from stripes / braintree
Same as incorrect payment
18.2 10 mins: Constraints/SLA
- Scalable: 30M transaction per day = 300 QPS; peak: 10 times more = 3K QPS
- Durable: hardware/software failures
- Fault-tolerant: any part of the system goes down/failures
- Consistency: Strong consistency.
- Availability: 99.999% (5 mins downtime/year) –> Five 9, which is 5 mins per year
- Latency: p99. SLA < 200 ms for others
PSP: payment service provider.
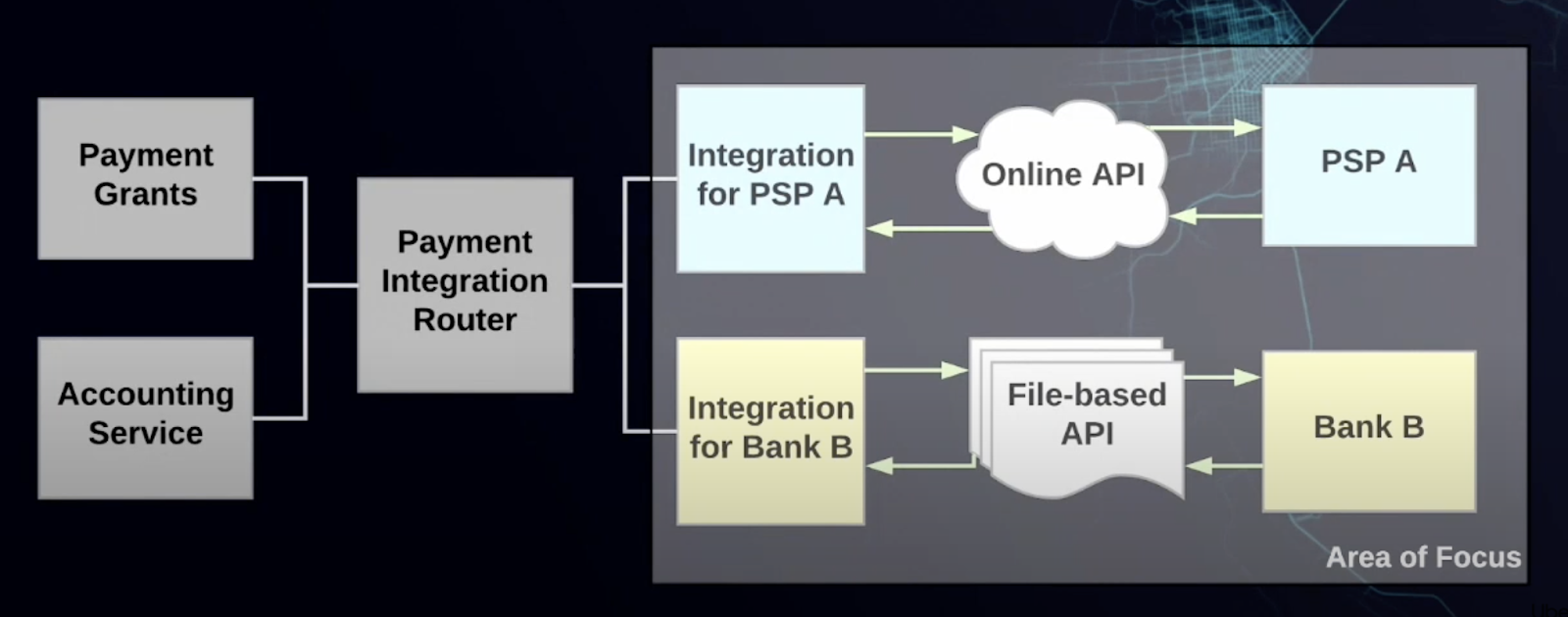
18.3 10 mins: High Level Architecture
Client (mobile/web) end trip -> frontend webservice —emit–> trip end event –async–> payment service -> downstream service (PSP, bank, credit cards, etc.)
- retry and de-duplication with idempotent API
Request: idempotent key (UUID, deterministic id), status: success/failure (retryable/non-retryable)
Request Life Cycle
- Trip end event from event queue (durable), AWS SQS (at-least-once delivery)
- only one worker work on the same event
- If the worker failed/timeout, the event would go back to the queue to be picked up by another worker
- If it failed for configurable times, it goes to DLQ
- Scale up workers for past processing
- Backend Worker pull event from queue (eventid as idempotent key)
Db record: Idempotentkey, status (success/retryable_failure/non-retryable_failure) Missing: queued / running? Serve 1 -> req A → failed.
Prepare (db row-level lock on the idempotent key, lease expiry): expiry time: Configurable value > max downstream processing time
Get or create an entry in db
If the entry in db with status finished, return
If the entry in db with status (retryable) or the entry doesn’t exist, we need to continue process
Process: talk to downstream services (PSP, bank) for the actual money transfer
Async, circuit break (fail fast), retry (exponentially back off retry )
After we get response back, we need to update the db record
First update the status to either success/failure (5xx retryable failure, 4xx non-retryable failures)
Release the lock on the idempotent key
Delete that event from queue
Scenario 1: Serve 1 -> req A locked → server 1 crashed —> will not deadlock. lock have expiration: need process to restart
Queue: send and forget (at least once process)
SQS message end of lifecycle stop when the process is fully done
MQ / Kafka end of life cycle is the consume the message
Backend process to restart
Scenario 2: expirable time 5 mins.
Serve1 -> Row 1 lock —-> stop the world GC—more than 5 mins–> W
Server 2-> row1 lock -> W data —X
Scenario 3: worker process payment actually went through, didn’t go back to SQS.
Failed to write to DB as success:
Retry -> idempotent -> no side effect
Failed to delete the event
Next worker gets the event, and check db and saw it’s already finished, do nothing and return
Distributed locking: id (monotonically increment id), server1 request with id: 10, server2 request with id: 11, when server1 goes back online, trying to commit, it can see it’s id is invalid (abort that transaction)
After processing finished, bookkeeping for audit/data analysis purpose
Save transaction history, bookkeeping datas (money in/out for each account)
Sweep process to cleanup/purge the tables (delete rows that are 1 year old)
18.6 10 mins: DB choice
1 Row – 10K
30 M per day —> 300 GB per day * 180 -> 50 TB = 100 DB instance (500 GB per instance)
Sharding based on transaction key - trip id → cross shard transaction
SQL (ACID, transaction): account, request tables (purge every 6 months)
No-SQL: transaction_history, bookkeeping tables