Chapter 28 Pinot and Druid
https://github.com/linkedin/pinot/issues/3
Fundamentally Druid and Pinot are
realtime distributed OLAPtechnologies. They both usecolumnar formatfor storage and aquery processing engineon top. They differ in some integration aspects with other pieces of big data. For example in LinkedIn we run Pinot at a large scale (1000s of machines and 100s of tables). Pinot can directly consume data from Kafka and also from Hadoop. I cannot comment about Druid as I do not know their install base. There are a few features that might be missing in one and available in other and vice versa. Also, recently LinkedIn team has decided to make all their commits directly into open source. So any future development we do will land in open source immediately. There You will be getting the latest and greatest version all the time. From what I hearUberis also using Pinot for their internal analytics. So your choice of technology will depend on the comfort levels. If I can find more details about DRUID installations I will be happy to share. That being said, I have a bias towards recommending Pinot as my team is actively working on it on a day to day basis. We will be happy to support your projects in the open source community.
28.1 Pinot
https://github.com/linkedin/pinot
注意安装需要jdk.
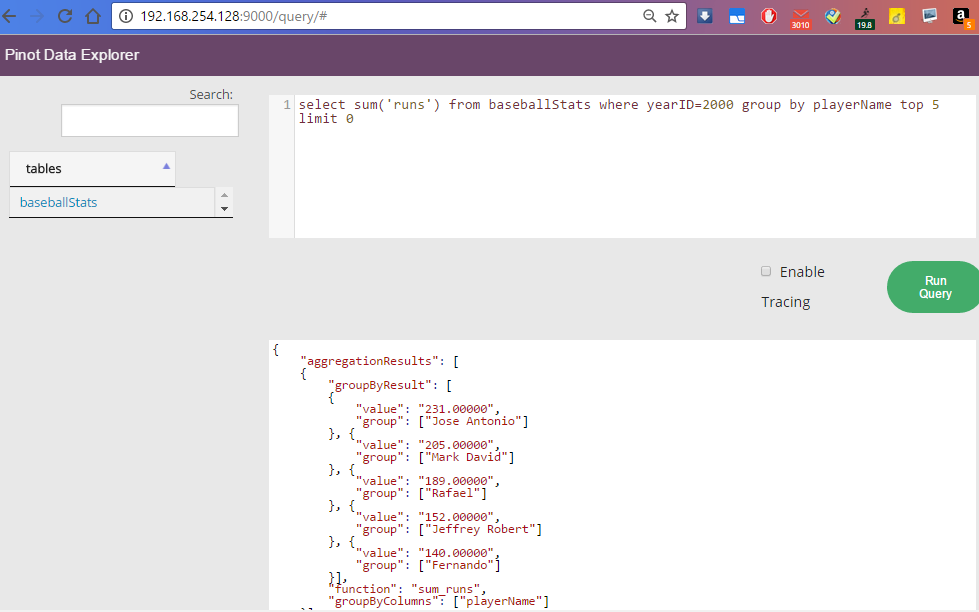
https://github.com/linkedin/pinot/wiki/Architecture
在我的DO的2G内存machine上面跑得到OOM的错误:
[INFO] pinot .............................................. SUCCESS [ 5.826 s]
[INFO] pinot-common ....................................... SUCCESS [ 16.795 s]
[INFO] pinot-transport .................................... SUCCESS [ 13.451 s]
[INFO] pinot-core ......................................... SUCCESS [ 17.820 s]
[INFO] pinot-server ....................................... SUCCESS [ 24.343 s]
[INFO] pinot-controller ................................... SUCCESS [ 20.830 s]
[INFO] pinot-broker ....................................... SUCCESS [ 20.697 s]
[INFO] pinot-api .......................................... SUCCESS [ 1.248 s]
[INFO] pinot-hadoop ....................................... SUCCESS [ 18.473 s]
[INFO] pinot-tools ........................................ FAILURE [ 50.920 s]
[INFO] pinot-integration-tests ............................ SKIPPED
[INFO] pinot-perf ......................................... SKIPPED
[INFO] pinot-distribution ................................. SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 03:10 min
[INFO] Finished at: 2017-02-11T07:44:05-05:00
[INFO] Final Memory: 234M/446M
[INFO] ------------------------------------------------------------------------
[ERROR] GC overhead limit exceeded -> [Help 1]
java.lang.OutOfMemoryError: GC overhead limit exceeded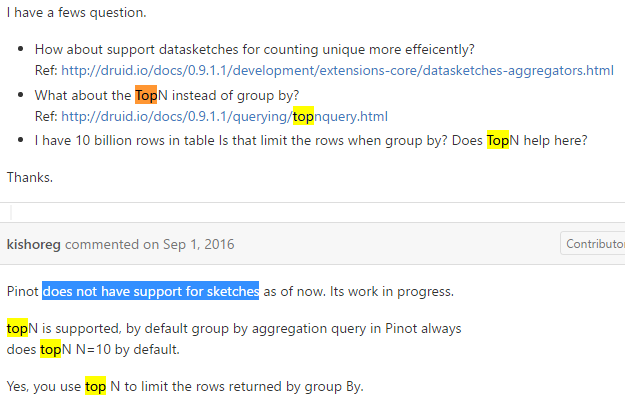
28.2 Druid
https://github.com/druid-io/druid
TopN Query:
https://groups.google.com/forum/#!topic/druid-development/jMHz_DoeL9g
- Aliasing TopN
The current TopN algorithm is an approximate algorithm. The top 1000 local results from each segment are returned for merging to determine the global topN. As such, the topN algorithm is approximate in both rank and results. Approximate results ONLY APPLY WHEN THERE ARE MORE THAN 1000 DIM VALUES. A topN over a dimension with fewer than 1000 unique dimension values can be considered accurate in rank and accurate in aggregates.
- DataSketches aggregator
http://druid.io/docs/0.9.1.1/development/extensions-core/datasketches-aggregators.html
https://datasketches.github.io/
很好的案例: https://datasketches.github.io/docs/TheChallenge.html
Here is a very fundamental business question: “Do you really need 10+ digits of accuracy in the answers to your queries? This leads to the fundamental premise of this entire branch of Computer Science:
If an approximate answer is acceptable, then it is possible that there exists algorithms that allow you to answer these queries orders-of-magnitude faster.Stochastic Streaming Algorithms
Sketch的来历: https://datasketches.github.io/docs/SketchOrigins.html