Chapter 7 System Design 2
7.1 Memory Pool
是application track. 就给你一块内存,不让用额外空间,实现内存池功能,allocate(int size),free(void*)
http://www.cnblogs.com/dylantsou/archive/2012/05/13/2498491.html
http://www.ibm.com/developerworks/cn/linux/l-cn-ppp/index6.html
https://www.codeproject.com/articles/27487/why-to-use-memory-pool-and-how-to-implement-it
http://www.cnblogs.com/bangerlee/archive/2011/08/31/2161421.html
http://www.cnblogs.com/bangerlee/archive/2011/09/01/2161437.html
http://blog.csdn.net/liygcheng/article/details/17621993
https://github.com/tboox/tbox/wiki/%E5%86%85%E5%AD%98%E6%B1%A0%E6%9E%B6%E6%9E%84
1.什么是内存池技术及为什么要设计自己的内存池?
通常我们习惯直接使用new、malloc等API申请分配内存,这样做的缺点在于:由于所申请内存块的大小不定, 当频繁使用时会造成大量的内存碎片并进而降低性能.C/C++的内存分配(通过malloc或new)可能需要花费很多时.更糟糕的是,随着时间的流逝,内存(memory)将形成碎片,所以一个应用程序的运行会越来越慢当它运行了很长时间和/或执行了很多的内存分配(释放)操作的时候.特别是,你经常申请很小的一块内存,堆(heap)会变成碎片的,这就是为什么我们经常在运行自己的C/C++程序时一开始还好好的,可是越到后面速度越慢,最后甚至直接罢工了.
而对于以上,一个可行的的解决方案就是设计一个自己的内存分配策略,也即设计一个你自己的内存池.内存池(Memory Pool)是一种内存分配方式.
内存池则是在真正使用内存之前,先申请分配一定数量的、大小相等(一般情况下)的内存块留作备用.当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续申请新的内存.这样做的一个显著优点是尽量避免了内存碎片,使得内存分配效率得到提升.在启动的时候,一个”内存池”(Memory Pool)分配一块很大的内存,并将会将这个大块(block)分成较小的块(smaller chunks).每次你从内存池申请内存空间时,它会从先前已经分配的块(chunks)中得到,而不是从操作系统.
最大的优势在于:
1.非常少(几没有) 堆碎片
2.比通常的内存申请/释放(比如通过malloc, new等)的方式快
3.检查任何一个指针是否在内存池里
4.写一个"堆转储(Heap-Dump)"到你的硬盘(对事后的调试非常有用)
5.某种"内存泄漏检测(memory-leak detection)":当你没有释放所有以前分配的内存时,内存池(Memory Pool)会抛出一个断言(assertion).2.目前有哪些优秀的内存池技术
1.固定大小缓冲池
代码很简单,如下:
template<typename T>
class CMemoryPool{
enum { EXPANSION_SIZE = 32};
CMemoryPool(unsigned int nItemCount = EXPANSION_SIZE){
ExpandFreeList(nItemCount);
}
~CMemoryPool(){
//free all memory in the list
CMemoryPool<T>* pNext = NULL;
for(pNext = m_pFreeList; pNext != NULL; pNext = m_pFreeList){
m_pFreeList = m_pFreeList->m_pFreeList;
delete [](char*)pNext;
}
}
void* Alloc(unsigned int /*size*/){
if(m_pFreeList == NULL)
ExpandFreeList();
//get free memory from head
CMemoryPool<T>* pHead = m_pFreeList;
m_pFreeList = m_pFreeList->m_pFreeList;
return pHead;
}
void Free(void* p){ //push the free memory back to list
CMemoryPool<T>* pHead = static_cast<CMemoryPool<T>*>(p);
pHead->m_pFreeList = m_pFreeList;
m_pFreeList = pHead;
}
protected:
//allocate memory and push to the list
void ExpandFreeList(unsigned nItemCount = EXPANSION_SIZE){
unsigned int nSize = sizeof(T) > sizeof(CMemoryPool<T>*) ? sizeof(T) : of(CMemoryPool<T>*);
CMemoryPool<T>* pLastItem = static_cast<CMemoryPool<T>*>(static_cast<void*>(new [nSize]));
m_pFreeList = pLastItem;
for(int i=0; i<nItemCount-1; ++i) {
pLastItem->m_pFreeList = static_cast<CMemoryPool<T>*>(static_cast<void*>(new [nSize]));
pLastItem = pLastItem->m_pFreeList;
}
pLastItem->m_pFreeList = NULL;
}
private:
CMemoryPool<T>* m_pFreeList;
};它的实现思想就是每次从List的头上取内存, 如果取不到则重新分配一定数量. 用完后把内存放回List头部,这样的话效率很高,因为每次List上可以取到的话,肯定是空闲的内存.当然上面的代码只是针对单线程的,要支持多线程的话也很简单,外面加一层就可以了,代码如下:
class CCriticalSection{
CCriticalSection(){
InitializeCriticalSection(&m_cs);
}
~CCriticalSection(){
DeleteCriticalSection(&m_cs);
}
void Lock(){
EnterCriticalSection(&m_cs);
}
void Unlock(){
LeaveCriticalSection(&m_cs);
}
protected:
CRITICAL_SECTION m_cs;
};
template<typename POOLTYPE, typename LOCKTYPE>
class CMTMemoryPool{
void* Alloc(unsigned int size){
void* p = NULL;
m_lock.Lock();
p = m_pool.Alloc(size);
m_lock.Unlock();
return p;
}
void Free(void* p){
m_lock.Lock();
m_pool.Free(p);
m_lock.Unlock();
}
private:
POOLTYPE m_pool;
LOCKTYPE m_lock;
};2.dlmalloc
应该来说相当优秀的内存池, 支持大对象和小对象,并且已被广泛使用.到这里下载:ftp://g.oswego.edu/pub/misc/malloc.c关于dlmalloc的内部原理和使用资料可以参考:内存分配器dlmalloc 2.8.3源码浅析.doc
3.SGI STL 中的内存分配器( allocator )
SGI STL 的 allocator 应该是目前设计最优秀的 C++ 内存分配器之一了,它的运作原理候捷老师在《 STL 源码剖析》里讲解得非常清楚.基本思路是设计一个 free_list[16]数组,负责管理从 8 bytes 到 128 bytes 不同大小的内存块( chunk ),每一个内存块都由连续的固定大小( fixed size block )的很多 chunk 组成,并用指针链表串接起来.
比如说
free_list[3]->start_notuse->next_notuse->next_notuse->...->end_notuse;
当用户要获取此大小的内存时,就在 free_list 的链表找一个最近的 free chunk 回传给用户,同时将此 chunk 从 free_list 里删除,即把此 chunk 前后chunk 指针链结起来.用户使用完释放的时候,则把此chunk 放回到 free_list 中,应该是放到最前面的 start_free 的位置.这样经过若干次 allocator 和 deallocator 后, free_list 中的链表可能并不像初始的时候那么是 chunk 按内存分布位置依次链接的.假如free_list 中不够时, allocator 会自动再分配一块新的较大的内存区块来加入到 free_list 链表中. 可以自动管理多种不同大小内存块并可以自动增长的内存池,这是 SGI STL 分配器设计的特点.
4.Loki 中的小对象分配器( small object allocator )
Loki 的分配器与 SGI STL 的原理类似,不同之处是它管理 free_list 不是固定大小的数组,而是用一个 vector 来实现,因此可以用户指定 fixed size block 的大小,不像 SGI STL 是固定最大 128 bytes 的.另外它管理 free chunks 的方式也不太一样, Loki 是由一列记录了 free block 位置等信息的 Chunk 类的链表来维护的,free blocks 则是分布在另外一个连续的大内存区间中.而且 free Chunks 也可以根据使用情况自动增长和减少合适的数目,避免内存分配得过多或者过少.
5.Boost 的 object_pool
Boost 中的 object_pool 也是一个可以根据用户具体应用类的大小来分配内存块的,也是通过维护一个 free nodes 的链表来管理的.可以自动增加 nodes 块,初始是 32 个 nodes ,每次增加都以两倍数向 system heap 要内存块. object_pool 管理的内存块需要在其对象销毁的时候才返还给 system heap. http://www.boost.org/doc/libs/1_65_1/libs/pool/doc/html/boost_pool/pool/pooling.html#boost_pool.pool.pooling.simple
6.ACE 中的 ACE_Cached_Allocator 和 ACE_Free_List
ACE 框架中也有一个可以维护固定大小的内存块的分配器,原理与上面讲的内存池都差不多.它是通过在 ACE_Cached_Allocator 中定义个 Free_list 链表来管理一个连续的大内存块的,里面包含很多小的固定大小的未使用的区块( free chunk ),同时还使用 ACE_unbounded_Set 维护一个已使用的 chuncks ,管理方式与上面讲的内存池类似.也可以指定 chunks 的数目,也可以自动增长,定义大致如下所示:
template<class T>
class ACE_Cached_Allocator : public ACE_New_Allocator<T> {
// Create a cached memory pool with @a n_chunks chunks
// each with sizeof (TYPE) size.
ACE_Cached_Allocator(SIZET n_chunks = ACE_DEFAULT_INIT_CHUNKS);
T* allocate();
void deallocate(T* p);
private:
// List of memory that we have allocated.
Fast_Unbounded_Set<char *> _allocated_chunks;
// Maintain a cached memory free list.
ACE_Cached_Free_List<ACE_Cached_Mem_Pool_Node<T> > _free_list;
};7.TCMalloc
Google的开源项目gperftools, 主页在这里:https://code.google.com/p/gperftools/,该内存池也被大家广泛好评,并且在google的各种开源项目中被使用, 比如webkit就用到了它.
7.2 Object Pool
NOTE: This is actually a memory pool!!!
手动实现一个对象池.要求如下:
- Write high performance, concurrent implementation of the object pool for objects of various types using C++03 , C++ 11 (or C++ 14).
The minimal pool declaration is shown below; feel free to add any additional methods/members.
template<std::size_t MAX_OBJ_SIZE>
class pool ...{
pool (std::size_t maxCapacity, std::size_t minCapacity);
template<typename OBJECT, typename ...ARGS>
void alloc (std::shared_ptr<OBJECT> & object, ARGS ...args);
...
};Additional assumptions/requirements:
1.1. All object sizes are assumed to be less than a certain unknown threshold (see MAX_OBJ_SIZE) that will be provided later. Upon creation pool capacity should be
1.2. Objects will be allocated by calling
1.3. Once object is allocated, its life scope is fully controlled by the shared pointer(s) containing the object. When the last of them goes out of scope, the object should be deleted and the memory allocated for the object should be automatically reclaimed by the pool. As in 1.2, object destruction may happen on any thread, not necessarily on the same thread that called
1.4. Allocations/deallocations from the pool happen on the very latency sensitive threads and therefore have to be as fast as possible.
- Using pool implementation from 1, write a test application that measures min/avg/max allocation/deallocation latency for some test POD object of size 100 bytes under various runtime conditions, e.g. when used concurrently by 1 or more threads, when allocation and deallocation happen on the same thread or different threads, etc., and outputs the measurements to std::cout. All necessary runtime parameters, e.g. thread count, maxCapacity, minCapacity, etc., should be specified on the command line.
注意对象要内存对齐.
这个函数8*ceil(MAX_OBJ_SIZE/8.)可以改成#defineAPR_ALIGN(size, boundary) (((size)+ ((boundary) - 1)) &~((boundary) - 1)).该宏所做的无非就是计算出最接近size的boundary的整数倍的整数.通常情况下size大小为整数即可,而boundary则必须保证为2的幂.比如APR_ALIGN(7,4)为8;APR_ALIGN(21,8)为24;APR_ALIGN(21,16)则为32.
/*
1. Memory Layout
heads
____________|________________
| | |
[head1] [head2] [headN]
[.....] [.....] ... [.....]
subpool1 subpool2 subpoolN
2. freelist connects all free slots
*/
template<std::size_t MAX_OBJ_SIZE>
class pool{
const size_t aligned_size = (int)(8*ceil(MAX_OBJ_SIZE/8.));// 内存对齐
/*real capacity can be greater than maxcapacity because after
expansion, the object can be released.*/
uint64_t realcap = 0;
uint64_t mincap = 0;
uint64_t maxcap = 0;
atomic<uint64_t> usedcap = {0};
int16_t obj_size = -1;
vector<char*> heads; // heads of pools子对象池
map<char*,int> addr2subpoolsize;
mutex mtx_freelist;
mutex mtx_pool_expansion;
forward_list<char*> freelist;
uint64_t get_usedcap(){ return usedcap;}
pool(std::size_t maxCapacity, std::size_t minCapacity){
static_assert(MAX_OBJ_SIZE>0 && MAX_OBJ_SIZE<1024*1024*100,
"MAX_OBJ_SIZE is not correct, should be in range of [0, 100M].");
assert(maxCapacity>minCapacity);
mincap = minCapacity;
realcap = maxcap = maxCapacity;
uint64_t total_pool_size = maxCapacity * aligned_size;
char* head = new char[total_pool_size]();// 分配内存空间
for (int i=0;i<maxcap; ++i){
freelist.push_front(head + i*aligned_size);// 挂在一个forward_list下面
}
heads.emplace_back(head);
addr2subpoolsize[head] = total_pool_size;
}
~pool(){
for_each(heads.begin(),heads.end(),[](char* p){delete [] p;});
}
/// @brief to find the unused block to place new object instance
char* find_free_block_and_mark(){
lock_guard<mutex> g(mtx_freelist);
char* r = freelist.front();
freelist.pop_front();
return r;
}
/// @brief to be called by the deleter of shared_ptr
/// there is no memory deallocation until end of the program
/// what we need to do is to mark the tag as null, meaning the memory block is not used
void release_block(char* p){
lock_guard<mutex> g(mtx_freelist);
freelist.push_front(p);
--usedcap;
}
/// @brief to allocate memory from pool for a new OBJECT
/// the memory layout is homogeneous, so all objects must be the same type,
/// otherwise an exception will be thrown
/// this function will:
/// 1. find a free block in the pool memeory
/// 2. use `placement new` to put an object into the memory slot
/// 3. put the raw pointer into a shared_ptr to take advantduration of the
/// counting reference features
/// 4. check the capacity left and see if it is necessary to expand the memory pool
template<typename OBJECT, typename ...ARGS>
void alloc (std::shared_ptr<OBJECT> & object, ARGS ...args){
if (MAX_OBJ_SIZE<sizeof(OBJECT)){
throw "object size is too big!";
}
if (obj_size == -1){
obj_size = sizeof(OBJECT);
}else if(obj_size != sizeof(OBJECT)){
throw "Wrong type!";
}
char *freeblock = find_free_block_and_mark();
if (freeblock){
OBJECT* p = new ((void*)freeblock) OBJECT(args...); // placement new
object.reset(p, [this](OBJECT* o){
o->~OBJECT();// call OBJECT's destructor
this->release_block(reinterpret_cast<char*>(o));
});
++usedcap;
if (realcap - mincap < usedcap){
lock_guard<mutex> g(mtx_pool_expansion);
//auto f = async(launch::async, &pool::extend_pool, this);
//f.get();
auto bundle = bind(&pool::extend_pool, this);
packaged_task<void()> ptsk(move(bundle));
auto f = ptsk.get_future();
thread(move(ptsk)).detach();
f.get();
}
}
}
/// @brief Create subpool
void extend_pool(){
lock_guard<mutex> g(mtx_freelist);
uint64_t shortduration = (realcap - mincap);
uint64_t subpoolsize = shortduration * (aligned_size);
cout << "\n(" << __LINE__ << ") " << __FUNCTION__ << " expand pool by "
<< shortduration << " slots!" << endl;
char *head = new char[subpoolsize]();
for (int i=0;i<shortduration; ++i){
freelist.push_front(head + i*aligned_size);
}
heads.emplace_back(head);
addr2subpoolsize[head] = subpoolsize;
realcap += shortduration;
}
};This object pool uses a single linked list to trace all free slots in the pool. Once the shared_ptr object is released, the destructor is called and memory is reclaimed and the head of the slot is push_fronted to the forward_list.
7.4 Design TinyURL
 https://leetcode.com/problems/encode-and-decode-tinyurl/?tab=Description
https://leetcode.com/problems/encode-and-decode-tinyurl/?tab=Description
Note: Do not use class member/global/static variables to store states. Your encode and decode algorithms should be stateless.
class Solution {
string NUM;
int BASE;
int id=1;
unordered_map<int,string> id2LURL;
unordered_map<string,string> L2SURL;
public:
Solution():SURL_SIZE(6){
for(int i=0;i<10;i++) NUM+=('0'+i);
for(int i=0;i<26;i++) NUM+=('a'+i), NUM+=('A'+i);
NUM+='+', NUM+='/';
BASE=NUM.size();
}
// Encodes a URL to a shortened URL.
string encode(string longUrl) {
if(L2SURL.count(longUrl)){
return L2SURL[longUrl];
}
int c=id, t;
string surl;
while(c) t=c%BASE, c=c/BASE, surl=NUM[t]+surl; // int to base64
while(surl.size()<SURL_SIZE) surl='0'+surl;
L2SURL[longUrl] = surl;
id2LURL[id++] = longUrl;
return surl;
}
// Decodes a shortened URL to its original URL.
string decode(string shortUrl) {
string u=shortUrl;
while(u.front()=='0') u.erase(u.begin());
int t=0, L=u.size();
for(int i=L-1;i>=0;i--) t=t*BASE+NUM.find(u[i]); //!!
return (t>id)?"":id2LURL[t];
}
};https://leetcode.com/problems/design-tinyurl/?tab=Description
短网址有什么用? https://www.zhihu.com/question/20790447
Tinyurl最初由Twitter提出,其目的是为了减少推文中的字数限制.其后相继被广泛应用于社交网络之中,并在该原始功能的基础上加入了安全、数据统计等功能.由于其被广大用户熟知,且是一个典型的分布式系统方案它成为一个面试中常见的设计题.
https://segmentfault.com/a/1190000006140476
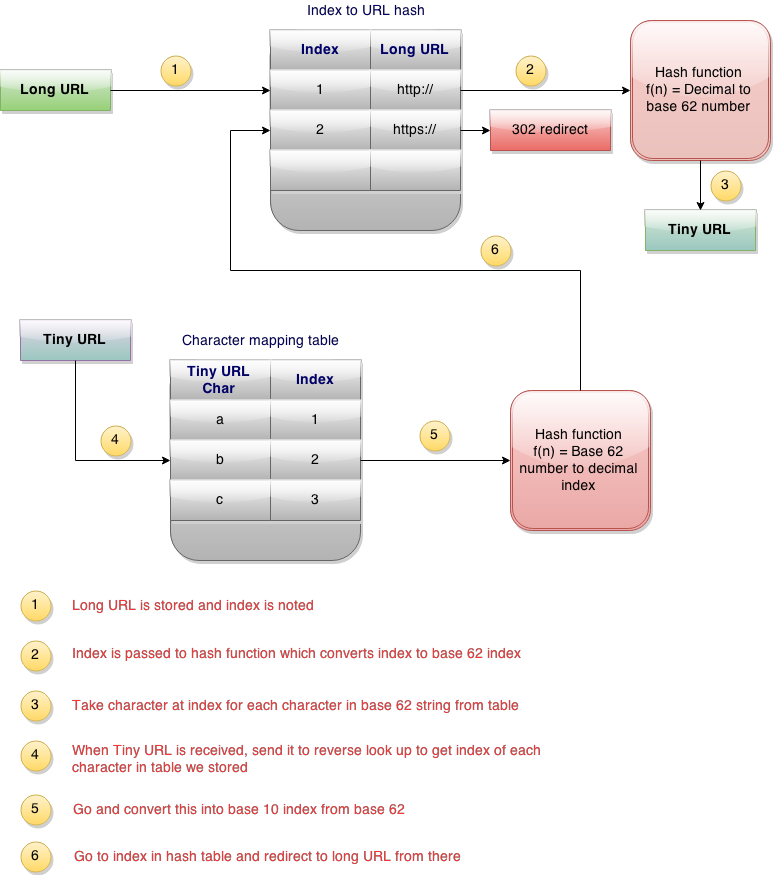
http://algorithmsandme.in/2015/04/design-tinyurl-system/
https://blog.codinghorror.com/url-shortening-hashes-in-practice/
http://systemdesigns.blogspot.com/2015/12/tinyurl-url-shorten-app.html
https://www.zhihu.com/question/29270034
考点1,让你算5个字节base62,或者64编码,可以表示总共多少URL?会数学的码农是不可战胜的.看到64,应该知道是\(2^6\),然后再有5个characters,可以表示的URL总数就是\({2^6}^5=2^{30}\)就是1 billion.(计算机的1G等于数学上的1B).
其实精准的答案是\(2^{30}+2^{24}+2^{18}+2^{12}+2^6\)= \(1G+16M+256K+4K+64\),如果能写这个出来,至少在这个问题上,做到100分了.
考点2,Cache. 对Redis和memcached熟悉有加分.这里幸运的是不需要update cache,难度就降低了一些.把常见的URL cache in redis or memcached.这里可以考察对Key Value Store的理解.水可以很深. Cache eviction算法LRU, LFU至少会写pseudo code.
这两道题要信手拈来:
https://leetcode.com/problems/lru-cache/
https://leetcode.com/problems/lfu-cache/
如何结合MySQL和redis或者memcached?redis和memcached的差异?选哪个?各自的原理,优缺点?
 问如何scale-out
考点3, 考distributed system和HA,scalability,sharding.
问如何scale-out
考点3, 考distributed system和HA,scalability,sharding.
如何防止生成的url被scan,比如我知道某id=abc是合法的,然后试id-1 和id+1 不该被猜中. 如果要求随机猜N个url都未命中的概率大于99.99%,如何做到. 如果有人随机猜url 对你的系统有什么影响,如果你是persistant storage+cache 的架构 会有什么问题
如何distribute到多机器 service和storage 都谈谈
如何要限制单个用户的rps,用什么策略,如何实现
用DB index怎么判断一个原始长url是否已经在数据库中?
链接:https://www.zhihu.com/question/29270034/answer/46446911
这个问题看到就想答.
个人相关:三年前在公司做过一个短地址服务,目前在线上跑.
而这个问题,也是我现在招聘面试题里面必考的一道,这一道题里面有很多可考的地方,能够相对综合的考察候选人的功力.
最烂的回答
实现一个算法,将长地址转成短地址.实现长和短一一对应.然后再实现它的逆运算,将短地址还能换算回长地址. 这个回答看起来挺完美的,然后候选人也会说现在时间比较短,如果给我时间我去找这个算法就解决问题了.但是稍微有点计算机或者信息论常识的人就能发现,这个算法就跟永动机一样,是永远不可能找到的.即使我们定义短地址是100位.那么它的变化是62的100次方.62=10数字+26大写字母+26小写字母.无论这个数多么大,他也不可能大过世界上可能存在的长地址.所以实现一一对应,本身就是不可能的. 再换一个说法来反驳,如果真有这么一个算法和逆运算,那么基本上现在的压缩软件都可以歇菜了,而世界上所有的信息,都可以压缩到100个字符.这~可能吗.
另一个很烂的回答
和上面一样,也找一个算法,把长地址转成短地址,但是不存在逆运算.我们需要把短对长的关系存到DB中,在通过短查长时,需要查DB. 怎么说呢,没有改变本质,如果真有这么一个算法,那必然是会出现碰撞的,也就是多个长地址转成了同一个短地址.因为我们无法预知会输入什么样的长地址到这个系统中,所以不可能实现这样一个绝对不碰撞的hash函数.
比较烂的回答
那我们用一个hash算法,我承认它会碰撞,碰撞后我再在后面加1,2,3不就行了. ok,这样的话,当通过这个hash算法算出来之后,可能我们会需要做btree式的大于小于或者like查找到能知道现在应该在后面加1,2,或3,这个也可能由于输入的长地址集的不确定性.导致生成短地址时间的不确定性.同样烂的回答还有随机生成一个短地址,去查找是否用过,用过就再随机,如此往复,直到随机到一个没用过的短地址.
正确的原理
上面是几种典型的错误回答,下面咱们直接说正确的原理.
正确的原理就是通过发号策略,给每一个过来的长地址,发一个号即可,小型系统直接用mysql的自增索引就搞定了.如果是大型应用,可以考虑各种分布式key-value系统做发号器.不停的自增就行了.第一个使用这个服务的人得到的短地址是”http://xx.xx/0” 第二个是”http://xx.xx/1” 第11个是”http://xx.xx/a” 第依次往后,相当于实现了一个62进制的自增字段即可.
几个子问题
- 62进制如何用数据库或者KV存储来做?
其实我们并不需要在存储中用62进制,用10进制就好了.比如第10000个长地址,我们给它的短地址对应的编号是9999,我们通过存储自增拿到9999后,再做一个10进制到62进制的转换,转成62进制数即可.这个10~62进制转换,你完全都可以自己实现.
- 如何保证同一个长地址,每次转出来都是一样的短地址
上面的发号原理中,是不判断长地址是否已经转过的.也就是说用拿着百度首页地址来转,我给一个”http://xx.xx/abc” 过一段时间你再来转,我还会给你一个 “http://xx.xx/xyz”.这看起来挺不好的,但是不好在哪里呢?不好在不是一一对应,而一长对多短.这与我们完美主义的基因不符合,那么除此以外还有什么不对的地方? 有人说它浪费空间,这是对的.同一个长地址,产生多条短地址记录,这明显是浪费空间的.那么我们如何避免空间浪费,有人非常迅速的回答我,建立一个长对短的KV存储即可.嗯,听起来有理,但是…这个KV存储本身就是浪费大量空间.所以我们是在用空间换空间,而且貌似是在用大空间换小空间.真的划算吗?这个问题要考虑一下.当然,也不是没有办法解决,我们做不到真正的一一对应,那么打个折扣是不是可以搞定?这个问题的答案太多种,各有各招,我这就不说了.(由于实在太多人纠结这个问题,请见我最下方的更新)
- 如何保证发号器的大并发高可用
上面设计看起来有一个单点,那就是发号器.如果做成分布式的,那么多节点要保持同步加1,多点同时写入,这个嘛,以CAP理论看,是不可能真正做到的.其实这个问题的解决非常简单,我们可以退一步考虑,我们是否可以实现两个发号器,一个发单号,一个发双号,这样就变单点为多点了?依次类推,我们可以实现1000个逻辑发号器,分别发尾号为0到999的号.每发一个号,每个发号器加1000,而不是加1.这些发号器独立工作,互不干扰即可.而且在实现上,也可以先是逻辑的,真的压力变大了,再拆分成独立的物理机器单元.1000个节点,估计对人类来说应该够用了.如果你真的还想更多,理论上也是可以的.
- 具体存储如何选择
这个问题就不展开说了,各有各道,主要考察一下对存储的理解.对缓存原理的理解,和对市面上DB、Cache系统可用性,并发能力,一致性等方面的理解.
- 跳转用301还是302
这也是一个有意思的话题.首先当然考察一个候选人对301和302的理解.浏览器缓存机制的理解.然后是考察他的业务经验.301是永久重定向,302是临时重定向.短地址一经生成就不会变化,所以用301是符合http语义的.同时对服务器压力也会有一定减少.
但是如果使用了301,我们就无法统计到短地址被点击的次数了.而这个点击次数是一个非常有意思的大数据分析数据源.能够分析出的东西非常非常多.所以选择302虽然会增加服务器压力,但是我想是一个更好的选择.
301是永久的move了(1表示永久),302是临时的move了.
——五一假期后更新——-
就回答一点大家最纠结的问题吧,就是如何实现同一个长地址多次转换,出来还是同一个短地址.
我上面其实讲到了,这个方案最简单的是建立一个长对短的hashtable,这样相当于用空间来换空间,同时换取一个设计上的优雅(真正的一对一).
实际情况是有很多性价比高的打折方案可以用,这个方案设计因人而异了.那我就说一下我的方案吧.
我的方案是:用key-value存储,保存"最近"生成的长对短的一个对应关系.注意是"最近",也就是说,我并不保存全量的长对短的关系,而只保存最近的.比如采用一小时过期的机制来实现LRU淘汰.
这样的话,长转短的流程变成这样:
1 在这个”最近”表中查看一下,看长地址有没有对应的短地址
1.1 有就直接返回,并且将这个key-value对的过期时间再延长成一小时
1.2 如果没有,就通过发号器生成一个短地址,并且将这个”最近”表中,过期时间为1小时
所以当一个地址被频繁使用,那么它会一直在这个key-value表中,总能返回当初生成那个短地址,不会出现重复的问题.如果它使用并不频繁,那么长对短的key会过期,LRU机制自动就会淘汰掉它.
当然,这不能保证100%的同一个长地址一定能转出同一个短地址,比如你拿一个生僻的url,每间隔1小时来转一次,你会得到不同的短地址.但是这真的有关系吗?
 匿名用户 - 7 人赞同了该回答
刚好本人负责短链接.我简单说下.
匿名用户 - 7 人赞同了该回答
刚好本人负责短链接.我简单说下.
既然是短链接,那么地址池是有限的.所以 在业务上会要求接受短链接失效,保证可回收利用.但是总有一些场景要求长期有效,所以可预留一些特殊的.
以上是最基本的系统功能要求.
至于技术上怎么做,太简单了.DB索引,随机都可以,搞个分库分表,读多写少. 随机的时候碰撞了就重试几次,没什么问题.在 对总短链接数做个监控,地址用的太多会造成随机碰撞越来越多,也可能是回收机制出问题了.
另外 __防攻击__做好.别个把你链接池地址耗光.
匿了,不想被发现
黄友恭黄友恭1 年前
从goo.gl和is.gd的使用经验来看,1. 时间相近的转换结果值并不靠近,2. 很长时间之后重新转换某长网址得到的结果也是相同的.楼主能否介绍一下方案的异同?
雨御雨御回复黄友恭1 年前
不是答主,猜测一下而已.对于”时间相近的转换结果值并不靠近”,可能是你遇到不同的发号机了,所以相距很远.而且他们把发号数字转换成字母的方式也可能不太一样,导致相近的数字转换出完全不像的字母.对于”很长时间之后重新转换某长网址得到的结果也是相同的”,可能是你转换的东西很常用,隔三岔五就有个路人来转换它,所以一直保留在cache.
对5个char的SURL服务来说.SURL的空间是1B.如果每1M一个发号机,就有1K个发号机.
王赟 Maigo1 年前
关于不需要保证一长对一短那一段儿,我有个疑问.短到长的映射表应该是要存储在服务器上的吧?所以再加一个长到短的hash表,应该不怎么费额外的空间呀.而且有些网址会十分常见,如果允许一长对多短,这些网址会占用大量短网址,反倒费空间.
iammutex(作者)回复王赟 Maigo
浪费一倍以上的空间而已.如果平均重复率到达2以上,那可以考虑.而我并不主张重复,但是建立长对短的hash table是很不划算的方式,有很多性价比更高的方法.看来我还是更新下文章吧,都在纠结这个细节点…
蓝山sd蓝山sd5 个月前
给长网址缩短的时候,如果避免重复转换,先查询长网址是否已经转换过;如果转换过,就直接返回短网址;如果没有转换过,则新生成短网址,存入数据库.请问如果想实现这个查询长网址是否已经转换过,这个操作一般怎么实现,复杂度大概是什么量级?谢谢
iammutexiammutex(作者)回复蓝山sd5 个月前
如果用我在最后提到的key-value键值对,只需要一个hash table来实现,用memcached或者Redis就可以,复杂度为O(1)
蓝山sd蓝山sd回复iammutex(作者)5 个月前 多谢回复.怎么感觉网址转换这种应用并没有太多temporal locality呢.因为网站信息分布太杂太广,信息有效期也不短(比如我们经常去阅读数月前,甚至数年前的网页)真的会出现一段时间内,很多请求都是要求转换相同的网址么? 如果memcache miss了,那我们是否就需要用长网址去到数据库中从数以亿计的表项中去查询?如果需要,请问这部分复杂度大概多少(是否log(n)级别的?如果是B+树之类的实现)
iammutexiammutex(作者)回复蓝山sd5 个月前
这个设计,并不是为了保证100%的长对短的唯一性,这个唯一性对于功能性没有任何意义.之所以用这个方法,去尽量做到唯一性,只是为了节约空间(SURL池),防止短时间大量重复请求而生成的冗余数据(消耗SURL池).所以如果miss了,那就再生成一个,这样多个短地址都对应同一样长地址,并没有任何问题,不需要去遍历所有长地址比对.从另一个层面看,这是一个空间换空间的做法,用稍许的内存存储,换取大量的持久存储.
刘小笨刘小笨21 天前
为啥如果使用了301,我们就无法统计到短地址被点击的次数了,访问短链,服务器找到对应的长链的时候不就可以做点击次数的记录了么?
iammutexiammutex(作者)回复刘小笨20 天前
301是客户端缓存了转换结果,不请求服务端.
HTTP 302和其他的区别:
https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#3xx_Redirection
302 Found - This is an example of industry practice contradicting the standard.
7.4.1 Customize short URL
如下是出现冲突的情况
纯银纯银回复iammutex(作者)8 个月前
eg:
短网址网站http://www.t.cn/abcde
那abcde就是自定义的字符,如何快速判断abcde是否在短网址库中存在?
看过吴军博士在《数学之美》中用哈希表解决email黑名单的问题,那个判断很快(虽然也有碰撞),但不知道还有没有其他方法?
iammutexiammutex(作者)回复纯银8 个月前
「如何快速判断abcde是否在短网址库中存在?」
这个问题,真不值得答啊朋友.这就是一次短网址对长网址的查找,找到就存在,没找到就不存在.这是短地址的最重要的功能,能够从短地址找到长地址.
7.4.2 Random URL Value to avoid URL scan
防止url被scan. 业界的确已经实现了这个功能.
http://stackoverflow.com/a/12996028/3951977
I found the following algorithm provides a very good statistical distribution. Each input bit affects each output bit with about 50% probability. There are no collisions (each input results in a different output).
uint32_t hash ( uint32_t x ) {
x = ( ( x >> 16 ) ^ x ) * 0x45d9f3b;
x = ( ( x >> 16 ) ^ x ) * 0x45d9f3b;
x = ( ( x >> 16 ) ^ x );
return x;
}
uint32_t unhash ( uint32_t x ) {
x = ( ( x >> 16 ) ^ x ) * 0x119de1f3;
x = ( ( x >> 16 ) ^ x ) * 0x119de1f3;
x = ( ( x >> 16 ) ^ x );
return x;
}可以用这个方法来产生貌似随机的id给客户端,然后数据库仍然是自增1.
其实用knuth hash也不错,简单好记: 2654435761.
7.4.3 Rate Limit to avoid DOS attack
当某个用户每分钟write或者read超过一定次数就屏蔽访问. 可以使用counter对用户cookie做统计.
关于cookie: http://www.w3schools.com/js/js_cookies.asp
如果用户伪造cookie,就直接开启robot check.如果是通过api来的流量会有用户名和secret key.
7.4.4 Avoid hotspot
这篇文章里面提到的东西似乎和业界的实践有些差距https://segmentfault.com/a/1190000006140476 , 但是也有很多值得学习的地方,比如他提到consistent hash ring:
http://www.martinbroadhurst.com/consistent-hash-ring.html
http://www.paperplanes.de/2011/12/9/the-magic-of-consistent-hashing.html
https://ihong5.wordpress.com/2014/08/19/consistent-hashing-algorithm/
https://highlyscalable.wordpress.com/2012/09/18/distributed-algorithms-in-nosql-databases/
https://infinitescript.com/2014/10/consistent-hash-ring/
7.4.5 HA
http://www.jiuzhang.com/qa/87/

Hot standy
- https://blogs.sap.com/2016/09/20/high-availability-warm-standby-hot-standby/
- https://www.ibm.com/developerworks/community/blogs/RohitShetty/entry/high_availability_cold_warm_hot?lang=en
7.4.6 Statistics
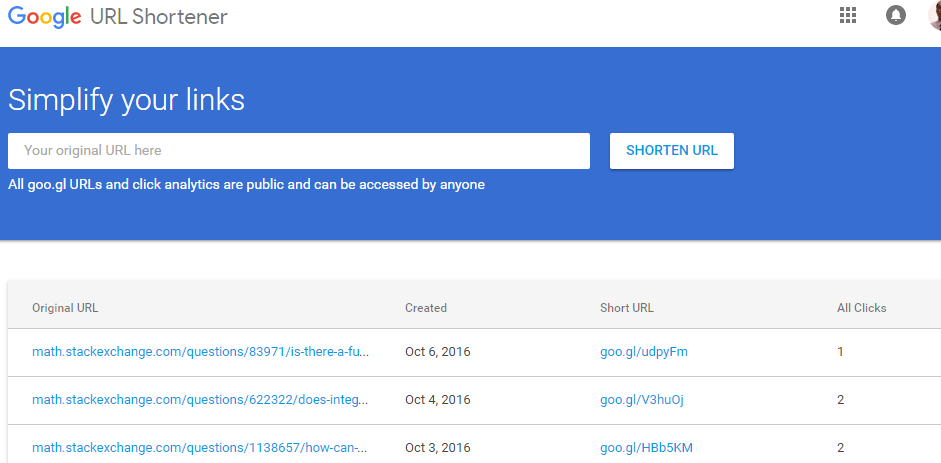
简单一点的统计功能用下面的URL Shortener Service Using Redis就能实现.
登陆之后会看到一些统计数据.这个统计数据其实很有用.比如我发布一个SURL,我想看到到底有多少人点击过.
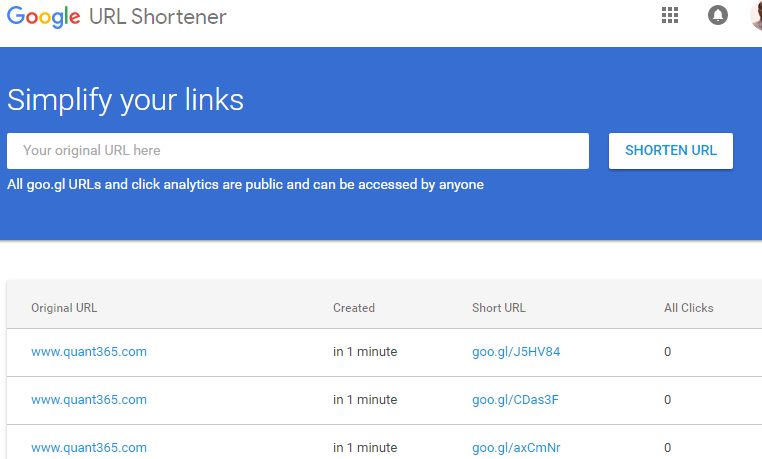
登陆之后,相同的LURL和登陆之前得到不同的SURL.而且每次相同的LURL被shorten之后都得到不同的SURL. 这里肯定使用了不同的算法.
L家onsite的时候被问了这个(大QPS,1B),还追问了如果用
单点发号器挂了怎么办,如果要查询某一个长URL在过去某一段时间(要求精确时间,比如从6月7号到6月9号)内的访问次数怎么做(这个好像跟发号的方案有冲突,因为没法保证长对短1v1,当时给的方案是记log,但在这种qps下长时间记录log似乎不太现实,总之没答好),先写下来大家讨论讨论
这个问题如果用上面的解决方案的确够呛.最阴险的让统计长链接的数据,而不是短链接.短链接就好做了,因为短链接是key.key不可能重复.长连接是值,是有可能重复的.
先来个简单的求SURL在过去某段时间的访问次数.时间的粒度假设为每天.
| surlID | date | counter |
|---|---|---|
| 1 | 20170201 | 101 |
| 1 | 20170202 | 622 |
| 1 | 20170203 | 922 |
| 2 | 20170201 | 23 |
| 2 | 20170203 | 25 |
如果有1B个SURL,3年就最多有1T个row.
The MyISAM storage engine supports \(2^{32}\) rows per table, but you can build MySQL with the --with-big-tables option to make it support up to \(2^{64}\) rows per table. 能存但是不能查,应该就是一个数据库集群就搞定.
现在redis里面累加counter,然后晚上的时候流量小的时候导入数据库集群.其实redis会每隔段时间偷偷写到db里面去的.
那如果他要具体某一天访问量最大的url呢.
[LV3]林 2/12/2017 11:53:47 PM
记下每天前100的url,写db?
[LV4]BB 2/12/2017 11:54:13 PM
这个需求就包括了计算了
[LV4]BB 2/12/2017 11:54:29 PM
需要用归并
[LV4]BB 2/12/2017 11:54:51 PM
如果不是实时的话就用数据库都行
[LV4]BB 2/12/2017 11:55:09 PM
如果要实时的话可以用storm,storm专门干这个的
[LV4]BB 2/12/2017 11:56:14 PM
比如有1000台数据库,你在每台上找前100,然后再在结果中找前100
[LV4]BB 2/12/2017 11:56:44 PM
storm可以做到实时亚秒出7.4.7 Others
并不同意第一名iammutex 的回答.这是他认为正确的后端设计原理:正确的原理上面是几种典型的错误回答,下面咱们直接说正确的原理.正确的原理就是通过发号策略,给每一个过来的长地址,发一个号即可,小型系统直接用mysql的自增索引就搞定了.如果是大型应用,可以考虑各种分布式key-value系统做发号器.不停的自增就行了.第一个使用这个服务的人得到的短地址是 http://xx.xx/0 第二个是 http://xx.xx/1 第11个是 http://xx.xx/a 第依次往后,相当于实现了一个62进制的自增字段即可.首先先说一下结论.
在我知道的两个主流的短url的service的网站中(bit.ly, goo.gl),并没有使用简单发号器作为后端短url生成器的.
事实上,我测试了一下, 最有可能的算法就是iam提到的”非常烂”的hash 算法.
在不登陆的情况下使用Bitly - The Power of the Link 或者 Redirecting 来对同样的一个网站生成short url 的结果是一样的.
而登陆以后不同用户对于同样一个网站生成的short url 是不同的.最合理的猜测就是这些网站对于同一个网址为hash得到结果,而如果登陆的话user id会作为一个类似salt的token放到hash function中.
而在他评论中黄友恭也提到了他的观察.而答主并没有回答他的问题.我们首先说一下为什么简单发号器是并不是一个特别好的后端设计.
- 从用户需求方面考虑:
Short url 的出现是主要是为了迎合twitter,微博这种限定140字数的SNS短博客出现的. 当一个网站链接超过一定字数以后,用户需要使用short url 之类的service来缩减长链接的字数.基于以上的设定,http://bit.ly, http://goo.gl, TinyURL出现了来迎合这种需求.但是非常容易的想到,在SNS的情景下,大量的内容链接存在同质化的现象. 而且我们知道,对于绝大部分的短链接service的请求,生成短url的需求远高于从short url到original url的查找的需求.(一旦生成,无人click).(Are you sure??)
举个例子来说明上面的情况,假设今天汪峰又要上头条了,他又用无人机给章子怡发了一封分手信.这条新闻在主流网站发布以后,大部分的关于这条新闻的短链接一定是指向这些主流网站的.我们假设有五万个请求吧.而事实上这五万个请求的原链接是一样的.用发号器对于空间的浪费实在是太大了.当然,在第一名回答中他认为这只是一个小问题.最简单的方法是加一个redis之类的memcache层来解决这个问题.
redis 本身也有自己的储存局限,当我们miss一个record 的时候,发号器一定会生成一个新的短链接.直到redis self update了以后这种行为才会停止.
- 更重要的是从系统安全性和盈利方面的考虑:
- http://bit.ly 现在都是有revenue的网站.任何使用他们service 的 网站链接都会被纪录下来.所以这些short url网站都能够非常灵敏的发现哪些内容链接正在社交网站上崛起,这对于第三方投放广告或者是内容挖掘都是非常有帮助的.所以,这些长链接对于这些公司来说是非常重要的财产.
2.假设今天我用http://bit.ly 缩短了一个private link.我并不希望这个private link被很多的人发现,而发号器并不能做到这点.原理很简单.如果short url service使用的是发号器原理的话, 假设某天我看到一个http://xxx.com/660 之类的短链接,我可以很快的写一个爬虫软件来枚举从0-660之间的所有链接.然后试着爬660之后的所有长链接.(已解决)
我知道你的后端就是一个iterator嘛.我能保证我能遍历完已生成的所有链接.
这样,我并不需要任何的代价就能得到这些网站的长链接db. 这对于这些service website 来说是不可接受的.
而这其中.有可能包含一下用户并不想go public的链接,我现在作为第三方也可以很轻易的拿到.其实还有其他的问题.但是主要的就是上面的两个问题.以下是搭建短链接后端的一些内容.过两天更新后端的实现和github code 这两天实在是太忙了
05/03/2015 更新.谢谢刘飞宇的提醒.以下更新如何在发号器的基础上部分解决62 base pseudo random url的生成以及回答一下他的问题.我能找到的最好的资源c# - How do sites like goo.gl or jsfiddle generate their URL codes? 在这里. 其中默认使用的是发号器的原理.
其中的解决办法是用Feistel cipher来对increment id进行变形.
其中的原理我并不多说了.其实不难.这里permuteId有两个好处.第一.对于同一个id 他一定会声称一个32bit的integer而不会发生collision,第二.permutedId(permuteId(id)) == id .
先经过以上处理然后转化成62进制的shorturl,基本上可以看作是psudo random的.这在一定程度上可以防止第二种情况(系统安全以及盈利角度)的恶意 crawl.
假设发号器的id是从1开始的.以下3个为id=1开始生成的short url.
9iKV
FEaL6
b4NFC 这个在一定程度上可以防止恶意软件来爬长链接.
但是这不是一个最优解.
原因如下.
无论通过何种方式来进行优化,在发号器中一定是短url的namespace和id的数量进行bijection一一映射的.
这是什么意思?
就是假设一个长链接来了.除非对绝大部分的长地址进行储存和查找.(这其实并不可取),不然一定会是有一长对多短的情况产生的.当长链接的数量到了一定量的时候.整个namespace会非常拥挤.因为对应的一定是incremental id,而不是长链接本身.
当namespace拥挤的时候,通过枚举是可以得到大部分的长链接的.
举一个例子来说.在62base 5位的空间中.tinyurl 非常的拥挤.
http://bit.ly 则很难通过枚举来得到绝大部分的url.
我随便测试的url是http://tinyurl.com/a3320, http://bit.ly/a3320.
然后我试了从a3320 - a3399的 所有情况.
tinyurl 返回了64次,http://bit.ly 返回28次.
05/04/2015 更新基于Hash 的URL 的生成办法.
以下更新一下 一些简单的Hash的生成短url的办法.其实最初想要研究这个问题,一方面是个人经验与第一名的回答不是特别相符合.另一方面,仅从engineering 的角度,我不太喜欢给一个engineering solution”烂”,“更烂”,“一样烂”这样的标签.发号器固然是一个可行的思路,可是别人一说Hash你就给别人的思路打上了”烂”的标签,不太好.因为从Hash的思路拓展开来.这也是可行的.我们先说一个简单的思路大家都很纠结的Hash collision怎么解决.
我们先动用一些数学知识来进行一下计算.假设我们使用类似SHA或者MD5的hash algorithm来得到差不多96位bit的hash value.
这样我们可能的output space 是\(2^{96}\) 位.好.以下我来说一下一个简单但是很经典的概率问题 ,生日問題.是什么意思呢,就是 今天班主任来到一个70的班上,说我跟你们打赌五毛,不,五块钱,你们之中最起码有两个人的生日是一样的.大家肯定都不信啊,抽屉原理啊,至少也得有366的人班你才能这么说啊.
可事实上,还真有.啥意思呢.假设这个班上至少有两个人生日是一样的概率是p(A), 大家生日都不一样的概率是p(A’),显然 p(A) = 1- p(A’). 那P(A’) 怎么算呢.以下是我截的wiki的解释图.非常简单.
大家可以看到.在100个人的班上.有两个人的生日会重合的概率就已经接近于百分之一百了.好回到我们的问题.我们大概需要多少 长url 到 短url 的请求才能能使的两个hash value 的值有可能collide呢?
这个问题等价于.现在总共有 d = \(2^{96}\)天, 我们来定一个threshold 就说是百万分之一p =(10^-6)的概率有可能有重合好了.
我们需要一个多大的班来保证这个百万分之一呢?下面是这个概率的估算公式.
这里n 是班级里面的人数,d是 \(2^{96}\). 带入运算,这里n 约等于 4 * 10 ^11. 这是什么意思?
假设你的系统每个月有十亿不同新的长链接 (10^9之前完全没有见过的新链接)转化的请求,你的系统需要跑大概四十年.才有百万分之一的可能造成至少一对的collide.
四十年啊.百万分之一啊.当然这是非常简单的数学和思路.也有他的局限性.因为\(2^{96}\) 差不多是62base中16位左右.也就是我们的系统生成的短链接没有那么短.好.接下去几天要考试我就先歇一下,考完回来更新 如何通过hash的办法在这之上限制到短链接到只能到8位.
05/12/2015. 更新对不住大家.还有四天考试和一堆事情才算完.之后还有一点私事.mark 一下要讲的东西 http://word.bitly.com/post/28558800777/dablooms-an-open-source-scalable-counting
7.4.8 URL Shortener Service Using Redis
需求:
- URL Shorten/Expand: Given a long URL (say, http://www.google.com/….), our service will generate a short-key e.g. xyz so that a short URL http://ab.ly/xyz (hosted on a domain http://ab.ly) when accessed, visitor will be redirected to the original long URL (http://www.google.com/..)
- Record Clicks: We want to record the number of times a short URL (http://ab.ly/xyz) has been visited
- Recent Visitors for a short URL: We want to store basic information e.g referrer, user agent, ip etc for recent n visitors for a given short URL. List of Recent Short URLs generated by the service.
7.4.9 Hash
https://github.com/dylang/shortid
Non-sequential so they are not predictable.
Supports cluster (automatically), custom seeds, custom alphabet.
Can generate any number of ids without duplicates, even millions per day.
7.5 Consistent Hash
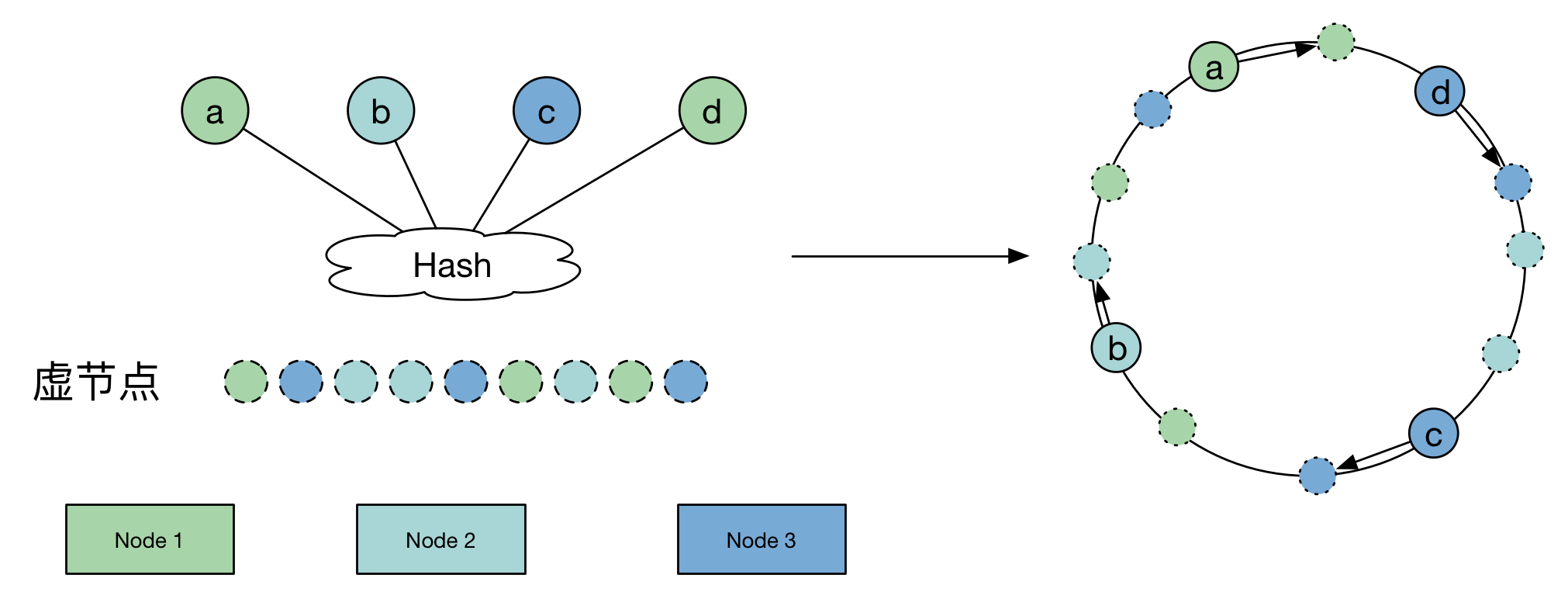
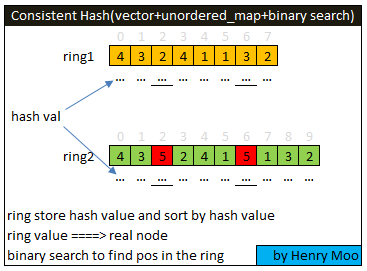
- Load Balance
# ccat virtual_consist_hash.py
from hashlib import md5
from struct import unpack_from
from bisect import bisect_left
ITEMS = 10000000
NODES = 100
VNODES = 1000 # number of vnode for one real node
node_stat = [0 for i in range(NODES)]
def _hash(value):
k = md5(str(value)).digest()
ha = unpack_from(">I", k)[0]
return ha
ring = []
hash2node = {}
for n in range(NODES):
for v in range(VNODES):
h = _hash(str(n) + str(v))
ring.append(h)
hash2node[h] = n
ring.sort()
print 'ring size:', len(ring)
for item in range(ITEMS):
h = _hash(str(item))
n = bisect_left(ring, h) % (NODES*VNODES)
node_stat[hash2node[ring[n]]] += 1
print sum(node_stat), node_stat
_ave = ITEMS / NODES
_max = max(node_stat)
_min = min(node_stat)
print("Ave: %d" % _ave)
print("Max: %d\t(%0.2f%%)" % (_max, (_max - _ave) * 100.0 / _ave))
print("Min: %d\t(%0.2f%%)" % (_min, (_ave - _min) * 100.0 / _ave))Test the load balance:
13:16 # python virtual_consist_hash.py
ring size: 100000
Ave: 100000
Max: 116902 (16.90%)
Min: 9492 (90.51%)- Data Migration Needed
# ccat virtual_consist_hash_add.py
from hashlib import md5
from struct import unpack_from
from bisect import bisect_left
ITEMS = 10000000 # 10m key
NODES = 100
NODES2 = 101
VNODES = 1000
def _hash(value):
k = md5(str(value)).digest()
ha = unpack_from(">I", k)[0]
return ha
ring = []
hash2node = {}
ring2 = []
hash2node2 = {}
for n in range(NODES):
for v in range(VNODES):
h = _hash(str(n) + str(v))
ring.append(h)
hash2node[h] = n
ring.sort()
for i in range(1,10):
print "ring1 value",ring[-i],", realnode:",hash2node[ring[-i]]
print "*"*50
for n in range(NODES2): # 101
for v in range(VNODES):
h = _hash(str(n) + str(v))
ring2.append(h)
hash2node2[h] = n
ring2.sort()
for i in range(1,10):
print "ring2 value",ring2[-i],", realnode:",hash2node2[ring2[-i]]
print len(ring)
print len(ring2)
print "*"*50
change = 0
for item in range(ITEMS):
h = _hash(str(item))
n = bisect_left(ring, h)
n2 = bisect_left(ring2, h)
if hash2node[ring[n]] != hash2node2[ring2[n2]]:
change += 1
print("Change: %d\t(%0.2f%%)" % (change, change * 100.0 / ITEMS))After adding one more node, the data migration needed is just 1%:
✔ ~/sde_web/src/consistent_hash [java-book {origin/java-book}|✚ 4]
13:20 # python virtual_consist_hash_add.py
ring1 value 4294966936 , realnode: 40
ring1 value 4294957706 , realnode: 95
ring1 value 4294895034 , realnode: 69
ring1 value 4294877030 , realnode: 30
ring1 value 4294858393 , realnode: 30
ring1 value 4294754723 , realnode: 25
ring1 value 4294676209 , realnode: 12
ring1 value 4294635037 , realnode: 56
ring1 value 4294633095 , realnode: 86
**************************************************
ring2 value 4294966936 , realnode: 40
ring2 value 4294957706 , realnode: 95
ring2 value 4294895034 , realnode: 69
ring2 value 4294877030 , realnode: 30
ring2 value 4294858393 , realnode: 30
ring2 value 4294754723 , realnode: 25
ring2 value 4294676209 , realnode: 12
ring2 value 4294635037 , realnode: 56
ring2 value 4294633095 , realnode: 86
100000
101000
**************************************************
Change: 104871 (1.05%)7.7 502. Mini Cassandra
Cassandra is a NoSQL storage. The structure has two-level keys.
Level 1: raw_key. The same as hash_key or shard_key.
Level 2: column_key.
Level 3: column_valueraw_key is used to hash and can not support range query. let’s simplify this to a string. column_key is sorted and support range query. let’s simplify this to integer. column_value is a string. you can serialize any data into a string and store it in column value.
implement the following methods:
insert(raw_key, column_key, column_value)
query(raw_key, column_start, column_end) // return a list of entriesExample
insert("google", 1, "haha")
query("google", 0, 1)
>> [(1, "haha")]http://lintcode.com/en/problem/mini-cassandra/
/**
* Definition of Column:
* class Column {
* public:
* int key;
* String value;
* Column(int key, string value) {
* this->key = key;
* this->value = value;
* }
* }
*/
class MiniCassandra {
public:
MiniCassandra() {
// initialize your data structure here.
}
/**
* @param raw_key a string
* @param column_start an integer
* @param column_end an integer
* @return void
*/
void insert(string raw_key, int column_key, string column_value) {
// Write your code here
table[raw_key][column_key] = column_value;
}
/**
* @param raw_key a string
* @param column_start an integer
* @param column_end an integer
* @return a list of Columns
*/
vector<Column> query(string raw_key, int column_start, int column_end) {
// Write your code here
vector<Column> result;
auto it1 = table[raw_key].lower_bound(column_start);
auto it2 = table[raw_key].upper_bound(column_end);
while (it1 != it2) {
result.push_back(Column(it1->first, it1->second));
++it1;
}
return result;
}
private:
unordered_map<string, map<int, string>> table;
};primary key -> columns
7.8 Design Amazon Product Page
在SQL里面一个产品有多个图片多个价格的话怎么设计数据库.后台提取数值render到页面上得时候,class怎么设计,服务器怎么安排,另外怎么考虑suggest product.
http://www.1point3acres.com/bbs/thread-169441-1-1.html
http://www.mitbbs.com/article_t/JobHunting/33134433.html
https://instant.1point3acres.com/thread/138352
http://www.amazon.com/gp/seller/asin-upc-isbn-info.html Amazon Standard Identification Number https://docs.aws.amazon.com/AWSECommerceService/latest/DG/VariationParent.html
- Amazon Recommendation Engine Algorithms
http://systemdesigns.blogspot.com/2015/12/amazon-buy-page.html
- E-Commence Site System Design