Chapter 8 System Design 3
8.3 Key-Value Store
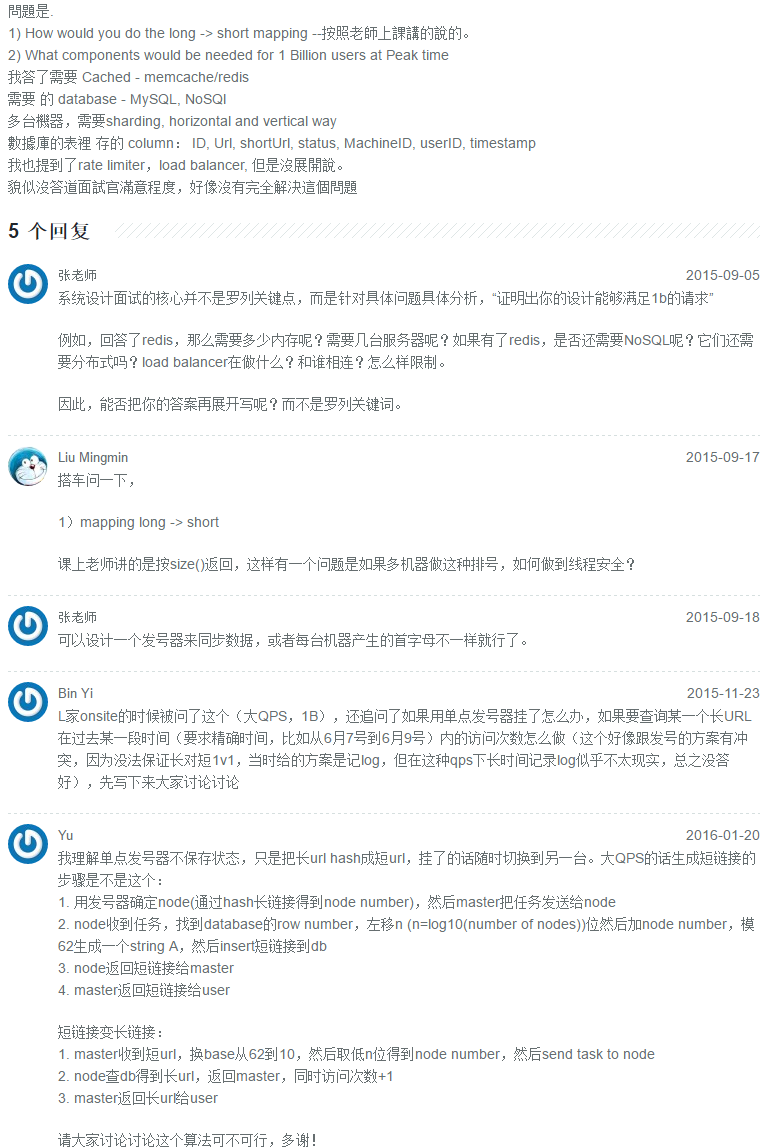
[LiveRamp]设计一个Key-Value Store
这是我面LiveRamp的面试题:这题是电面,所以只用说清楚思路, 但是用嘴说一个分布式系统的思路实在太困难了, 而且对面小哥貌似是伯克利的,我说一段,他就问一段,节奏太快,面的感觉不好,后来写了封感谢信,人家推荐我学一下伯克利的CS162,Link:http://cs162.eecs.berkeley.edu/, 赶紧看了一下. 真是很好的课. 特别是Phase3到Phase4.建议大家有时间看看.
面试的过程是这样的:
第一个问题是: 请设计一个Key-Value Store for 1mb data. 我脑子都不转就说HashMap<Key,Value>, 然后聊了一下时间复杂度,还有重复怎么办, 注意put操作默认是override value的.
讨论了五分钟后, 接着问, What if the size of data increase to 1tb, 我说不能HashMap了, 因为HashMap是存在内存中的, 这么大的data存不进去, 丢了也不好办, 所以就开始分布式设计了, 但是我考虑了一下, 1tb的data存本地硬盘就好了, 所以我说, 存在硬盘里,但是考虑到存的是stable storage里,而不是普通的硬盘, 做个RAID什么的…然后聊了聊怎么存取, 简单说就是用key划分一下目录层级什么的.
又过了十五分钟后, 问如果有1pb data 怎么办, 这个果断开始分布式了, 我当时是按照着dynamo的概念说的, 但是在讨论trade off的时候, 明显没有对方熟悉一些概念和设计模式, 所以就挂了.
确实很遗憾, 因为对方最后也说前边面的都不错. 看来基础还是最重要的. Move On了.
Implementing a Fault-Tolerant Distributed Key-Value Store: http://blog.fourthbit.com/2015/04/12/building-a-distributed-fault-tolerant-key-value-store
http://blog.bittiger.io/post175/
Redis源码剖析(四)过期键的删除策略 http://blog.csdn.net/sinat_35261315/article/details/78976272
过期键删除策略
对于过期键值对的删除有三种策略,分别是
定时删除,设置一个定时器和回调函数,时间一到就调用回调函数删除键值对.优点是及时删除,缺点是需要为每个键值对都设置定时器,比较麻烦(其实可以用timer_fd的,参考muduo定时任务的实现)
惰性删除,只有当再次访问该键时才判断是否过期,如果过期将其删除.优点是不需要为每个键值对进行时间监听,缺点是如果这个键值对一直不被访问,那么即使过期也会一直残留在数据库中,占用不必要的内存
周期删除,每隔一段时间执行一次删除过期键值对的操作.优点是既不需要监听每个键值对导致占用CPU,也不会一直不删除导致占用内存,缺点是不容易确定删除操作的执行时长和频率Redis采用惰性删除和周期删除两种策略,通过配合使用,服务器可以很好的合理使用CPU时间和避免内不能空间的浪费
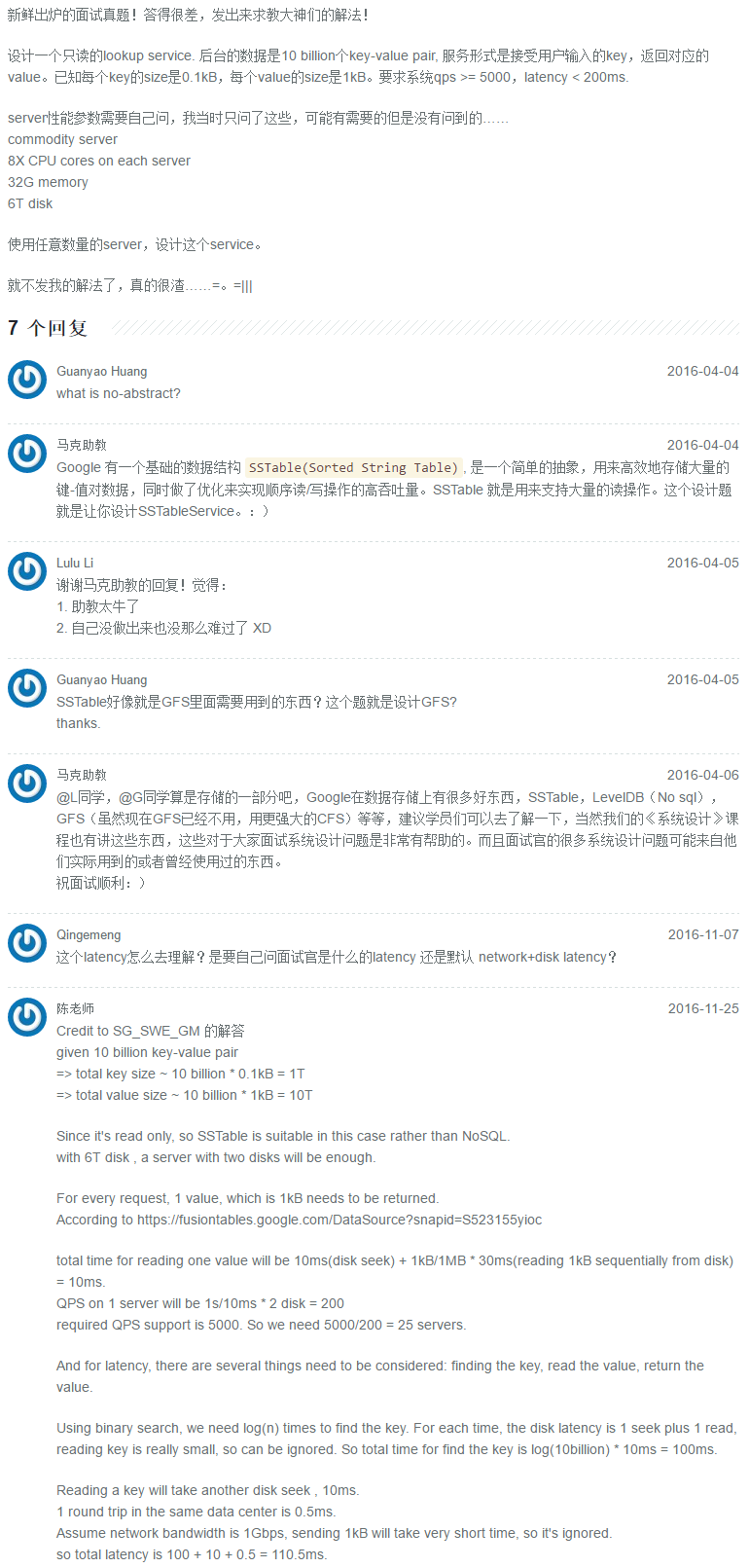
8.4 Spell Correction Detection
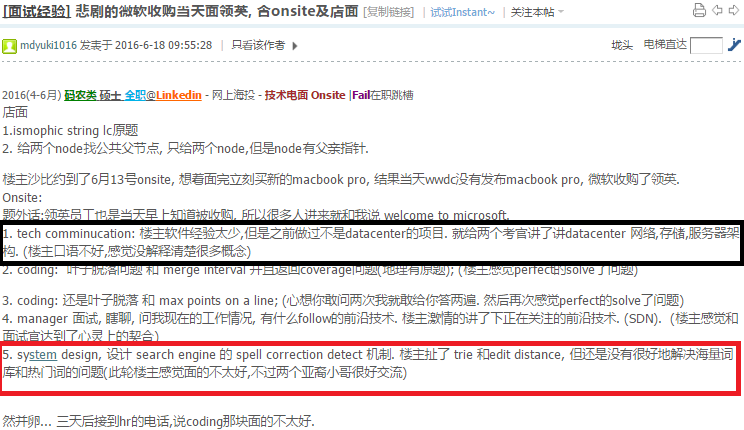
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=193476
EPI P397
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=192084
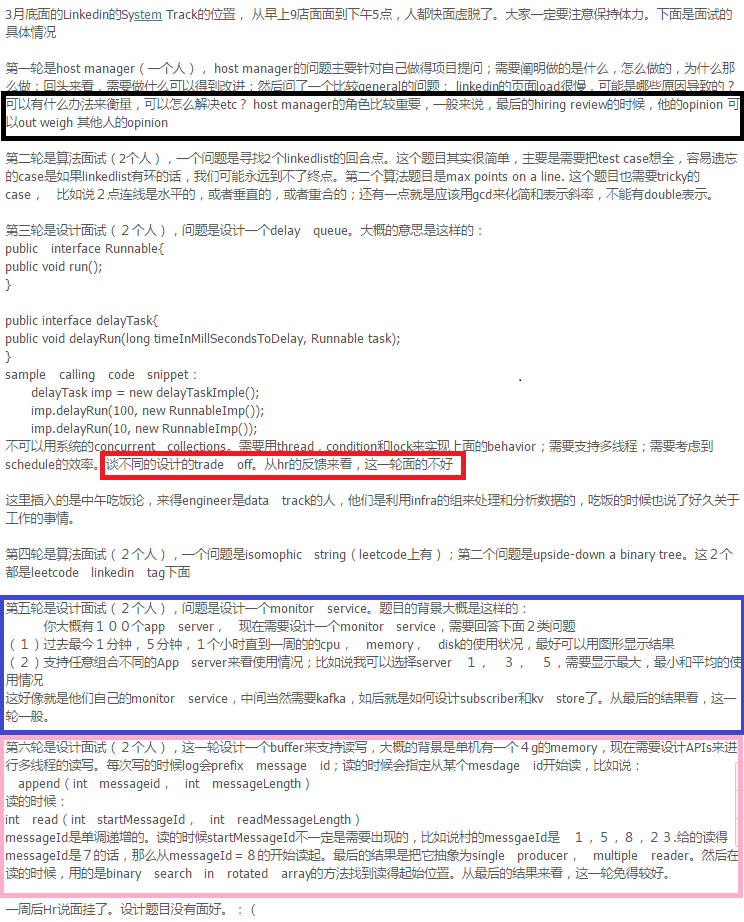

http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=157891
kafka论文
8.5 Set Cover Algorithm
http://massivetechinterview.blogspot.com/2015/12/linkedin-get-secondthird-friends.html
论文: Using Set Cover to Optimize a Large-Scale Low Latency Distributed Graph
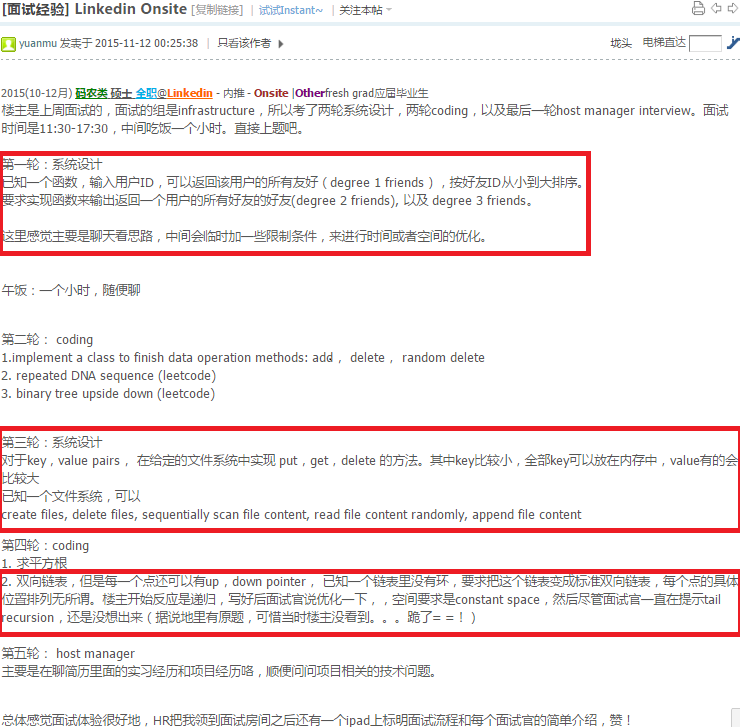
http://www.1point3acres.com/bbs/thread-147555-1-1.html
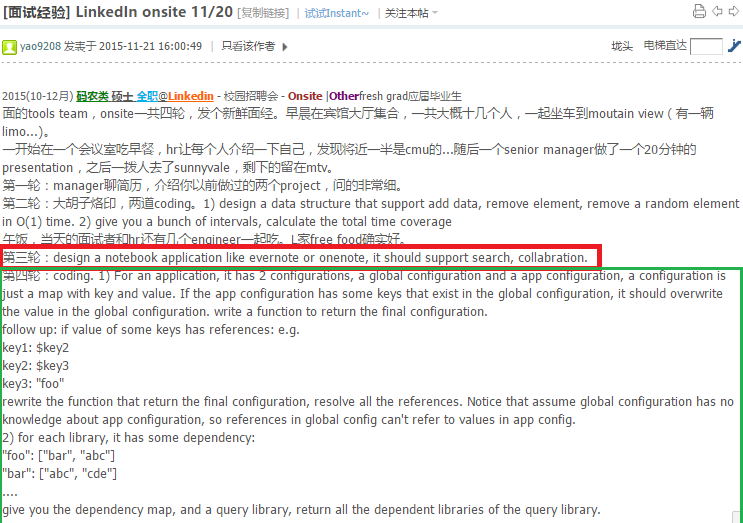
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=148877
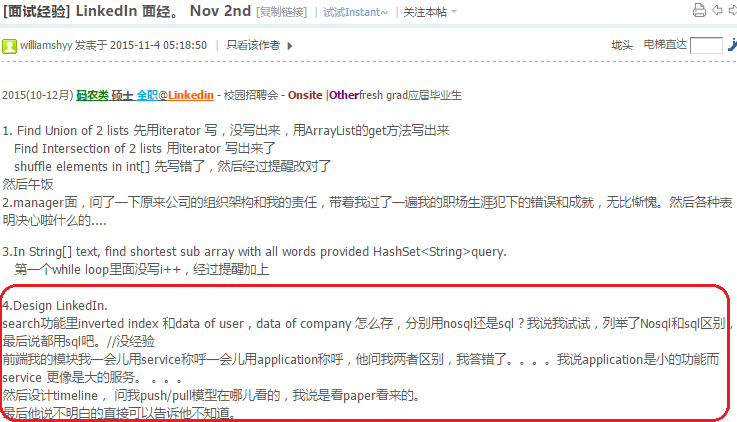
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=146541
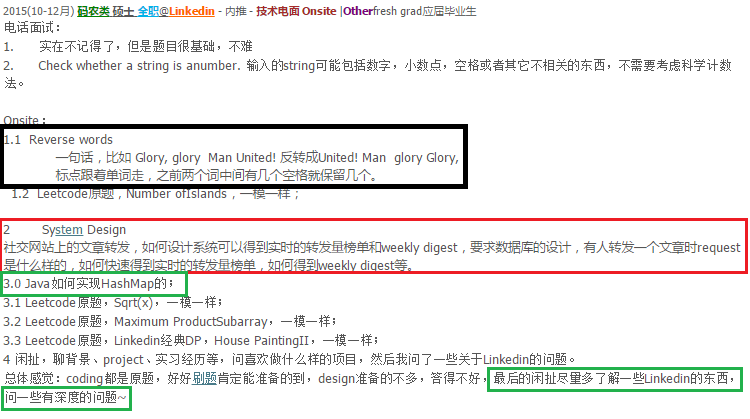 http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=146566
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=146566
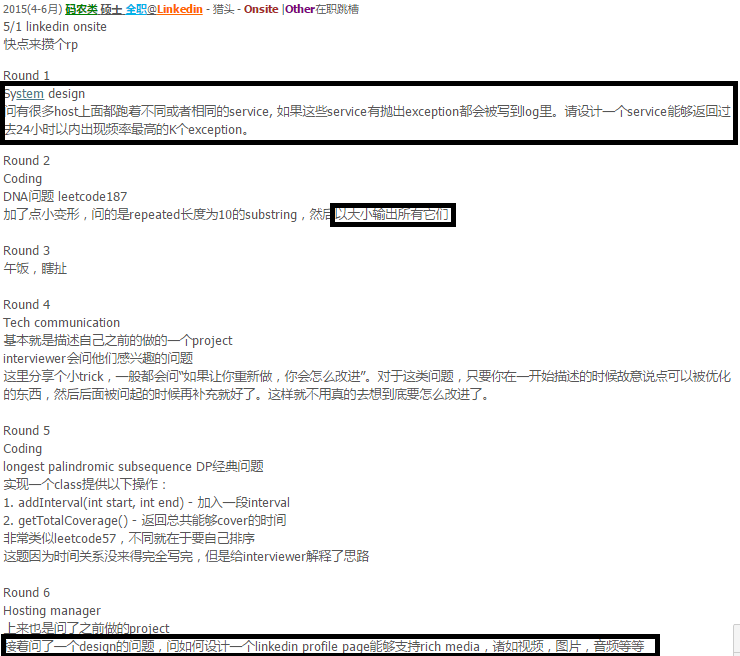
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=133637
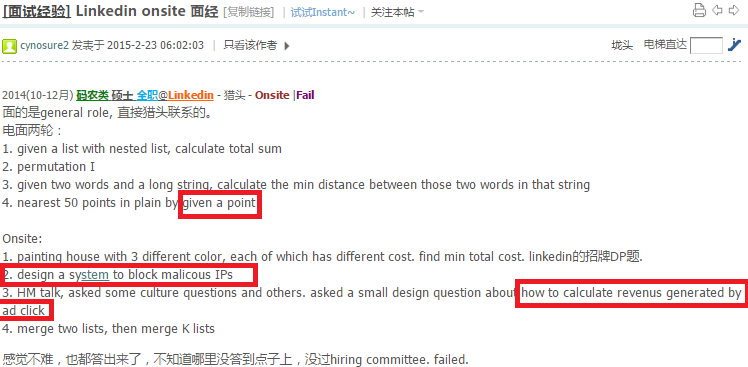
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=118511
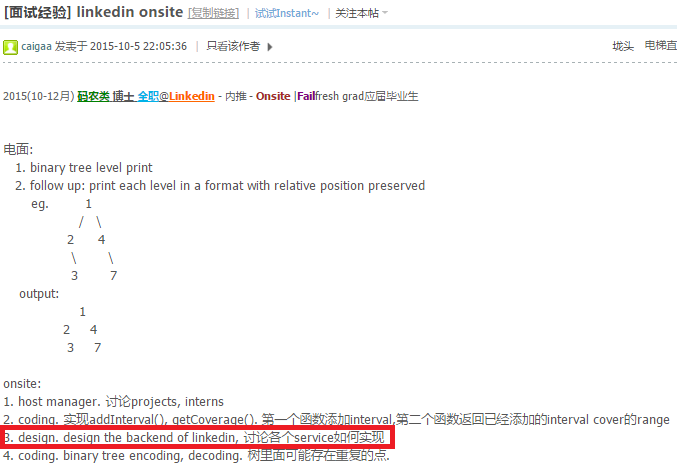
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=143448

http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=129504
- 个人吐血总结Linkedin系统设计题,全是地里的资源,其他公司一样参考
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=175538
You have a potentially very-large set of documents, which are potentially very-large, and contain text. For searching these documents, they’ve been pre-processed into a (very-large) table mapping words to the set of documents that contain each word. E.g. (word) : (documents (referenced by ID) containing that word) Apple: 1, 4, 5, 6, 32 Banana: 5, 6, 7, 9, 32 Cantaloupe: 1, 2, 6 … Clients will pass in a set of words (e.g. {apple, cantaloupe}), and want the set of document IDs that contain all the words. (e.g. {apple, cantaloupe} -> {1, 6}) Design a distributed system to implement this, bearing in mind that the number of documents, the number of words, and the number of document-IDs-per-word are potentially really, really big.
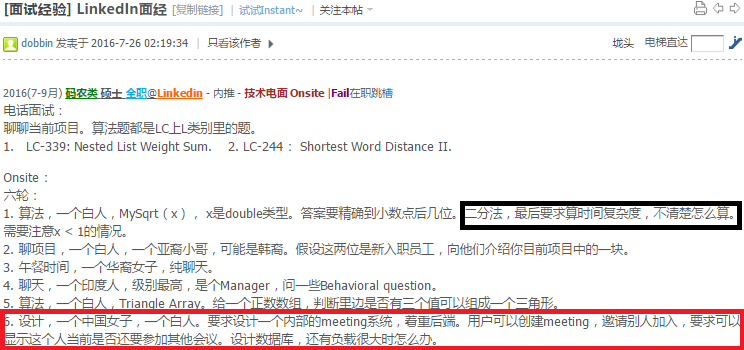
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=197940
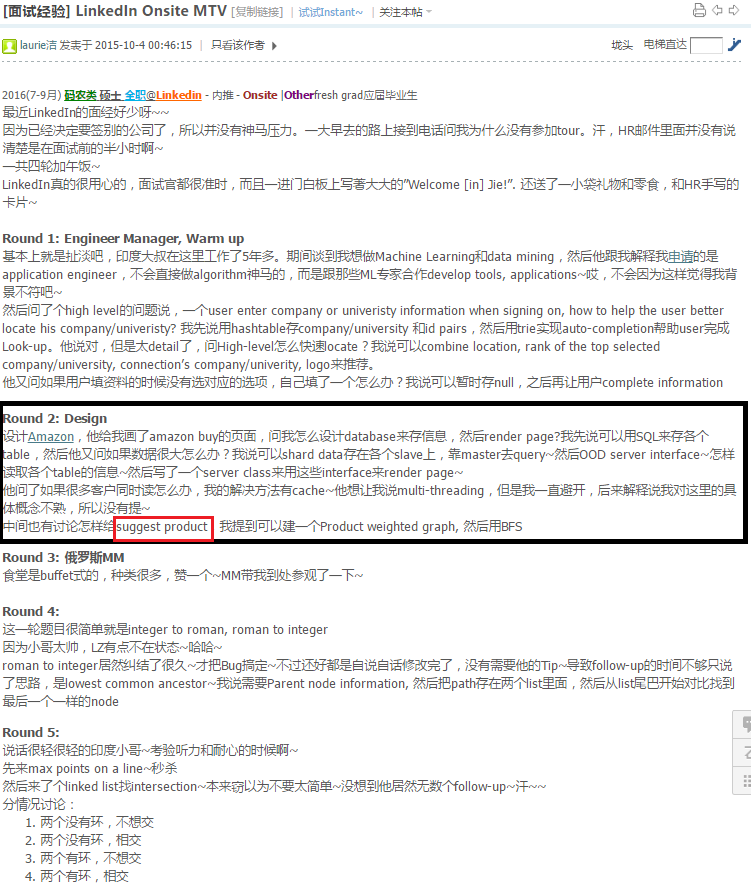
8.6 Design Message Broker
2016(7-9月) 码农类 硕士 全职@Uber - 内推 - Onsite |Failfresh grad应届毕业生 12/14在SF 第一轮白人小哥:聊背景10多分钟,一个简单的DP,一个deepcopy graph,https://leetcode.com/problems/clone-graph/ 第二轮HM:聊背景,聊简历,why uber 第三轮国人小哥:聊简历,实现一个
message broker就是pub/sub model. 第四轮国人小哥:聊简历,实现LRU的拓展LFreqU,优化 第二天就告诉跪了…
http://www.1point3acres.com/bbs/thread-160093-1-1.html
2015(10-12月) 码农类 博士 全职@Uber - 内推 - 技术电面 |Failfresh grad应届毕业生 刚在mitbbs发完,到地里再发一遍.面试题目是system design 之前已经面过2轮拿到了on site,但最初面的那个组招满了.HR说换个组,要加一轮电面.面试官是国人manager. 电面题目是system design, 设计Imessage. 具体点就是说 如果A 给 B 发一个message, B如果分别在iphone和mac或其他apple设备上登录,这些设备都可以收到message.message的数量可以很大,单个message本身也可以很大. 我system design问题准备不足,之前也没想到电面会考这个,说得磕磕巴巴.当时的想法是先构造3个类,user(client),server,message.user之间通过server传递message.user(client)有一个client用来接收收到的信息.如果同一个uer有多个设 备登录,这些设备可以在server端的user帐户里注册,然后server把信息分别发给每个设备. user类里面东西也没想太多,一个记录contacts的hashmap 一个message queue, send,receive function.message类里面就是sender and receiver的user id,还有一个Sting 表示text 面试官提问如果server 挂了怎么办? 言外之意是不用server这个类,如何实现通信.这个问题问得我有点蒙,因为我觉得如果server挂了,A怎么才能知道B在几个设备上登录?犹豫了一会儿,想到以前看过一个设计facebook news feed的题,应该是一个user登录设备后,通知所有他的contacts,我登录了这个设备. 之前我想的事contacts的hashmap key是string代表名字,value是个int表示id就行了,按现在的情况要单独设计一个联系人类,里面至少要存放哪些设备登录了.因为contact也需要有user name, id这些东西,于是我傻B呵呵的把hashmap的 value改成 了user类.然后一想,不对啊,user累里面还有message queue呢,contacts不用这个.电话那边应该是听不下去了,让我别在电脑上敲了,直接说就思路就行了. 然后又问,如果message很多超出你的memory怎么办.我说那就给每个message queue设定一个size,超出就接受不了,同时提醒user清空收件箱.如果可以有server的话,server给每个user在云端分配大一点的空间.还可以在mesage里面加date参数,收件箱 满了,删最早的.接下来让我问问题,然后挂了.
http://www.1point3acres.com/bbs/thread-138172-1-1.html
设计一个Message Broker
http://www.1point3acres.com/bbs/thread-175538-1-1.html
8.6.1 Design Kafka/RabbitMQ
Kafka Broker: Unlike other message system, Kafka broker are stateless. By stateless, means consumer has to maintain how much he has consumed. Consumer maintains it by itself and broker would not do anything. Such design is very tricky and innovative in itself –
It is very tricky to delete message from the broker as broker doesn’t whether consumer consumed the message or not. Kafka solves this problem by using a simple time-based SLA for the retention policy. A message is automatically deleted if it has been retained in the broker longer than a certain period.
This design has a benefit too, as consumer can deliberately rewind back to an old offset and re-consume data. This violates the common contract of a queue, but proves to be an essential feature for many consumers
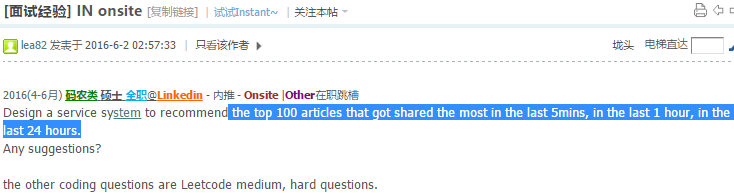
8.7 Top K hottest shared pages in 5min, 1h, 24h
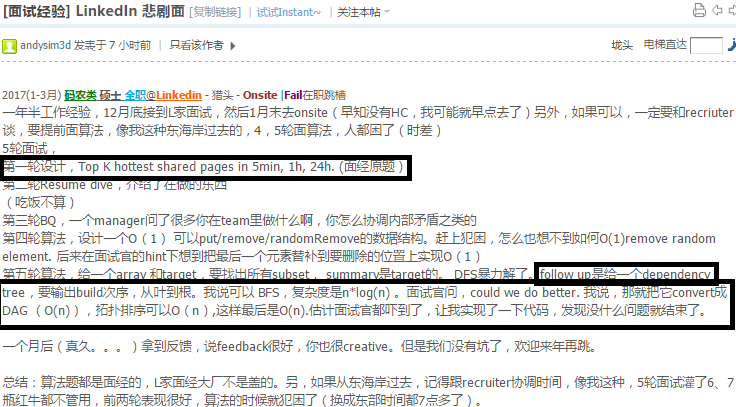
https://leetcode.com/problems/combination-sum
Dependency Tree Build Order类似叶子脱落那题,不同的是不一定是二叉树,而且一个叶节点可以被几个内部节点依赖.
https://www.jiuzhang.com/qa/219/
实现前5分钟,1小时,24小时内分享最多的post的系统
这个题是一个很好的面试题,因为可以从算法和系统两个角度进行考察.
8.7.1 从算法的角度分析
从算法的角度,可以简单的称之为 Top K Frequent Elements in Recent X mins.
算法的角度,本质就是设计一个数据结构,支持给某个key的count+1(有一个post被分享了),给某个key的count-1(有一个分享的计数已经过期了),然后查询Top k.
做法是维护一个有序序列(用链表来维护),每个链表的节点的key是 count,value是list of elements that has this count,也用linked list串起来. 比如 a出现2次,b出现3次,c出现2次,d出现1次.那么这个链表就是:
{3: [b]} --> {2: [a ->c]} --> {1: [d]}然后另外还需要一个hashmap,key是element,value是这个element在链表上的具体位置.
因为每一次的操作都是 count + 1和 count - 1,那么每次你通过hashmap 找到对应的element在数据结构中的位置,+1的话,就是往头移动一格,-1的话,就是往尾巴移动一格.总而言之复杂度都是 O(1).当你需要找 Top K 的时候,也是 O(k)的时间 可以解决的.
这个数据结构来自 LFU 的论文:lfu.pdf
LintCode上有LFU的题, 可以做一下:
8.7.2 从系统设计的角度分析
所以一般来说,你可能首先需要按照 LFU 的思路答出上述的方法.这个就过了第一关,算法关.但是还没结束,这个题还有第二关,那就是系统设计关.上面的算法从算法的角度没办法更优了,每个分享操作都是O(1)的代价,每个求Top K都是O(k)的代价.已经很棒了.但是系统的角度出发,会存在这样一些问题:
如果QPS比较高,比如 1m,这个数据结构因为要加锁才能处理,所以会很慢.
分享的数据本身是分布式的,而不是中心化的,也就是说,比如有1000台web服务器,那么这1000台web服务器的是最先获得哪个帖子被分享的数据的,但是这些数据又都分布在这1000台web服务器中,如果用一个中心化的节点来做这个数据结构的服务,那么很显然这个中心节点会成为瓶颈.
比如这个系统用在twitter 这样的服务中,根据长尾理论,有80%或者更多的帖子连 Top 20% 都排不进去.而通常来说,从产品的角度,我们可能只需要知道 Top 20 最多是 Top 100 的数据就可以了.整个系统浪费了很多时间去统计那些永远不会成为Top 100的数据.
题目的要求是”5分钟,1小时,24小时”,而不是”最近2分零30秒”,“最近31秒”,也存在较大的优化空间
真实产品实时性要求和准确性没有那么高.你需要查询最近5分钟的Top K,结果得出的是最近5分02秒的Top K在产品中是没有太大问题的.
查询Top k 的次数远低于count + 1和 count -1 的次数.
综上所述我们给出一些针对性优化策略:
8.7.3 分布式统计 Distributed: 每隔5~10秒向中心节点汇报数据
也就是说,哪些帖子被分享了多少次这些数据,首先在 web server 中进行一次缓存,也就是说web server的一个进程接收到一个分享的请求之后,比如 tweet_id=100 的tweet被分享了.那么他把这个数据先汇报给web server上跑着的 agent 进程,这个agent进程在机器刚启动的时候,就会一直运行着,他接受在台web server上跑着的若干个web 进程(process) 发过来的 count +1 请求.
这个agent整理好这些数据之后,每隔510秒汇报给中心节点.这样子通过510s的数据延迟,解决了中心节点访问频率过高的问题.这个设计的思路在业界是非常常用的(做这种数据统计服务的都是这么做的).
8.7.4 分阶段统计 Level
__如果我要去算最近5分钟的数据,我就按照1秒钟为一个bucket的单位,收集最近300个buckets里的数据.如果是统计最近1小时的数据,那么就以1分钟为单位,收集最近60个Buckets的数据,如果是最近1天,那么就以小时为单位,收集最近24小时的数据.那么也就是说,当来了一个某个帖子被分享了1次的数据的时候,这条数据被会分别存放在当前时间(以秒为单位),当前分钟,当前小时的三个buckets里,用于服务之后最近5分钟,最近1小时和最近24小时的数据统计.
你可能会疑惑,为什么要这么做呢?这么做有什么好处呢?这样做的好处是,比如你统计最近1小时的数据的时候,就可以随着时间的推移,每次增加当前分钟的所有数据的统计,然后扔掉一小时里最早的1分钟里的所有数据.这样子就不用真的一个一个的+1或者-1了,而是整体的 +X 和 -X.当然,这样做之后,前面的算法部分提出来的数据结构就不work了,但是可以结合下面提到的数据抽样的方法,来减小所有候选 key 的数目,然后用普通的 Top K 的算法来解决问题.__
参考练习题:http://www.lintcode.com/en/problem/top-k-frequent-words/
8.7.5 数据抽样 Sample
可以进行一定程度的抽样,因为那些Top K 的post,一定是被分享了很多很多次的,所以可以进行抽样记录. 如果是5分钟以内的数据,就不抽样,全记录.如果是最近1小时,就可以按照比如 1/100 的概率进行 sample.
8.7.6 缓存 Cache
对于最近5分钟的结果,每隔5s才更新一次. 对于最近1小时的结果,每隔1分钟更新一次. 对于最近24小时的结果,每隔10分钟才更新一次.
用户需要看结果的时候,永远看的是 Cache 里的结果.另外用一个进程按照上面的更新频率去逐渐更新Cache.
以上的这些优化方法,基本都基于一个基本原则:在很多的系统设计问题中,不需要做到绝对精确和绝对实时.特别是这种统计类的问题.如果你刷算法题刷很多,很容易陷入设计一个绝对精确和绝对实时的系统的误区.一般来说面试中不会这么要求,如果这么要求了,那说明考你的是算法,算法才需要绝对准确和实时.
总的来说,这道题考了算法,大数据和系统设计.

8.9 Inverted Index
Create an inverted index with given documents.
Example Given a list of documents with id and content. (class Document)
[
{
"id": 1,
"content": "This is the content of document 1, it's very short"
},
{
"id": 2,
"content": "This is the content of document 2, it's very long.
bilabial bilabial heheh hahaha ..."
},
]Return an inverted index (HashMap with key is the word and value is a list of document ids).
{
"This": [1, 2],
"is": [1, 2],
...
}/**
* Definition of Document:
* class Document {
* public:
* int id;
* string content;
* }
*/
class Solution {
public:
/**
* @param docs a list of documents
* @return an inverted index
*/
map<string, vector<int>> invertedIndex(vector<Document>& docs) {
map<string, vector<int>> ret;
for(int i = 0; i < docs.size(); i++) {
set<string> words = parseWords(docs[i].content);
for(set<string>::iterator iter = words.begin(); iter != words.end(); iter++) {
ret[*iter].push_back(docs[i].id);
}
}
return ret;
}
set<string> parseWords(string &s) {
s = s + " ";
set<string> ret;
int start = -1;
for(int i = 0; i < s.size(); i++) {
if (s[i] == ' ') {
if (start != -1) {
string word = s.substr(start, i - start);
ret.insert(word);
start = -1;
}
} else {
if (start == -1) {
start = i;
}
}
}
return ret;
}
};8.10 Top K Frequent Words (Map Reduce)
Find top k frequent words with map reduce framework.
The mapper’s key is the document id, value is the content of the document, words in a document are split by spaces.
For reducer, the output should be at most k key-value pairs, which are the top k words and their frequencies in this reducer. The judge will take care about how to merge different reducers’ results to get the global top k frequent words, so you don’t need to care about that part.
The k is given in the constructor of TopK class.
Notice
For the words with same frequency, rank them with alphabet.
/**
* Definition of OutputCollector:
* class OutputCollector<K, V> {
* public void collect(K key, V value);
* // Adds a key/value pair to the output buffer
* }
* Definition of Document:
* class Document {
* public int id;
* public String content;
* }
*/Example
Given document A =
lintcode is the best online judge
I love lintcodeand document B =
lintcode is an online judge for coding interview
you can test your code online at lintcodeThe top 2 words and their frequencies should be
lintcode, 4
online, 3// Use Pair to store k-v pair
class Pair {
String key;
int value;
Pair(String k, int v) {
this.key = k;
this.value = v;
}
}
public class TopKFrequentWords {
public static class Map {
public void map(String _, Document value,
OutputCollector<String, Integer> output) {
// Output the results into output buffer.
// Ps. output.collect(String key, int value);
String content = value.content;
String[] words = content.split(" ");
for (String word : words)
if (word.length() > 0)
output.collect(word, 1);
}
}
public static class Reduce {
private PriorityQueue<Pair> Q = null; //
private int k;
private Comparator<Pair> pairComparator = new Comparator<Pair>() {
public int compare(Pair o1, Pair o2) {
if (o1.value != o2.value) {
return o1.value - o2.value;
}
//if the values are equal, compare keys
return o2.key.compareTo(o1.key);
}
};
public void setup(int k) {
// initialize your data structure here
this.k = k;
Q = new PriorityQueue<Pair>(k, pairComparator); //
}
public void reduce(String key, Iterator<Integer> values) {
int sum = 0;
while (values.hasNext()) {
sum += values.next();
}
Pair pair = new Pair(key, sum);
if (Q.size() < k) {
Q.add(pair);
} else {
Pair peak = Q.peek();
if (pairComparator.compare(pair, peak) > 0) {
Q.poll();
Q.add(pair);
}
}
}
public void cleanup(OutputCollector<String, Integer> output) {
// Output the top k pairs <word, times> into output buffer.
// Ps. output.collect(String key, Integer value);
List<Pair> pairs = new ArrayList<Pair>();
while (!Q.isEmpty()) {
pairs.add(Q.poll());
}
// reverse result
int n = pairs.size();
for (int i = n - 1; i >= 0; --i) {
Pair pair = pairs.get(i);
output.collect(pair.key, pair.value);
}
// while (!Q.isEmpty()) {
// Pair pair = Q.poll();
// output.collect(pair.key, pair.value);
// }
}
}
}