Chapter 23 Kafka
23.1 Theory
- What is Kafka?
A stream data platform to serve as a central repository of data streams kafka = Log aggregators + Messaging system.
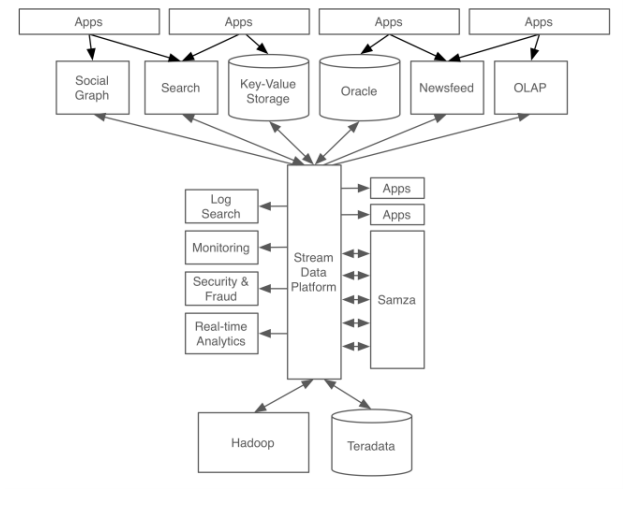
- Kafka为何流行起来
高性能:scalable, high throughput, low latency, fault tolerant
数据保障:high reliable and high available
扩展性:可以和HDFS等结合使用
一个典型的使用kafka的实例是Linkedin对于Job view的架构:
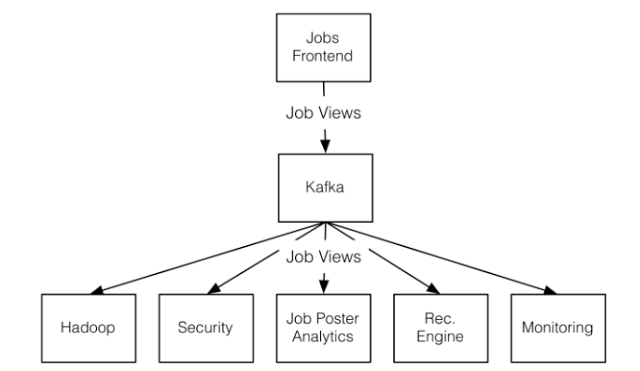
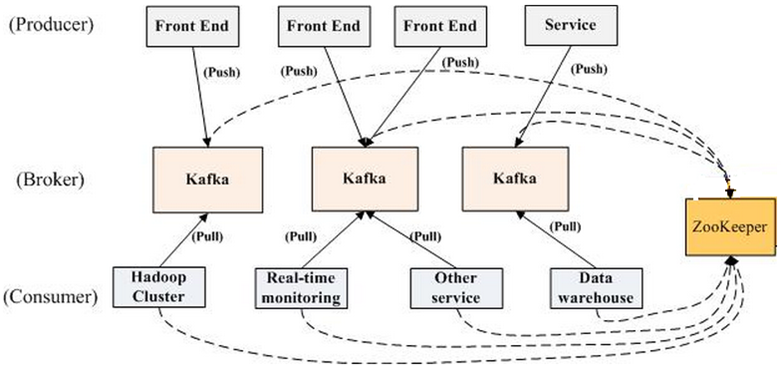
这里web前端是producer不断产生job view的历史记录,这些logs被传到kafka中;而Hadoop Security,Job Poster Analytics等其他系统作为consumers会订阅这些信息,也就是到kafka中读取这些log.
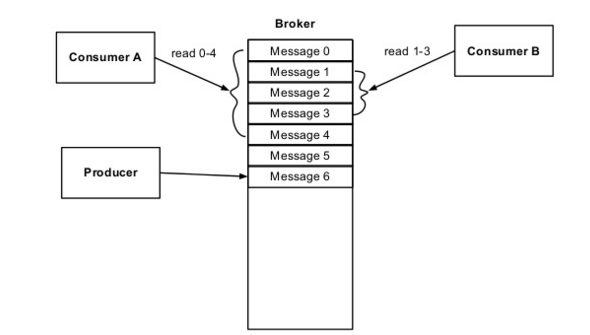
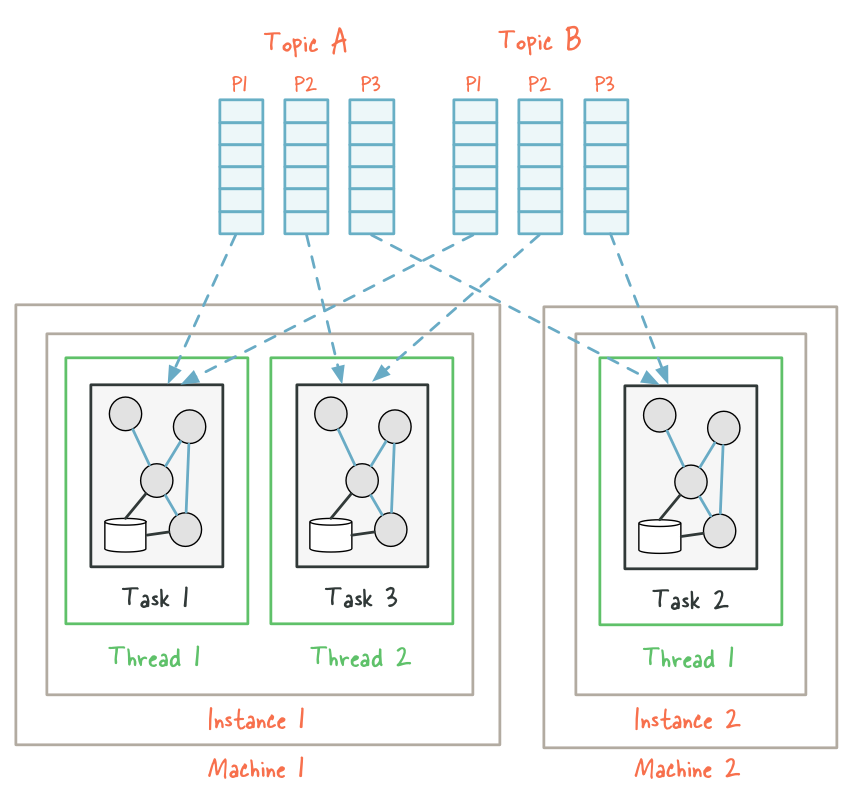
每一个topic在存储时会分为很多个partition如下:
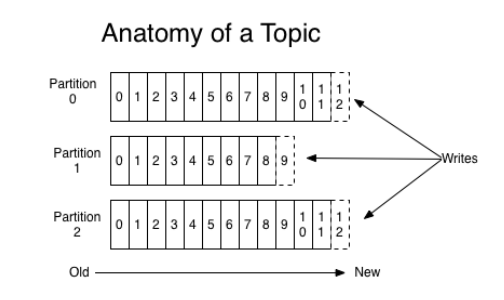
每一个partition都是一个巨型文件,消息按顺序不断append上去.每个partition会在多个broker上有备份.其中一个broker会成为leader,用于协调其它follower备份的复制工作.每个broker都会作为某些partition的leader和一些partition的follower.Partition的存储由很多Segment files组成.每个segment file是1G大小. 每个consumer读取数据的时先用in-memory index(offset)找到segment files然后根据在segment file中的offset找到要读的消息.
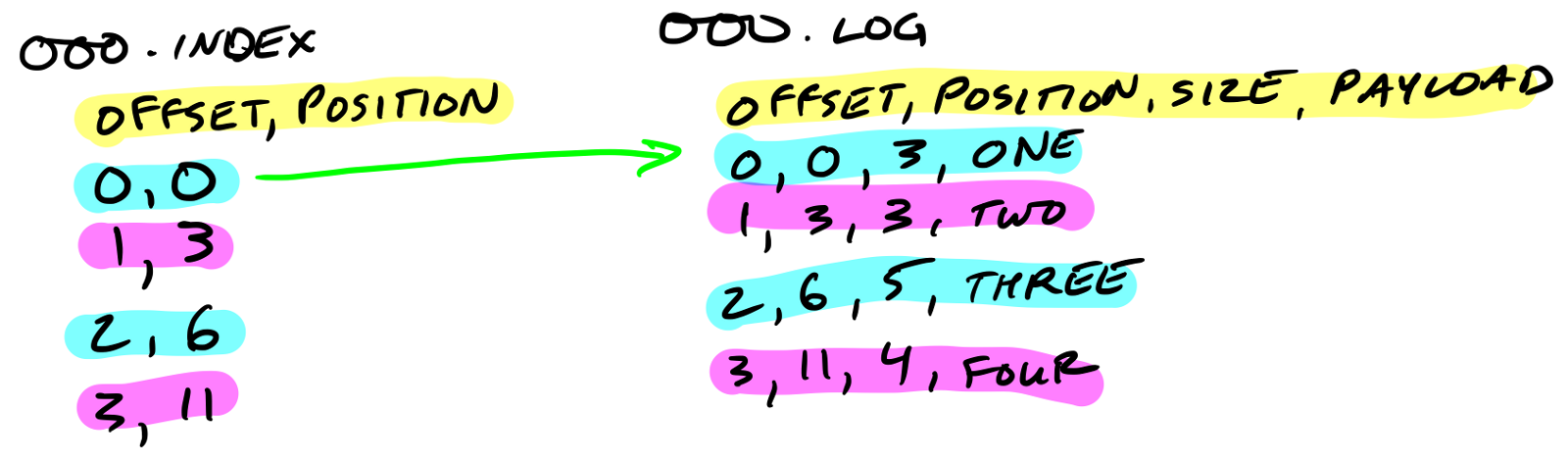
下图左侧是index文件,右侧是segment file.
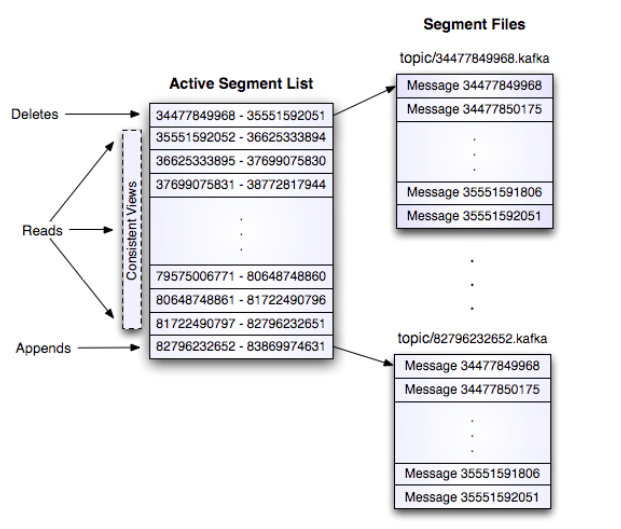
Segment file以他们第一个message的offset来命名,所以当consumer来要message的时候broker只需要在in-memory index里面看,这个message在哪个segment file上面,然后直接到segment file上查找就行.注意message一旦写入partition中就不会再改变.
- Kafka系统调度
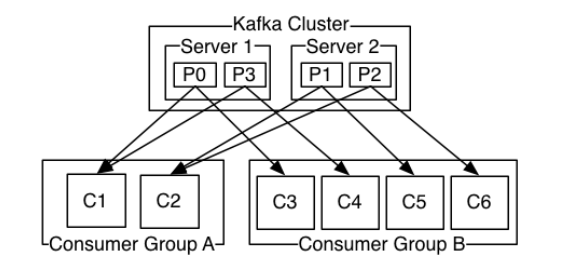
producer方面比较简单,主要就是随机选择broker或按照消息的语义用
partition key和partition function将消息append上去.consumer方面稍微复杂.Kafka运用consumer group来读取消息.每个consumer group有一个或者多个consumer共同订阅一组topics.不同的consumer group会收到一份完整的消息拷贝,但是consumer group内部的每个consumer收到的都是关于这个topic的一部分消息.
kafka是由zookeeper来协作的. 包括发现broker的consumer的增加和移除,出发rebalance,维护订阅的细节和消息的寻址. 每个broker或者consumer启动连接的时候zookeeper会注册这个broker和consumer的信息,当broker挂掉的时候所有partition的注册信息会被自动移除,consumer也是如此.另外每个consumer都会在broker的注册表上建立一个zookeeper watcher, 当broker或者consumer group有变动发生就会发通知给这个consumer.
- Kafka性能特点
- All data are persistent: 就算consumer挂的kafka中的数据也不disappear
- 顺序保障:kafka保障每个partition内部所有消息都是按顺序传输给consumer的.通过配置kafka可以实现 at most once delivery或者 at least once delivery.但是要实现exactly once delivery使用者就得自己写一个implementation了.(?)
- kafka最基本的几个component概念
Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群.
Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发.
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列.
Segment:partition物理上由多个segment组成,下面2.2和2.3有详细说明.
Offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中.partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.
简单来说broker相当于是producer和consumer中间的一个cache,每个partition是对应了一个physical log.
- push vs pull
producer,broker,consumer之间的信息传递有两种方式:push / pull
producer通常积累数条message打包成一个message set通过push的方式发给broker,broker收到message set后就把这些message append到指定的partition也就是log的最后面
broker不会主动的向consumer发送message,而是consumer在需要的时候向broker发送fetch request,批量的把数据pull到consumer的机器上.
The Kafka consumer works by issuing “fetch” requests to the brokers leading the partitions it wants to consume. The consumer specifies its offset in the log with each request and receives back a chunk of log beginning from that position. The consumer thus has significant control over this position and can rewind it to re-consume data if need be.
这个pull message的设计的一个优点就是非常适合real time data consumption,传统message system用push得方式把message发给consumer会有一个问题,就是你不知道consumer那边的处理速度,consumer很可能会被overwhelmed.
以前的系统都是基于offline consumer, consumer都是直接将数据存储到HDFS中, 不会在线分析, 所以通常情况下consumer不会存在被flooded的危险. 在这样的前提下, push更为简单些. 这样的话每个broker需要维护的metadata 非常小,这个后面会讲到对于提高kafka efficiency非常关键
23.2 Efficiency
接下来讲一下kafka如何提高efficiency的:
- 一组messages批量发送, 提高吞吐效率(IO is always much much slower than CPU)
- 使用
filesystem cache, 而非memory cache
- 使用
sendfile, 绕过应用层buffer, 直接将数据从file传到socket (前提是应用逻辑确实不关心发送的内容)
第一点刚才讲了,Kafka生产者和消费者,broker之间的message delivery都是batch process,不必为每一条message单独开辟network connection,同时也提高了throughput
第二点就是避免double cache
一般的应用程序文件传输的步骤如下
1. The operating system reads data from the disk into pagecache in kernel space
2. The application reads the data from kernel space into a user-space buffer
3. The application writes the data back into kernel space into a socket buffer
4. The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network
Kafka把2,3两部都省略了,所有信息直接缓存在文件系统的page cache里面,发送信息的时候直接从page cache里面把信息发送到socket buffer,也就是说Kafka这个应用自身的memory里面不存储任何message cache.
这种设计还有一个好处是利用Linux自身的sendfile API, 这个API也就是一个system call可以高效的把page cache里的数据通过网络传送出去. + TCP_CORK
On Linux and other Unix operating systems, there exists a sendfile API that can directly transfer bytes from a file channel to a socket channel.
- Stateless Broker
提高efficiency的第二点设计是 Stateless broker. 由于consumer采用pull决定的, broker没有必要知道consumer读了多少. 读了多少的offset数据由consumer维护
带来的问题是你不知道consumer什么时候来pull, 那么broker什么时候把message删掉, 他用了个很简单的方法, simple time-based SLA, 过段时间就删, 比如7天.
如果consumer读取失败,consumer只要改一下offset数值,重新pull一下就可以恢复了
23.2.1 Distributed coordination 并发与同步
Kafka的另一个重要设计就是distributed coordination,这个主要是为了解决不同消费者之间如何读取数据,如何协作调度.
为了简化系统复杂度,特别是broker如何实现并发,kafka采取的方法是:取消partition本身的并发性, 只支持partition之间的并发.把并发的任务交给了consumer group来解决.
你可以把一个consumer group抽象为单一的consumer, 每条message我只需要consume一次, 之所以使用group是为了并发操作.而对于不同的group之间, 完全独立的, 一条message可以被每个group都consume一次, 所以group之间是不需要coordination的.问题是同一个group之间的consumer需要coordinate, 来保证只每个message只被consume一次, 而且我们的目标是尽量减少这种coordinate的overhead.这样kafka就可以完全避免locking and state maintenance overhead.broker就不需要处理同步的问题了,节省了大量资源
这样设计最大的问题在于, 单个或少量partition的低速会拖慢整个处理速度, 因为一个partition只能有一个consumer, 其他consumers就算闲着也无法帮你.所以你必须保证每个partition的数据产生和消费速度差不多, 否则就会有问题.
比如必须巧妙的设计partition的数目, 因为如果partition数目不能整除consumer数目, 就会导致不平均.
23.2.2 Zookeeper
Kafka底层通过zookeeper来管理cluster.zookeeper管理以下一些信息
The broker registry (ephemeral) contains the broker’s host name and port, and the set of topics and partitions stored on it.
The consumer registry (ephemeral) includes the consumer group to which a consumer belongs and the set of topics that it subscribes to.
The ownership registry (ephemeral) has one path for every subscribed partition and the path value is the id of the consumer currently consuming from this partition (we use the terminology that the consumer owns this partition).
The offset registry (persistent) stores for each subscribed partition, the offset of the last consumed message in the partition (for Each consumer group).
当broker和consumer发生变化时, 增加或减少, 对应的ephemeral registry会自动跟随变化.但同时, 还会触发consumer的rebalance event, 根据rebalance的结果去修改或增减ownership registry.
这里面只有offset registry是persistent的.
因为consumer 或者broker数量发生变化后,consumer group里面每个consumer对应哪一个partition会变化,zookeeper只要记录每个consumer group的offset,即使rebalance发生了,新的owner consumer只要从这个offset往下读就可以了.所以无论你consumer怎样变化, 只要记录了每个group的在partition上的offset, 就可以保证group内的coordinate.
23.2.3 Rebalance
这是rebalance的算法

算法关键就是这个公式: \(j*N to (j+1)*N - 1\)
其实很简单, 如果有10个partition, 2个consumer, 每个consumer应该handle几个partition?
怎么分配这5个partition, 根据 C在consumer list的顺序, j 根据这个就可以实现kafka的自动负载均衡, 总是保证每个partition都被consumer均匀分布的handle, 但某个consumer挂了,通过rebalance就会有其他的consumer补上.
23.2.4 Kafka Usage at LinkedIn
最后稍微讲下kafka usage at LinkedIn
LinkedIn的这个系统由两个Kafka cluster组成,左边的这个cluster进行real time message consumption,右边的cluster把message批量存储到Hadoop或者其他的data warehouse,用于将来的offline data analysis.
首先在run service的data center跑个Kafka集群用于收集数据.对于这个集群, 我们采用online consumer, 来实时分析. 在离Hadoop集群和数据仓库比较近的地方, 建一个为了offline分析的Kafka集群. 右边的这个cluster本身是左边的cluster的消费者,把数据从live data centers复制过来,然后存储到persistent data center里面,这是一个很有意思的设计.
23.2.5 Kafka特性
- Partitioned
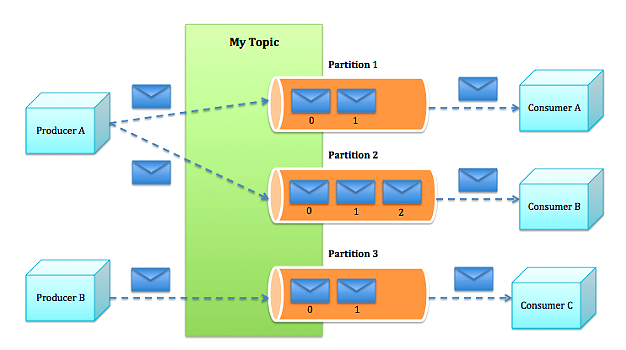
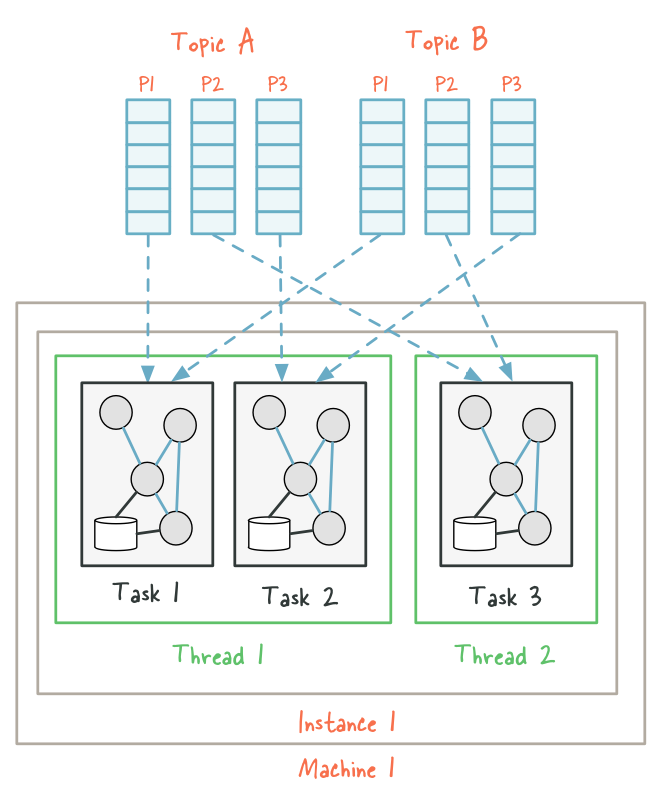
写入每一个topic的信息都会分成多个partition.每一个partition实际上就是一个大log文件.新的信息不断append到这个文件里.那么为什么要有partition呢?
They allow the log to
scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may havemany partitionsso it can handle an arbitrary amount of data.这个是scalable方面的考虑.They act as the unit of
parallelism:每当创建一个topic的时候用户要设定我要给这个topic多少partition.Kafka会并行地往这些partition中写数据.一般来说partition越多写入速度越快.
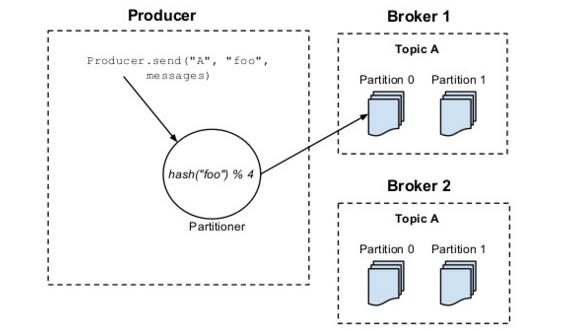
那么message是如何分配到各个partition中的?
最简单的方法就是在各个partition中做round robin.或者用户根据message内容自己写一个partition逻辑也可以.
The producer is responsible for choosing which message to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the message)
下面上一幅图让大家深入理解下partition:
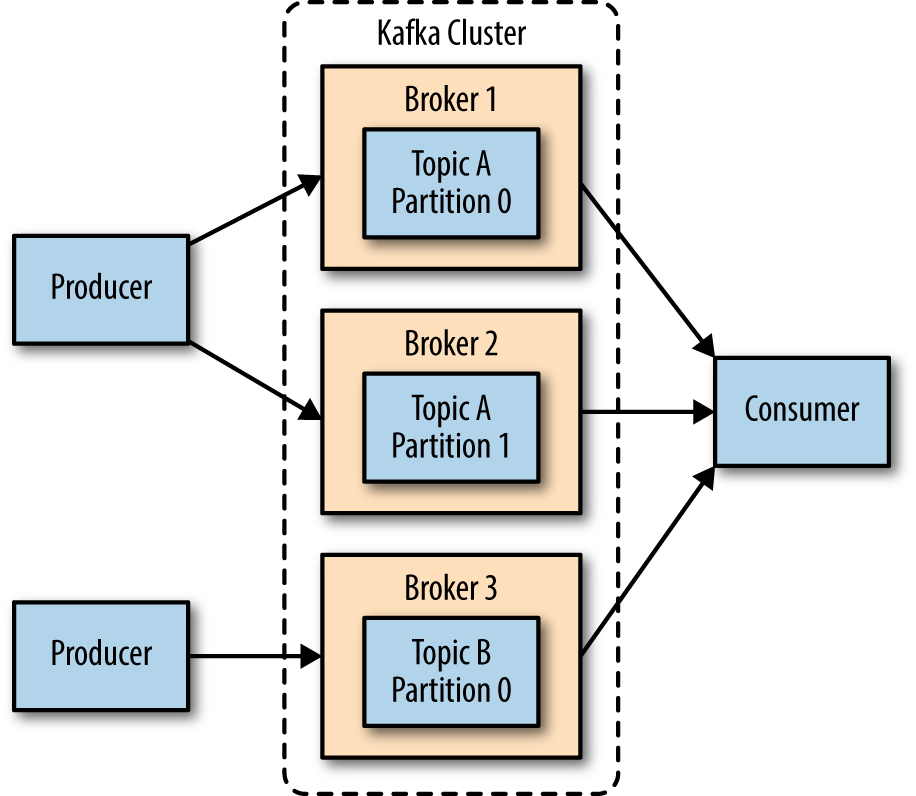
- Distributed
我们一般都会运行多个broker instance. instance之间的协作由zookeeper实现.一个topic的partition分布在多个broker之间.如下图:
- Replicated
每一个partition都会有多个replication的备份.这些备份分布在多个broker之间用于实现fault tolerance.每个partition要由多少个备份是一个用户可调的参数.每个partition选择一个broker作为自己的leader,leader 处理所有的read/write操作follower知识被动复制leader的数据.如果leader fail其中一个follower自动成为下一个leader.不同的partition可以选择不同的server作为leader所以read/write操作基本会平衡分布在各个broker中.
下图很好地表述了replication的概念:
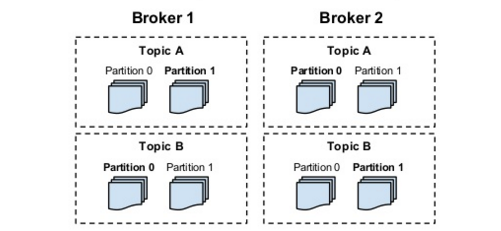
Partitions are replicated, one broker is the leader of a partition, all write must go to the leader. replicas exist for fault tolerance.
23.2.6 Message Delivery Semantics
There are 3 types of message delivery semantics:
At most once: Messages may be lost but are never redelivered.
At least once: Messages are never lost but may be redelivered.
Exactly once: this is what people actually want, each message is delivered once and only once.
About Kafka:
- Kafka guarantees
at-least-oncedelivery by default.
- allows the user to implement at most once delivery by disabling retries on the producer and committing its offset prior to processing a batch of messages.
- Exactly-once delivery requires co-operation with the destination storage system but Kafka provides the
offsetwhich makes implementing this straight-forward.
23.2.7 Others
Caveat:
- partition number can not be easily changed
- a lot of topic can hurt I/O performance
- rebalancing can screw things up
Similar tech:
- activemq
- rabbitmq
- kestrel
- Flume
Related tech:
- goblin
- storm-kafka
- camel-kafka
Disk performance:
The key fact about disk performance is that the throughput of hard drives has been diverging from the latency of a disk seek for the last decade. As a result the performance of linear writes on a JBOD configuration with six 7200rpm SATA RAID-5 array is about 600MB/sec but the performance of random writes is only about 100k/sec—a difference of over 6000X.
- 参考文献
论文:
http://notes.stephenholiday.com/Kafka.pdf
文档:
http://kafka.apache.org/documentation.html
Video:
https://www.youtube.com/watch?v=aJuo_bLSW6s
https://www.youtube.com/watch?v=9RMOc0SwRro
Blog:
http://www.confluent.io/blog/stream-data-platform-1/
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+papers+and+presentations
http://tech.meituan.com/kafka-fs-design-theory.html
https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
https://program-think.blogspot.com/2009/03/producer-consumer-pattern-0-overview.html
http://www.cnblogs.com/fxjwind/archive/2013/03/22/2975573.htmlhttp://www.cnblogs.com/fxjwind/archive/2013/03/19/2969655.html
23.4 Cluster Set Up

- start kafka and zookeeper
for i in `seq 0 2`; do
ssh -n -f u$i "sh -c 'zk_start.sh $KAFKA_HOME/config/zookeeper.properties > ~/zk.log 2>&1 &'";
done
sleep 30 # kafka need to connect to zk port
for i in `seq 0 2`; do
ssh -n -f u$i "sh -c 'start_kafka.sh'";
done#!/bin/bash
export HOSTNAME=`hostname`
kafka-server-start.sh $KAFKA_HOME/config/server.${HOSTNAME}.properties > ~/kafka.${HOSTNAME}.log 2>&1 &$ansible kafka -a "jps"
192.168.0.100 | SUCCESS | rc=0 >>
13380 QuorumPeerMain
15593 Kafka
16303 Jps
192.168.0.102 | SUCCESS | rc=0 >>
12913 Kafka
10982 QuorumPeerMain
13599 Jps
192.168.0.101 | SUCCESS | rc=0 >>
13652 Jps
12967 Kafka
11033 QuorumPeerMain- stop
ansible kafka -a "kafka-server-stop.sh"
ansible kafka -a "zk_stop.sh"- create a topic
kafka-topics.sh --create --zookeeper u0:2080 --replication-factor 3 --partitions 1 --topic stock
#ansible kafka -a "jps"
kafka-topics.sh --describe --zookeeper u0:2080 --topic stock- list topics
kafka-topics.sh --list --zookeeper u0:2080producer:
kafka-console-producer.sh --broker-list u0:9092 --topic stockconsumer:
kafka-console-consumer.sh --bootstrap-server u0:9092 --topic stock --from-beginningdelete topics:
kafka-topics.sh --delete --zookeeper u0:2080 --topic stockhttp://systemdesigns.blogspot.com/2016/01/kafka_6.html
https://www.safaribooksonline.com/library/view/kafka-the-definitive/9781491936153/
- Python Client
Required: https://github.com/edenhill/librdkafka/
10:45 # pip install confluent-kafka
Collecting confluent-kafka
Using cached confluent-kafka-0.11.0.tar.gz
Building wheels for collected packages: confluent-kafka
Running setup.py bdist_wheel for confluent-kafka ... done
Stored in directory: /root/.cache/pip/wheels/16/01/47/3c47cdadbcfb415df612631e5168db2123594c3903523716df
Successfully built confluent-kafka
Installing collected packages: confluent-kafka
Successfully installed confluent-kafka-0.11.0https://www.confluent.io/blog/introduction-to-apache-kafka-for-python-programmers/ https://www.confluent.io/blog/tutorial-getting-started-with-the-new-apache-kafka-0-9-consumer-client/
✔ /opt/share/cppkafka/build [master {origin/master}|✔]
11:34 # make install
[100%] Built target cppkafka
Install the project...
-- Install configuration: ""
-- Installing: /usr/local/lib/libcppkafka.so.0.1
-- Installing: /usr/local/lib/libcppkafka.so
-- Set runtime path of "/usr/local/lib/libcppkafka.so.0.1" to ""
-- Installing: /usr/local/include/cppkafka/buffer.h
-- Installing: /usr/local/include/cppkafka/clonable_ptr.h
-- Installing: /usr/local/include/cppkafka/configuration.h
-- Installing: /usr/local/include/cppkafka/configuration_base.h
-- Installing: /usr/local/include/cppkafka/configuration_option.h
-- Installing: /usr/local/include/cppkafka/consumer.h
-- Installing: /usr/local/include/cppkafka/error.h
-- Installing: /usr/local/include/cppkafka/exceptions.h
-- Installing: /usr/local/include/cppkafka/group_information.h
-- Installing: /usr/local/include/cppkafka/kafka_handle_base.h
-- Installing: /usr/local/include/cppkafka/macros.h
-- Installing: /usr/local/include/cppkafka/message.h
-- Installing: /usr/local/include/cppkafka/message_builder.h
-- Installing: /usr/local/include/cppkafka/metadata.h
-- Installing: /usr/local/include/cppkafka/producer.h
-- Installing: /usr/local/include/cppkafka/topic.h
-- Installing: /usr/local/include/cppkafka/topic_configuration.h
-- Installing: /usr/local/include/cppkafka/topic_partition.h
-- Installing: /usr/local/include/cppkafka/topic_partition_list.h
-- Installing: /usr/local/include/cppkafka/utils/backoff_committer.h
-- Installing: /usr/local/include/cppkafka/utils/backoff_performer.h
-- Installing: /usr/local/include/cppkafka/utils/buffered_producer.h
-- Installing: /usr/local/include/cppkafka/utils/compacted_topic_processor.h
-- Installing: /usr/local/include/cppkafka/utils/consumer_dispatcher.hTo send a message:
✔ ~/sde_web/src [java-book {origin/java-book}|✚ 2]
11:36 # ccat k.cpp
#include <cppkafka/producer.h>
using namespace std;
using namespace cppkafka;
int main() {
// Create the config
Configuration config = {{ "metadata.broker.list", "u1:9092" }};
// Create the producer
Producer producer(config);
// Produce a message!
string message = "hey there!";
producer.produce(MessageBuilder("stock").partition(0).payload(message));
producer.flush();
}
✔ ~/sde_web/src [java-book {origin/java-book}|✚ 2]
11:37 # g++ k.cpp -std=c++1z -lcppkafka && ./a.outPython Consumer:
from confluent_kafka import Consumer, KafkaError
settings = {
'bootstrap.servers': 'u2:9092',
'group.id': 'mygroup2',
'client.id': 'client-2',
'enable.auto.commit': True,
'session.timeout.ms': 6000,
'default.topic.config': {'auto.offset.reset': 'smallest'}
}
c = Consumer(settings)
c.subscribe(['stock'])
try:
while True:
msg = c.poll(0.1)
if msg is None:
continue
elif not msg.error():
print('Received message: {0}'.format(msg.value()))
elif msg.error().code() == KafkaError._PARTITION_EOF:
print('End of partition reached {0}/{1}'
.format(msg.topic(), msg.partition()))
else:
print('Error occured: {0}'.format(msg.error().str()))
except KeyboardInterrupt:
pass
finally:
c.close()- Partitions are split into segments
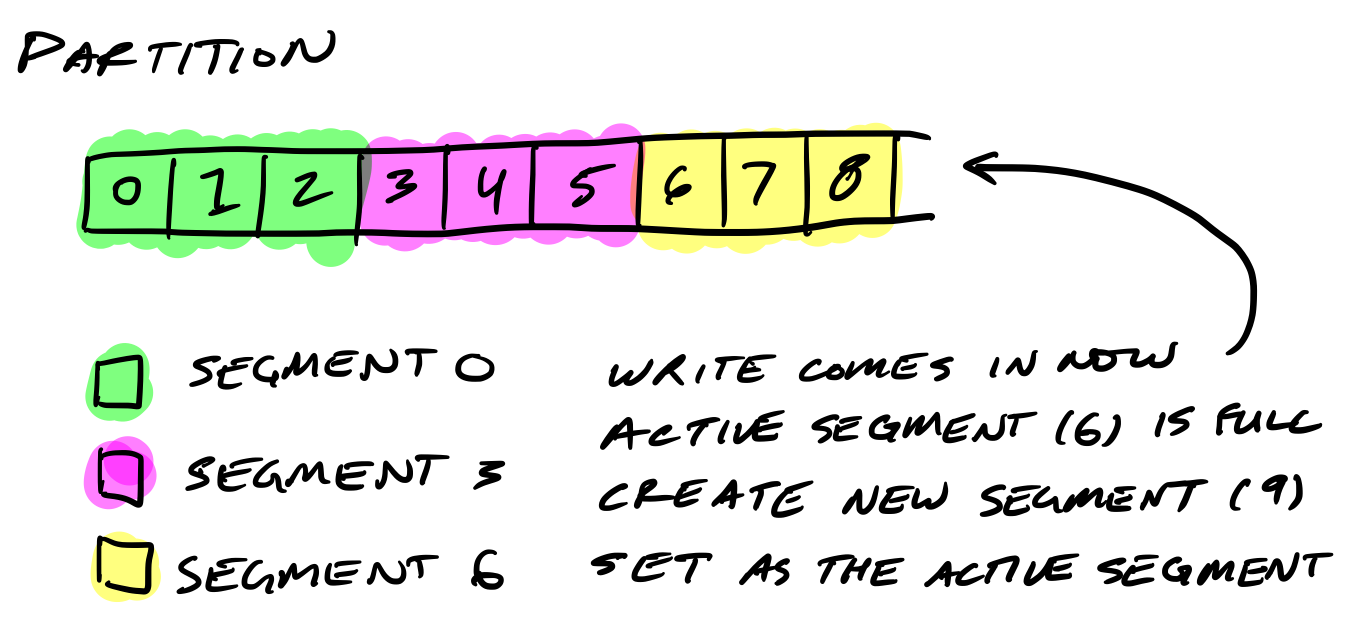
Kafka needs to regularly find the messages on disk that need purged. With a single very long file of a partition’s messages, this operation is slow and error prone. To fix that (and other problems we’ll see), the partition is split into segments.
When Kafka writes to a partition, it writes to a segment - the active segment. If the segment’s size limit is reached, a new segment is opened and that becomes the new active segment.
Segments are named by their base offset. The base offset of a segment is an offset greater than offsets in previous segments and less than or equal to offsets in that segment.
On disk, a partition is a directory and each segment is an index file and a log file.
[1500][u0][0][-bash](11:59:11)[0](root) : ~/kafka-logs
$ll
total 100
drwxr-xr-x 20 root root 4096 Feb 10 11:59 ./
drwx------ 19 root root 4096 Feb 10 11:59 ../
-rw-r--r-- 1 root root 54 Feb 10 10:55 cleaner-offset-checkpoint
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-1/
drwxr-xr-x 2 root root 4096 Feb 10 10:56 __consumer_offsets-10/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-13/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-16/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-19/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-22/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-25/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-28/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-31/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-34/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-37/
drwxr-xr-x 2 root root 4096 Feb 10 10:56 __consumer_offsets-4/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-40/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-43/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-46/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-49/
drwxr-xr-x 2 root root 4096 Feb 10 10:45 __consumer_offsets-7/
-rw-r--r-- 1 root root 0 Jan 19 00:38 .lock
-rw-r--r-- 1 root root 4 Feb 10 11:58 log-start-offset-checkpoint
-rw-r--r-- 1 root root 54 Jan 19 00:38 meta.properties
-rw-r--r-- 1 root root 425 Feb 10 11:58 recovery-point-offset-checkpoint
-rw-r--r-- 1 root root 425 Feb 10 11:59 replication-offset-checkpoint
drwxr-xr-x 2 root root 4096 Feb 10 10:50 stock-0/
[1501][u0][0][-bash](11:59:13)[0](root) : ~/kafka-logs
$tree stock-0/
stock-0/
├── 00000000000000000029.index
├── 00000000000000000029.log
├── 00000000000000000029.snapshot
├── 00000000000000000029.timeindex
└── leader-epoch-checkpoint
0 directories, 5 files- Segment logs are where messages are stored.
Each message is its value, offset, timestamp, key, message size, compression codec, checksum, and version of the message format.
The data format on disk is exactly the same as what the broker receives from the producer over the network and sends to its consumers. This allows Kafka to efficiently transfer data with zero copy.
[734][u1][0][-bash](14:27:10)[0](root) : ~/kafka-logs
$kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files stock-0/00000000000000000000.log
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/share/apache-hive-2.3.2-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/share/apache-cassandra-3.11.1/lib/logback-classic-1.1.3.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/share/apache-storm-1.1.1/lib/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/share/kafka_2.11-1.0.0/libs/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Dumping stock-0/00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 CreateTime: 1517166644375 isvalid: true keysize: -1 valuesize: 5 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: hello
offset: 1 position: 73 CreateTime: 1517166647047 isvalid: true keysize: -1 valuesize: 5 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: world
offset: 2 position: 146 CreateTime: 1517167605005 isvalid: true keysize: -1 valuesize: 36 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 今夜還忹著風想起你好溫柔
offset: 3 position: 146 CreateTime: 1517167605012 isvalid: true keysize: -1 valuesize: 30 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 有你的日孿分外的輕濾
offset: 4 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 36 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 也丿是無影蹤忪是想你太濃
offset: 5 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 30 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 怎么會無時無刻把你夢
offset: 6 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 33 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 愛的路上有你我并丿寂寞
offset: 7 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 39 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 你尿我那么的好這次真的丿忌
offset: 8 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 33 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 也許我應該好好把你擿有
offset: 9 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 27 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 就僿你一直為我守候
offset: 10 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 28 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 親愛的人 親密的愛人
offset: 11 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 36 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 謿謿你這么長的時間陪著我
offset: 12 position: 146 CreateTime: 1517167605013 isvalid: true keysize: -1 valuesize: 28 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 親愛的人 親密的愛人
offset: 13 position: 640 CreateTime: 1517167606542 isvalid: true keysize: -1 valuesize: 36 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 這是我一生中最興奮的時分- Segment indexes map message offsets to their position in the log
The segment index maps offsets to their message’s position in the segment log.
The index file is memory mapped, and the offset look up uses binary search to find the nearest offset less than or equal to the target offset.
The index file is made up of 8 byte entries, 4 bytes to store the offset relative to the base offset and 4 bytes to store the position. The offset is relative to the base offset so that only 4 bytes is needed to store the offset. For example: let’s say the base offset is 10000000000000000000, rather than having to store subsequent offsets 10000000000000000001 and 10000000000000000002 they are just 1 and 2.
- Kafka wraps compressed messages together
Producers sending compressed messages will compress the batch together and send it as the payload of a wrapped message. And as before, the data on disk is exactly the same as what the broker receives from the producer over the network and sends to its consumers.

- Let’s Review
Now you know how Kafka storage internals work:
Partitions are Kafka's storage unit
Partitions are split into segments
Segments are two files: its log and index
Indexes map each offset to their message's position in the log, they're used to look up messages
Indexes store offsets relative to its segment's base offset
Compressed message batches are wrapped together as the payload of a wrapper message
The data stored on disk is the same as what the broker receives from the producer over the network and sends to its consumers
https://kafka.apache.org/intro
设计文档:
http://kafka.apache.org/documentation.html#design
分布式延迟消息队列
http://zhangyp.net/rabbitmq-delayqueue/
关于淘点点面试中碰到的架构问题
23.5 Kafka vs. RabbitMQ


今天面试被问到为什kafka比rabbitmq快, 我答不出来
[大侠]Lucius 3/13/2017 10:39:41 PM
kafka吞吐量比Rabbitmq高啊.RabbitMQ只有一个队列,这个队列是在一个broker上的.而Kafka的topic是分区的也就是分布式的.
[大侠]Lucius 3/13/2017 10:41:15 PM
Kafka 虽然使用磁盘存储,但是做了很多优化,使得它的性能并比使用内存的低.这些优化包括:磁盘顺序读取、Message Chunk、Zero copy
[大侠] python 3/13/2017 10:41:46 PM
推荐本书吧
[大侠]Lucius 3/13/2017 10:42:32 PM
有时候当性能瓶颈是网络时,还可以对消息进行压缩,积累到一定消息量或每个一定时间发送一次
10:42:39 PM
[掌门]Mr.crowley 3/13/2017 10:42:39 PM
顺序写磁盘,顺序读性能比较高
[大侠]Lucius 3/13/2017 10:42:51 PM
减少太多I/O导致的性能问题
[大侠] python 3/13/2017 10:54:05 PM
rabbitmq,producer发给server,然后被consumer消费完之后,消息还能确认吗???
[大侠]Lucius 3/13/2017 10:53:35 PM
能
[大侠] python 3/13/2017 10:54:05 PM
怎么确认的??
[大侠]Lucius 3/13/2017 10:54:25 PM
consumer发给server的确认称为acknowledge server发给producer的确认称为confirm
[掌门]Mr.crowley 3/13/2017 10:54:53 PM
pull模式没必要确认给broker啊
23.6 Install
- Figure out what version of Kafka you want to use from http://kafka.apache.org/downloads.html. For ease, download the binary release for the latest stable version.
- Unpack the file from the previous step to /opt/kafka/
- Edit /opt/kafka/config/zookeeper.properties (the important configuration items are: dataDir for where the ZooKeeper data will live).
- Edit /opt/kafka/config/server.properties (the important configuration items are: log.dirs is the location of the Kafka topics).
- Set the
JAVA_HOMEenvironment variable to the location of a JRE/JDK installation. Add$JAVA_HOME/binto the PATH environment variable. - Start the ZooKeeper service first in the background using:
/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties & - Start the Kafka broker in the background using:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties &- Create a test topic using a command like this and entering your own topic name in
<topic name>:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 \
--replication-factor 1 --partitions 1 --topic <topic name>23.7 Kafka connect for streaming processing
23.7.1 What’s kafka connect and what are kafka streams ?
http://www.confluent.io/blog/hello-world-kafka-connect-kafka-streams
http://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple
23.7.2 Kafka connect
http://docs.confluent.io/3.0.0/connect/index.html
- Tool/lib for streaming data from or to kafka.
- Not intended for stream processing, more for streaming, as in copying data between kafka and different data stores
- Simple toll - can run as a standalone or a distributed service
- Use cases :
- With Spark, Connect itself is not an ETL software, but as it preserves all kafka guarentees, that you wouldn’t always get from Spark’sKafka connector, makes it an ideal kafka connector for stream processing using spark.
- Uber has 2 clusters, one for copying and other for processing. One job on cluster 1 (using connectors) to populate kafka, and other for processing streams reading from kafka.
- With Spark, Connect itself is not an ETL software, but as it preserves all kafka guarentees, that you wouldn’t always get from Spark’sKafka connector, makes it an ideal kafka connector for stream processing using spark.
- Design
- 2 main abstractions Tasks and Connectors.
- Connectors
- SourceConector(import data into kafka)
- SinkConnector(export data out of kafka)
- SourceConector(import data into kafka)
- Tasks - SourceTask, SinkTask
- Connector breaks its job into tasks that can be run on workers
- Workers - standalone or distributed
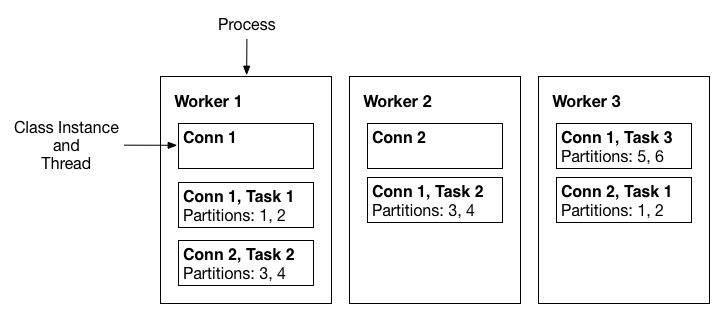
- ships with jdbc and hdfs connectors
- 2 main abstractions Tasks and Connectors.
23.7.3 Kafka Streams
http://docs.confluent.io/3.0.0/streams/index.html
http://docs.confluent.io/3.0.0/_images/streams-architecture-example-01.png
http://docs.confluent.io/3.0.0/_images/streams-architecture-example-02.png
Example
- TopK from a stream
- Wordcount
 http://www.infoq.com/cn/articles/kafka-analysis-part-1
http://www.infoq.com/cn/articles/kafka-analysis-part-1
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证).
23.8 Flume
Flume is to collect, aggreate and move large log data.
Source can be tail -f in the simplest case.
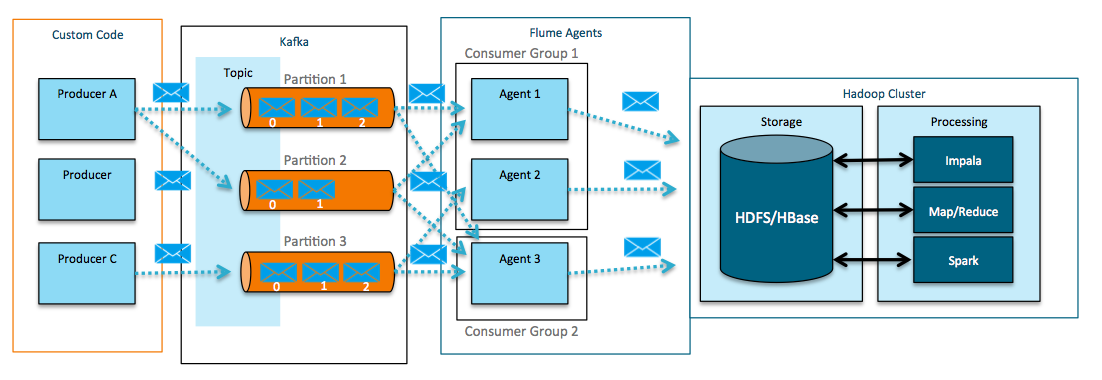
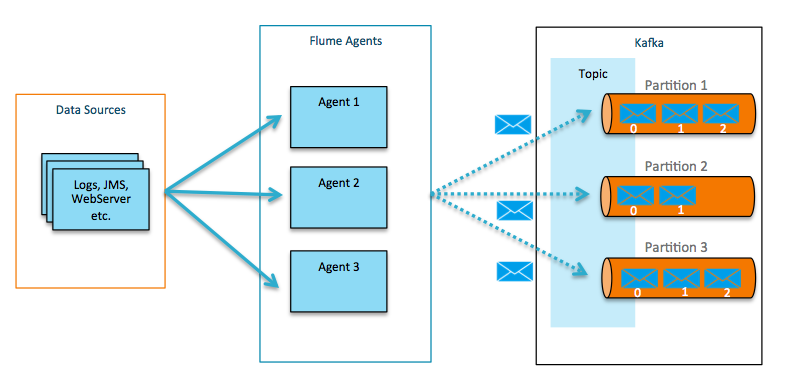
Flume can act as a both a consumer (above) and producer for Kafka (below).
https://blog.cloudera.com/blog/2014/11/flafka-apache-flume-meets-apache-kafka-for-event-processing/
- Start flume
flume-ng agent --conf conf --conf-file /opt/flume/conf/avro.properties --name a1 -Dflume.root.logger=INFO,LOGFILE- To stop Flume agents, use the Linux kill command.
$ps -ef | gp flum[e] |awk '{print $2}'
26800
[517][ubuntu][1][-bash](17:41:55)[0](root) : ~
$kill -9 2680023.8.1 Flume vs Kafka
https://www.linkedin.com/pulse/flume-kafka-real-time-event-processing-lan-jiang
Flume and Kakfa both can act as the event backbone for real-time event processing. Some features are overlapping between the two and there are some confusions about what should be used in what use cases. This post tries to elaborate on the pros and cons of both products and the use cases that they fit the best.
Flume and Kafka are actually two quite different products. Kafka is a general purpose publish-subscribe model messaging system, which offers strong durability, scalability and fault-tolerance support. It is not specifically designed for Hadoop. Hadoop ecosystem is just be one of its possible consumers.
Flume is a distributed, reliable, and available system for efficiently collecting, aggregating, and moving large amounts of data from many different sources to a centralized data store, such as HDFS or HBase. It is more tightly integrated with Hadoop ecosystem. For example, the flume HDFS sink integrates with the HDFS security very well. So its common use case is to act as a data pipeline to ingest data into Hadoop.
{kind=link}
{kind=link}
{kind=link}
23.9 Log4j 2
https://segmentfault.com/a/1190000006670837
Flume Appender: https://logging.apache.org/log4j/2.x/manual/appenders.html#FlumeAppender
Cassandra: https://logging.apache.org/log4j/2.x/manual/appenders.html#CassandraAppender
ElasticSearch: https://bitbucket.org/inemar/utility-log4j2-elasticsearch
https://segmentfault.com/a/1190000006661628
Log4j2里面如何使用Appender呢?
23.11 ZMQ
https://tomasz.janczuk.org/2015/09/from-kafka-to-zeromq-for-log-aggregation.html
23.11.1 Kafka vs ZeroMQ
Generally speaking comparing Kafka to ZeroMQ is like comparing apples to oranges, as Kafka’s functional scope and level of abstraction are fundamentally different from ZeroMQ’s. However, it is a valid comparison from the perspective of the requirements of any problem at hand to inform a choice of one technology over the other. So let’s compare Kafka to ZeroMQ from the perspective of our problem of real-time log aggregation.
- Topics and messages
When consolidating logs, it was important to us to partition logs into distinct logical streams. In our case we had two classes of streams: system-wide, administrative logs, and logs specific to a particular tenant running in our multi-tenant webtask environment.
Kafka has a first class notion of a topic, a key concept in many messaging systems. Topics can be published to and subscribed to, and are managed separately in terms of configuration and delivery guarantees. Kafka’s topics mapped very well onto our requirement to support distinct logical log streams.
ZeroMQ does not have a first class notion of a topic, yet it does have a first class concept of a subscription filter. Subscription filters let you decide which messages you are interested in receiving based on the prefix match on any otherwise opaque message. This feature combined with the support for multi-frame messages allowed us to easily and elegantly express the same semantics as Kafka topics in the context of our requirements. The first frame of every message contains the logical name of the stream, and the second frame the actual log record. We then configure ZeroMQ to do an exact match on the first frame so that we only receive the entries we care about.
- Delivery guarantees
Kafka supports at-least-once delivery guarantees, ZeroMQ does not. ZeroMQ will drop messages if there are no subscribers listening (or subscribers fall behind) and the in-memory buffers of configurable size fill up.
While this lack of basic delivery guarantees would be a big no-no for some applications traditionally associated with message brokers, we felt it was a very pragmatic approach in the context of log consolidation, and a good trade off against overall complexity of the system required to support delivery guarantees. More on that in the Stability section below.
- Durable state and performance
Kafka stores messages on disk in order to support its delivery guarantees, as well as the ability to go back in time - replay messages that had already been consumed. ZeroMQ only ever stores messages in limited in-memory buffers, and does not support replay.
As a result of this difference, despite Kafka being known to be super fast compared to other message brokers (e.g. RabbitMQ), it is necessarily slower than ZeroMQ given the need to go to disk and back.
Doing work always takes more effort than not doing it.
Since we’ve decided to scope out access to historical logs from the problem we were trying to solve and focus only on real-time log consolidation, that feature of Kafka became an unnecessary penalty without providing any benefits.
- Stability
Stability was the key aspect of Kafka we were unhappy with after a year long journey with it.
An HA deployment of Kafka requires an HA deployment of zookeeper, which Kafka uses to coordinate distributed state and configuration. As I explained before, we’ve experienced a number of stability issues with this stateful cluster maintaining consistency through outages such as VM recycle. Some serious engineering time was going into reacting to issues, tracking them down, and subsequent stabilization attempts. Not to mention the cost that every downtime incurred.
With the transition to ZeroMQ, this entire layer of complexity was gone overnight. There are no moving parts to configure, deploy, manage, and support in our ZeroMQ design - all state is transient between in-memory data and the network.
23.13 Sendfile
1、认识sendfile
nginx大家都再熟悉不过了,这里就不详细介绍了.再nginx众多参数中有个sendfile,想必大家也都用过.但是其中的作用并不是那么简单,下面就开始深入学习下sendfile
- 传统的文件传输方式
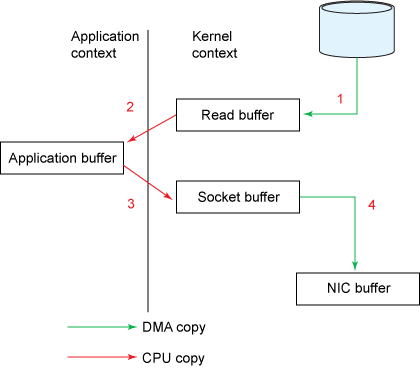
传统的数据拷贝方式
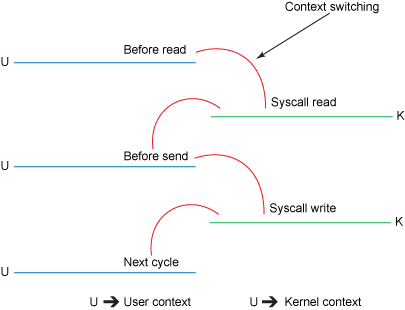
Context Switch
read() 调用(参见 图 2)引发了一次从用户模式到内核模式的上下文切换.在内部,发出 sys_read()(或等效内容)以从文件中读取数据.直接内存存取(direct memory access,DMA)引擎执行了第一次拷贝(参见 图 1),它从磁盘中读取文件内容,然后将它们存储到一个内核地址空间缓存区中.
所需的数据被从读取缓冲区拷贝到用户缓冲区,read() 调用返回.该调用的返回引发了内核模式到用户模式的上下文切换(又一次上下文切换).现在数据被储存在用户地址空间缓冲区.
send() 套接字调用引发了从用户模式到内核模式的上下文切换.数据被第三次拷贝,并被再次放置在内核地址空间缓冲区.但是这一次放置的缓冲区不同,该缓冲区与目标套接字相关联..
send() 系统调用返回,结果导致了第四次的上下文切换.DMA 引擎将数据从内核缓冲区传到协议引擎,第四次拷贝独立地、异步地发生 .
Zero Copy
使用中间内核缓冲区(而不是直接将数据传输到用户缓冲区)看起来可能有点效率低下.但是之所以引入中间内核缓冲区的目的是想提高性能.在读取方面使用中间内核缓冲区,可以允许内核缓冲区在应用程序不需要内核缓冲区内的全部数据时,充当 “预读高速缓存(readahead cache)” 的角色.这在所需数据量小于内核缓冲区大小时极大地提高了性能.在写入方面的中间缓冲区则可以让写入过程异步完成.
不幸的是,如果所需数据量远大于内核缓冲区大小的话,这个方法本身可能成为一个性能瓶颈.数据在被最终传入到应用程序前,在磁盘、内核缓冲区和用户缓冲区中被拷贝了多次.
零拷贝通过消除这些冗余的数据拷贝而提高了性能.(零拷贝的方法有很多,这里只针对sendfile进行详细介绍了)
23.13.1 深入学习sendfile
Linux系统使用man sendfile,查看sendfile原型如下:
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);参数特别注意的是:in_fd必须是一个支持mmap函数的文件描述符(The in_fd argument must correspond to a file which supports mmap(2)-like operations (i.e., it cannot be a socket)),也就是说必须指向真实文件,must not be socket描述符和管道.out_fd必须是一个socket描述符.由此可见sendfile几乎是专门为在网络上传输文件而设计的.
sendfile函数在两个文件描述符之间直接传递数据(完全在内核中操作,传送),从而避免了内核缓冲区数据和用户缓冲区数据之间的拷贝,操作效率很高,被称之为零拷贝.
sendfile系统调用则提供了一种减少以上多次copy,提升文件传输性能的方法.
1、系统调用sendfile()通过DMA把硬盘数据拷贝到kernel buffer,然后数据被 kernel 直接拷贝到另外一个与socket相关的 kernel buffer.这里没有 user mode 和 kernel mode 之间的切换,在kernel中直接完成了从一个 buffer 到另一个 buffer 的拷贝.
2、DMA 把数据从 kernel buffer 直接拷贝给协议栈,没有切换,也不需要数据从 user mode 拷贝到 kernel mode,因为数据就在 kernel 里.