Chapter 11 Design Twitter
Twitter Screenshot
11.1 Naive Version
https://leetcode.com/problems/design-twitter
Design a simplified version of Twitter where users can post tweets, follow/unfollow another user and is able to see the 10 most recent tweets in the user’s news feed. Your design should support the following methods:
postTweet(userId, tweetId): Compose a new tweet.
getNewsFeed(userId): Retrieve the 10 most recent tweet ids in the user’s news feed. Each item in the news feed must be posted by users who the user followed or by the user herself. Tweets must be ordered from most recent to least recent.
follow(followerId, followeeId): Follower follows a followee.
unfollow(followerId, followeeId): Follower unfollows a followee.
Example:
Twitter twitter = new Twitter();
// User 1 posts a new tweet (id = 5).
twitter.postTweet(1, 5);
// User 1's news feed should return a list with 1 tweet id -> [5].
twitter.getNewsFeed(1);
// User 1 follows user 2.
twitter.follow(1, 2);
// User 2 posts a new tweet (id = 6).
twitter.postTweet(2, 6);
// User 1's news feed should return a list with 2 tweet ids -> [6, 5].
// Tweet id 6 should precede tweet id 5 because it is posted after tweet id 5.
twitter.getNewsFeed(1);
// User 1 unfollows user 2.
twitter.unfollow(1, 2);
// User 1's news feed should return a list with 1 tweet id -> [5],
// since user 1 is no longer following user 2.
twitter.getNewsFeed(1);http://blog.csdn.net/mebiuw/article/details/51781415
public class Twitter {
// 需要定义一个表示每一条状态的,主要是时间id,以及重新定义排序的
class Tweet {
public int time;
public int tweetId;
public Tweet(int tweetId,int time){
this.time = time;
this.tweetId = tweetId;
}
}
int timeStamp ;
// 每个人发布的推特信息
HashMap<Integer,List<Tweet>> timelines;
// 人际关系,会重复follow所以要用set
HashMap<Integer,HashSet<Integer>> relations;
// Initialize your data structure here.
public Twitter() {
this.timelines = new HashMap<Integer,List<Tweet>>();
this.relations = new HashMap<Integer,HashSet<Integer>>();
}
// Compose a new tweet.
public void postTweet(int userId, int tweetId) {
if(timelines.containsKey(userId) == false){
timelines.put(userId, new ArrayList<Tweet>());
}
timelines.get(userId).add(new Tweet(tweetId,timeStamp++));
}
//Retrieve the 10 most recent tweet ids in the user's news feed.
//Each item in the news feed must be posted by users who the user
//followed or by the user herself. Tweets must be ordered from most
//recent to least recent.
//全部都选前10,然后按照时间戳排序,注意要选择自己的和别人的
public List<Integer> getNewsFeed(int userId) {
HashSet<Integer> followees = relations.get(userId);
List<Tweet> candidates = new ArrayList<Tweet>();
//分别选择,可以选择每个人的前10条就好
List<Tweet> timeline = timelines.get(userId);
if(timeline!=null){
for(int i=timeline.size()-1;i>=Math.max(0,timeline.size()-10);i--){
candidates.add(timeline.get(i));
}
}
if(followees != null){
for(Integer followee:followees){
timeline = timelines.get(followee);
if(timeline == null)
continue;
for(int i=timeline.size()-1;i>=Math.max(0,timeline.size()-10);i--){
candidates.add(timeline.get(i));
}
}
}
Collections.sort(candidates, new Comparator<Tweet>(){
public int compare(Tweet o1, Tweet o2) {
return o2.time - o1.time;
}
});
List<Integer> list = new ArrayList<Integer>();
for(int i=0;i<Math.min(10,candidates.size());i++){
list.add(candidates.get(i).tweetId);
}
return list;
}
//Follower follows a followee. If the operation is invalid, it should be a no-op.
public void follow(int followerId, int followeeId) {
if(followerId == followeeId) return;
if(relations.containsKey(followerId)==false){
relations.put(followerId,new HashSet<Integer>());
}
relations.get(followerId).add(followeeId);
}
//Follower unfollows a followee. If the operation is invalid, it should be a no-op.
public void unfollow(int followerId, int followeeId) {
HashSet<Integer> list = relations.get(followerId);
if(list == null) return ;
list.remove(followeeId);
}
}
/* Your Twitter object will be instantiated and called as such:
* Twitter obj = new Twitter();
* obj.postTweet(userId,tweetId);
* List<Integer> param_2 = obj.getNewsFeed(userId);
* obj.follow(followerId,followeeId);
* obj.unfollow(followerId,followeeId);
*/11.2 Reference
https://github.com/kamyu104/LeetCode/blob/master/C++/design-twitter.cpp
首先,Twitter 绝对不是我们能在45分钟之内 design 出来的,除非你是 Twitter 的人出去面试……所以主要就是聊聊难点在哪里.
- Home Timeline
社交类产品的一个最重要的 feature 就是 home timeline, 不管是微博、朋友圈、Facebook、Twitter, 只要你关注的人发了一条新消息,你的 home page 就应该快速更新显示.
当然,最 naive 的方案大家都能猜到:把消息存储设计成一个大 database, 每次用户刷新时就一堆 table 互相 join 来 join 去,然后 select + index. 但是你马上会发现当有大量用户同时刷新、或有大V发一条消息的时候,事情就变得比较微妙了,那么解决方案是什么呢?
下面的分析来自与 2012 年 Raffi 大神关于 twitter 设计的公开视频,点击”阅读原文”可查看 youtube 视频,还有包子君的大连话版的 leetcode 讲解哟.
https://www.infoq.com/presentations/Twitter-Timeline-Scalability
社交产品的一个重要特点就是consumption heavy, but not production heavy. 举个例子:100 个用户在一个社交网络中,大约10个人主动发更新状态,10个人愿意评论别人的状态,剩下80个人则是默默的刷呀刷.这就是社交网络的特点,也决定了社交产品的系统架构应该集中优化”读”这个操作.
既然每次刷新的速度越快越好,那么最快的方式自然是从服务器的内存中直接读取.
事实上 twitter 就是这么干的:简单来说每个 user maintain 一个 queue 来保存用户收到的 tweet id / metadata,这个 queue 放在 redis cluster 里面 (redis 是一个in-memory datastore store), 所以读取的速度非常非常快,网络内的调用延迟在 400ms 左右,考虑到 twitter 的用户量,令人满意.
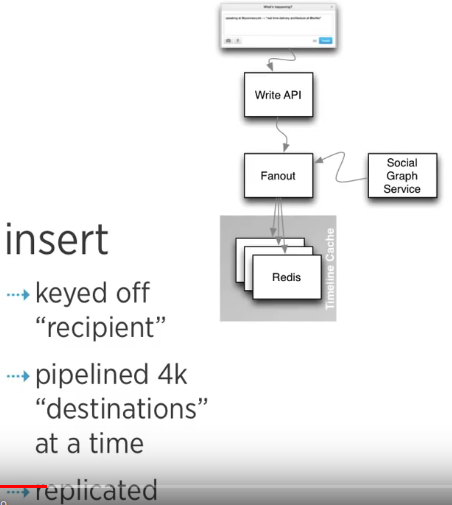
当用户发一条 tweet, twitter 内部有一个fanout process 来保证这条 twitter id / metadata 被写入每一个 user 的 queue 中 (in redis cluster). 比如 User A 有 10000 followers, 当 A 发一条 tweet, twitter 需要先通过一个单独的 social graph service, 查询 User A 的 10000 followers 以及每个人 queue 所在 redis cluster 的位置,然后插入 tweet id / metadata 到每一个 queue 中.
https://youtu.be/l55jFAGsgbs?t=105
这种设计的方式最大程度的优化了”读/刷新”操作,但是”写操作”会相对复杂一些,这是典型的系统设计中的 trade-off. 当我们在面试中遇到系统设计类的问题是,一定要想清楚、或者问清楚系统最大的 scability issue
是什么,是读操作还是写操作,还是查询?只有搞清要解决的问题,我们才能更好的切入问题,进而解决之.
- Good reading:
http://blog.bittiger.io/post156/
Video: https://www.bittiger.io/classpage/tAkRctFLtgNuCj5ev
Facebook: PULL
Instgram: PUSH
- Post_twitter
- Timeline: User Timeline, Home Timeline
- Following
- Naive Way : tweets table and user table
- Optmized Way:
Push MODE: (Alice Followee with 100 followers) send -> put -> Loadbalancer -> redis cluster(3 machines) -> Bob (follower)
Pull MODE: for celebrity
Social graph service to find follower’s location
Time and Space

400 million tweets a day flow through the system and it can take up to 5 minutes for a tweet to flow from Lady Gaga's fingers to her 31 million followers.
https://redis.io/topics/twitter-clone
NightHawk 2017
- Hot key Mitigation
High QPS
- Warming replica
https://www.infoq.com/news/2017/01/scaling-twitter-infrastructure
Let’s design a Twitter-like social networking service. Users of the service will be able to post tweets, follow other people, and favorite tweets.
Difficulty Level: Medium
11.3 1. What is Twitter?
Twitter is an online social networking service where users post and read short 140-character messages called “tweets.” Registered users can post and read tweets, but those who are not registered can only read them. Users access Twitter through their website interface, SMS, or mobile app.
11.4 2. Requirements and Goals of the System
We will be designing a simpler version of Twitter with the following requirements:
11.4.1 Functional Requirements
- Users should be able to post new tweets.
- A user should be able to follow other users.
- Users should be able to mark tweets as favorites.
- The service should be able to create and display a user’s timeline consisting of top tweets from all the people the user follows.
- Tweets can contain photos and videos.
11.5 3. Capacity Estimation and Constraints
Let’s assume we have one billion total users with 200 million daily active users (DAU). Also assume we have 100 million new tweets every day and on average each user follows 200 people.
How many favorites per day? If, on average, each user favorites five tweets per day we will have:
200M users * 5 favorites => 1B favorites
How many total tweet-views will our system generate? Let’s assume on average a user visits their timeline two times a day and visits five other people’s pages. On each page if a user sees 20 tweets, then our system will generate 28B/day total tweet-views:
200M DAU * ((2 + 5) * 20 tweets) => 28B/day
Storage Estimates Let’s say each tweet has 140 characters and we need two bytes to store a character without compression. Let’s assume we need 30 bytes to store metadata with each tweet (like ID, timestamp, user ID, etc.). Total storage we would need:
100M * (280 + 30) bytes => 30GB/day
What would our storage needs be for five years? How much storage we would need for users’ data, follows, favorites? We will leave this for the exercise.
Not all tweets will have media, let’s assume that on average every fifth tweet has a photo and every tenth has a video. Let’s also assume on average a photo is 200KB and a video is 2MB. This will lead us to have 24TB of new media every day.
(100M/5 photos * 200KB) + (100M/10 videos * 2MB) ~= 24TB/day
Bandwidth Estimates Since total ingress is 24TB per day, this would translate into 290MB/sec.
Remember that we have 28B tweet views per day. We must show the photo of every tweet (if it has a photo), but let’s assume that the users watch every 3rd video they see in their timeline. So, total egress will be:
(28B * 280 bytes) / 86400s of text => 93MB/s
+ (28B/5 * 200KB ) / 86400s of photos => 13GB/S
+ (28B/10/3 * 2MB ) / 86400s of Videos => 22GB/s
Total ~= 35GB/s11.6 4. System APIs
💡 Once we’ve finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system.
We can have SOAP or REST APIs to expose the functionality of our service. Following could be the definition of the API for posting a new tweet:
tweet(api_dev_key, tweet_data, tweet_location, user_location, media_ids)Parameters:
api_dev_key (string): The API developer key of a registered account. This will be used to, among other things, throttle users based on their allocated quota.
tweet_data (string): The text of the tweet, typically up to 140 characters.
tweet_location (string): Optional location (longitude, latitude) this Tweet refers to.
user_location (string): Optional location (longitude, latitude) of the user adding the tweet.
media_ids (number[]): Optional list of media_ids to be associated with the Tweet. (all the media photo, video, etc. need to be uploaded separately).
Returns: (string)
A successful post will return the URL to access that tweet. Otherwise, an appropriate HTTP error is returned.
11.7 5. High Level System Design
We need a system that can efficiently store all the new tweets, 100M/86400s => 1150 tweets per second and read 28B/86400s => 325K tweets per second. It is clear from the requirements that this will be a read-heavy system.
At a high level, we need multiple application servers to serve all these requests with load balancers in front of them for traffic distributions. On the backend, we need an efficient database that can store all the new tweets and can support a huge number of reads. We also need some file storage to store photos and videos.
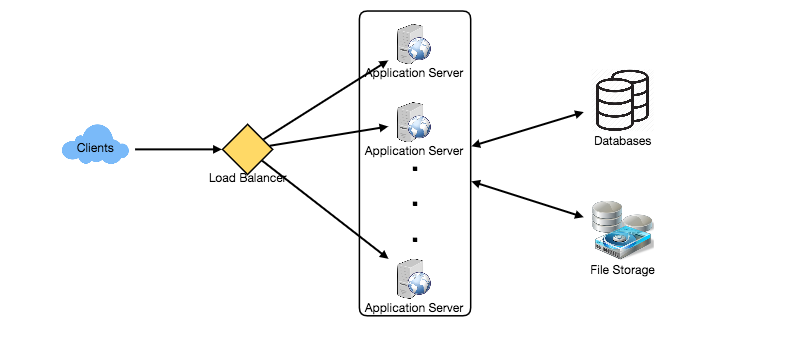
Although our expected daily write load is 100 million and read load is 28 billion tweets. This means on average our system will receive around 1160 new tweets and 325K read requests per second. This traffic will be distributed unevenly throughout the day, though, at peak time we should expect at least a few thousand write requests and around 1M read requests per second. We should keep this in mind while designing the architecture of our system.
11.8 6. Database Schema
We need to store data about users, their tweets, their favorite tweets, and people they follow.

For choosing between SQL and NoSQL databases to store the above schema, please see ‘Database schema’ under Designing Instagram.
11.9 7. Data Sharding
Since we have a huge number of new tweets every day and our read load is extremely high too, we need to distribute our data onto multiple machines such that we can read/write it efficiently. We have many options to shard our data; let’s go through them one by one:
11.9.4 Hybrid
What if we can combine sharding by TweetID and Tweet creation time? If we don’t store tweet creation time separately and use TweetID to reflect that, we can get benefits of both the approaches. This way it will be quite quick to find the latest Tweets. For this, we must make each TweetID universally unique in our system and each TweetID should contain a timestamp too.
We can use epoch time for this. Let’s say our TweetID will have two parts: the first part will be representing epoch seconds and the second part will be an auto-incrementing sequence. So, to make a new TweetID, we can take the current epoch time and append an auto-incrementing number to it. We can figure out the shard number from this TweetID and store it there.
What could be the size of our TweetID? Let’s say our epoch time starts today, how many bits we would need to store the number of seconds for the next 50 years?
86400 sec/day * 365 (days a year) * 50 (years) => 1.6B

We would need 31 bits to store this number. Since on average we are expecting 1150 new tweets per second, we can allocate 17 bits to store auto incremented sequence; this will make our TweetID 48 bits long. So, every second we can store (2^17 => 130K) new tweets. We can reset our auto incrementing sequence every second. For fault tolerance and better performance, we can have two database servers to generate auto-incrementing keys for us, one generating even numbered keys and the other generating odd numbered keys.
If we assume our current epoch seconds are “1483228800,” our TweetID will look like this:
1483228800 000001
1483228800 000002
1483228800 000003
1483228800 000004
...If we make our TweetID 64bits (8 bytes) long, we can easily store tweets for the next 100 years and also store them for mili-seconds granularity.
In the above approach, we still have to query all the servers for timeline generation, but our reads (and writes) will be substantially quicker.
- Since we don’t have any secondary index (on creation time) this will reduce our write latency.
- While reading, we don’t need to filter on creation-time as our primary key has epoch time included in it.
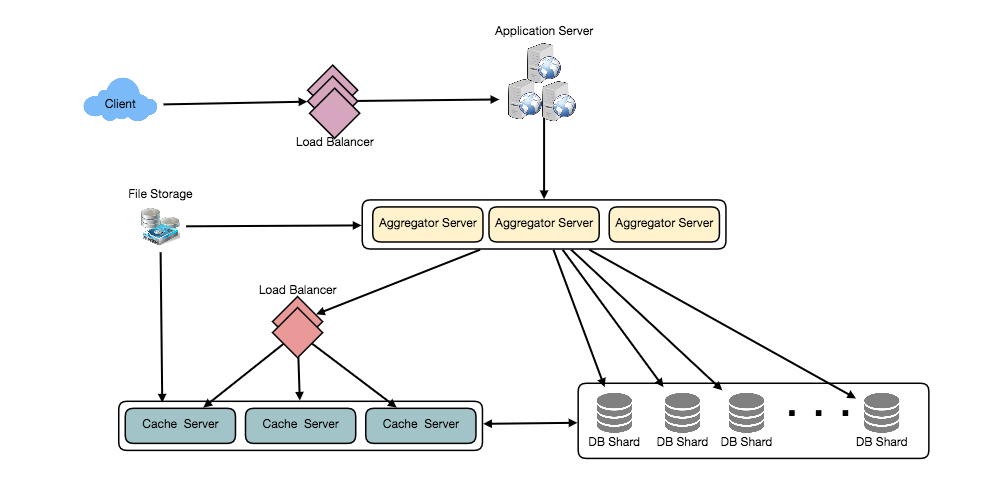
11.10 8. Cache
We can introduce a cache for database servers to cache hot tweets and users. We can use an off-the-shelf solution like Memcache that can store the whole tweet objects. Application servers, before hitting database, can quickly check if the cache has desired tweets. Based on clients’ usage patterns we can determine how many cache servers we need.
Which cache replacement policy would best fit our needs? When the cache is full and we want to replace a tweet with a newer/hotter tweet, how would we choose? Least Recently Used (LRU) can be a reasonable policy for our system. Under this policy, we discard the least recently viewed tweet first.
How can we have a more intelligent cache? If we go with 80-20 rule, that is 20% of tweets generating 80% of read traffic which means that certain tweets are so popular that a majority of people read them. This dictates that we can try to cache 20% of daily read volume from each shard.
What if we cache the latest data? Our service can benefit from this approach. Let’s say if 80% of our users see tweets from the past three days only; we can try to cache all the tweets from the past three days. Let’s say we have dedicated cache servers that cache all the tweets from all the users from the past three days. As estimated above, we are getting 100 million new tweets or 30GB of new data every day (without photos and videos). If we want to store all the tweets from last three days, we will need less than 100GB of memory. This data can easily fit into one server, but we should replicate it onto multiple servers to distribute all the read traffic to reduce the load on cache servers. So whenever we are generating a user’s timeline, we can ask the cache servers if they have all the recent tweets for that user. If yes, we can simply return all the data from the cache. If we don’t have enough tweets in the cache, we have to query the backend server to fetch that data. On a similar design, we can try caching photos and videos from the last three days.
Our cache would be like a hash table where ‘key’ would be ‘OwnerID’ and ‘value’ would be a doubly linked list containing all the tweets from that user in the past three days. Since we want to retrieve the most recent data first, we can always insert new tweets at the head of the linked list, which means all the older tweets will be near the tail of the linked list. Therefore, we can remove tweets from the tail to make space for newer tweets.
11.11 9. Timeline Generation
For a detailed discussion about timeline generation, take a look at Designing Facebook’s Newsfeed.
11.12 10. Replication and Fault Tolerance
Since our system is read-heavy, we can have multiple secondary database servers for each DB partition. Secondary servers will be used for read traffic only. All writes will first go to the primary server and then will be replicated to secondary servers. This scheme will also give us fault tolerance, since whenever the primary server goes down we can failover to a secondary server.
11.13 11. Load Balancing
We can add Load balancing layer at three places in our system 1) Between Clients and Application servers 2) Between Application servers and database replication servers and 3) Between Aggregation servers and Cache server. Initially, a simple Round Robin approach can be adopted; that distributes incoming requests equally among servers. This LB is simple to implement and does not introduce any overhead. Another benefit of this approach is that if a server is dead, LB will take it out of the rotation and will stop sending any traffic to it. A problem with Round Robin LB is that it won’t take servers load into consideration. If a server is overloaded or slow, the LB will not stop sending new requests to that server. To handle this, a more intelligent LB solution can be placed that periodically queries backend server about their load and adjusts traffic based on that.
11.14 12. Monitoring
Having the ability to monitor our systems is crucial. We should constantly collect data to get an instant insight into how our system is doing. We can collect following metrics/counters to get an understanding of the performance of our service:
- New tweets per day/second, what is the daily peak?
- Timeline delivery stats, how many tweets per day/second our service is delivering.
- Average latency that is seen by the user to refresh timeline.
By monitoring these counters, we will realize if we need more replication, load balancing, or caching.
11.15 13. Extended Requirements
How do we serve feeds? Get all the latest tweets from the people someone follows and merge/sort them by time. Use pagination to fetch/show tweets. Only fetch top N tweets from all the people someone follows. This N will depend on the client’s Viewport, since on a mobile we show fewer tweets compared to a Web client. We can also cache next top tweets to speed things up.
Alternately, we can pre-generate the feed to improve efficiency; for details please see ‘Ranking and timeline generation’ under Designing Instagram.
Retweet: With each Tweet object in the database, we can store the ID of the original Tweet and not store any contents on this retweet object.
Trending Topics: We can cache most frequently occurring hashtags or search queries in the last N seconds and keep updating them after every M seconds. We can rank trending topics based on the frequency of tweets or search queries or retweets or likes. We can give more weight to topics which are shown to more people.
Who to follow? How to give suggestions? This feature will improve user engagement. We can suggest friends of people someone follows. We can go two or three levels down to find famous people for the suggestions. We can give preference to people with more followers.
As only a few suggestions can be made at any time, use Machine Learning (ML) to shuffle and re-prioritize. ML signals could include people with recently increased follow-ship, common followers if the other person is following this user, common location or interests, etc.
Moments: Get top news for different websites for past 1 or 2 hours, figure out related tweets, prioritize them, categorize them (news, support, financial, entertainment, etc.) using ML – supervised learning or Clustering. Then we can show these articles as trending topics in Moments.
Search: Search involves Indexing, Ranking, and Retrieval of tweets. A similar solution is discussed in our next problem Design Twitter Search.