Chapter 25 Hadoop
25.1 Hadoop
Tutorial:
https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/SingleCluster.html
Download:
http://www-us.apache.org/dist/hadoop/common/
http://www-us.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
$wget http://www-us.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
$tar zxf hadoop-2.7.3.tar.gz
$mv hadoop-2.7.3 /opt/
$cd /opt/
$ln -s hadoop-2.7.3 hadoop
$echo $JAVA_HOME
/usr/lib/jvm/java-8-openjdk-amd64$ansible storm -a "mkdir -p /var/lib/hadoop/name/data"
$ansible storm -a "mkdir -p /var/lib/hadoop/data/"在hadoop-2.0.3-alpha 的配置中,yarn.nodemanager.aux-services项的默认值是”mapreduce.shuffle”,但如果在hadoop-2.2 中继续使用这个值,NodeManager 会启动失败,报错:org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices: Failed to initialize mapreduce.shuffle 解决方案: 将yarn.nodemanager.aux-services项的值改为”mapreduce_shuffle”.
$bin/hdfs namenode -format
...
[587][ubuntu][0][-bash](12:29:55)[0](root) : /opt/hadoop
$ll /tmp/hadoop-root/
total 12
drwxr-xr-x 3 root root 4096 Feb 18 12:29 ./
drwxrwxrwt 23 root root 4096 Feb 18 12:29 ../
drwxr-xr-x 3 root root 4096 Feb 18 12:29 dfs/
[588][ubuntu][0][-bash](12:30:00)[0](root) : /opt/hadoop
$ll /tmp/hadoop-root/dfs/name/current/
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
[588][ubuntu][0][-bash](12:30:00)[0](root) : /opt/hadoop
$ll /tmp/hadoop-root/dfs/name/current/
total 24
drwxr-xr-x 2 root root 4096 Feb 18 12:29 ./
drwxr-xr-x 3 root root 4096 Feb 18 12:29 ../
-rw-r--r-- 1 root root 351 Feb 18 12:29 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 Feb 18 12:29 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 Feb 18 12:29 seen_txid
-rw-r--r-- 1 root root 202 Feb 18 12:29 VERSION
[589][ubuntu][0][-bash](12:30:08)[0](root) : /opt/hadoop
$sbin/start-dfs.sh
Starting namenodes on [192.168.254.128]
192.168.254.128: starting namenode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-namenode-ubuntu.out
192.168.254.128: Connection to 192.168.254.128 closed.
localhost: starting datanode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-datanode-ubuntu.out
localhost: Connection to localhost closed.
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-ubuntu.out
0.0.0.0: Connection to 0.0.0.0 closed.
[590][ubuntu][0][-bash](12:30:35)[0](root) : /opt/hadoop
$jps
14417 DataNode
14259 NameNode
14612 SecondaryNameNode
14731 Jps
[591][ubuntu][0][-bash](12:31:03)[0](root) : /opt/hadoop
$25.1.1 Start/Stop a Hadoop Cluster
- start hadoop and yarn
ansible hadoop_master -a "start-dfs.sh"
ansible hadoop_master -a "start-yarn.sh"
ansible hadoop -a "jps"
ansible hadoop_master -a "yarn node -list"
ansible hadoop_master -a "yarn application -list"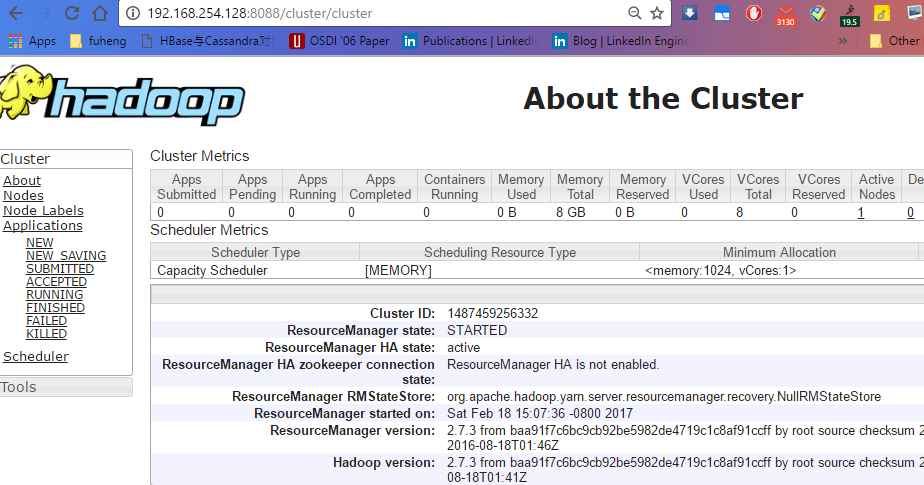
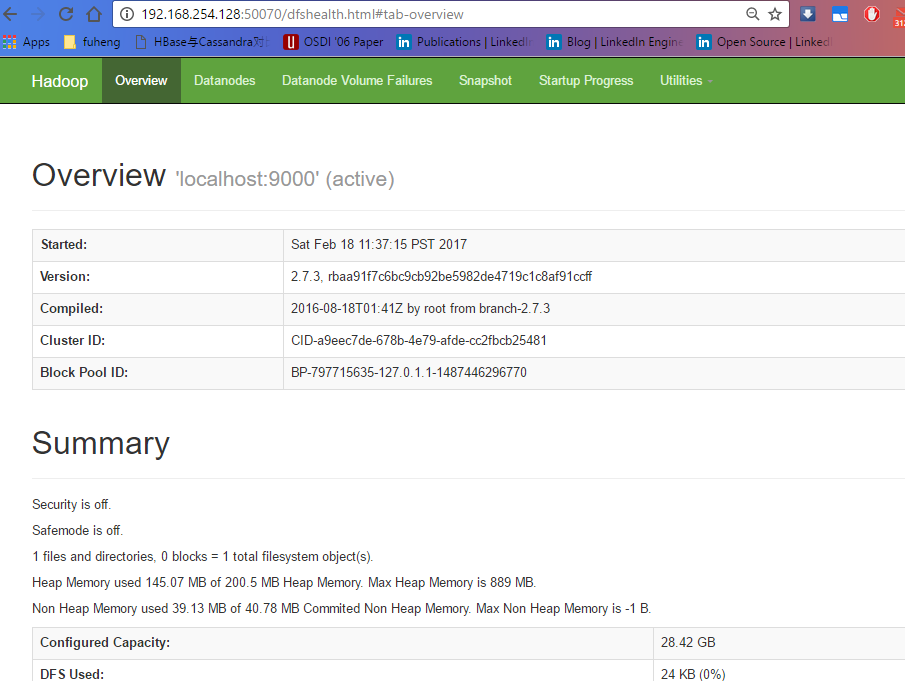
http://u3:50070
http://u3:50070/explorer.html#/
- stop hadoop and yarn
ansible hadoop_master -a "stop-yarn.sh"
ansible hadoop_master -a "stop-dfs.sh"25.2 zookeeper
一,什么是zookeeper?
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive) 、 小猪(Pig) 的管理员, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等项目中都采用到了 Zookeeper.ZooKeeper是一个分布式应用程序协调服务,ZooKeeper是以Fast Paxos算法为基础,实现同步服务,配置维护和命名服务等分布式应用.
上面的解释感觉还不够,太官方了.Zookeeper 从程序员的角度来讲可以理解为Hadoop的整体监控系统.如果namenode,HMaster宕机后,这时候Zookeeper重新选出leader.这是它最大的作用所在.
二、zookeeper的作用
1.Zookeeper加强集群稳定性
Zookeeper通过一种和文件系统很像的层级命名空间来让分布式进程互相协同工作.这些命名空间由一系列数据寄存器组成,我们也叫这些数据寄存器为znodes.这些znodes就有点像是文件系统中的文件和文件夹.和文件系统不一样的是,文件系统的文件是存储在存储区上的,而zookeeper的数据是存储在内存上的.同时,这就意味着zookeeper有着高吞吐和低延迟.
Zookeeper实现了高性能,高可靠性,和有序的访问.高性能保证了zookeeper能应用在大型的分布式系统上.高可靠性保证它不会由于单一节点的故障而造成任何问题.有序的访问能保证客户端可以实现较为复杂的同步操作.
2.Zookeeper加强集群持续性
ZooKeeper Service
组成Zookeeper的各个服务器必须要能相互通信.他们在内存中保存了服务器状态,也保存了操作的日志,并且持久化快照.只要大多数的服务器是可用的,那么Zookeeper就是可用的.
客户端连接到一个Zookeeper服务器,并且维持TCP连接.并且发送请求,获取回复,获取事件,并且发送连接信号.如果这个TCP连接断掉了,那么客户端可以连接另外一个服务器.
Zookeeper保证集群有序性
Zookeeper使用数字来对每一个更新进行标记.这样能保证Zookeeper交互的有序.后续的操作可以根据这个顺序实现诸如同步操作这样更高更抽象的服务.
Zookeeper保证集群高效
Zookeeper的高效更表现在以读为主的系统上.Zookeeper可以在千台服务器组成的读写比例大约为10:1的分布系统上表现优异.
数据结构和分等级的命名空间
Zookeeper的命名空间的结构和文件系统很像.一个名字和文件一样使用/的路径表现,zookeeper的每个节点都是被路径唯一标识
三、zookeeper在Hadoop及hbase中具体作用
1,Hadoop有NameNode,HBase有HMaster,为什么还需要zookeeper,下面给大家通过例子给大家介绍.
一个Zookeeper的集群中,3个Zookeeper节点.一个leader,两个follower的情况下,停掉leader,然后两个follower选举出一个leader.获取的数据不变.我想Zookeeper能够帮助Hadoop做到:
Hadoop,使用Zookeeper的事件处理确保整个集群只有一个NameNode,存储配置信息等. HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
2,hbase regionserver 向zookeeper注册,提供hbase regionserver状态信息(是否在线)
3,hmaster启动时候会将hbase 系统表-ROOT- 加载到 zookeeper cluster,通过zookeeper cluster可以获取当前系统表.META.的存储所对应的regionserver信息.
HMaster主要作用在于,通过HMaster维护系统表-ROOT-,.META.,记录regionserver所对应region变化信息.此外还负责监控处理当前hbase cluster中regionserver状态变化信息.
hbase regionserver则用于多个/单个维护region.region则对应为hbase数据表的表分区数据维护.
Zookeeper是hadoop的一个子项目,虽然源自hadoop,但是我发现zookeeper脱离hadoop的范畴开发分布式框架的运用越来越多.今天我想谈谈zookeeper,本文不谈如何使用zookeeper,而是zookeeper到底有哪些实际的运用,哪些类型的应用能发挥zookeeper的优势,最后谈谈zookeeper对分布式网站架构能产生怎样的作用.
Zookeeper是针对大型分布式系统的高可靠的协调系统.由这个定义我们知道zookeeper是个协调系统,作用的对象是分布式系统.为什么分布式系统需要一个协调系统了?理由如下:
开发分布式系统是件很困难的事情,其中的困难主要体现在分布式系统的”部分失败”.”部分失败”是指信息在网络的两个节点之间传送时候,如果网络出了故障,发送者无法知道接收者是否收到了这个信息,而且这种故障的原因很复杂,接收者可能在出现网络错误之前已经收到了信息,也可能没有收到,又或接收者的进程死掉了.发送者能够获得真实情况的唯一办法就是重新连接到接收者,询问接收者错误的原因,这就是分布式系统开发里的”部分失败”问题.
Zookeeper就是解决分布式系统”部分失败”的框架.Zookeeper不是让分布式系统避免”部分失败”问题,而是让分布式系统当碰到部分失败时候,可以正确的处理此类的问题,让分布式系统能正常的运行.
下面我要讲讲zookeeper的实际运用场景:
场景一:有一组服务器向客户端提供某种服务(例如:我前面做的分布式网站的服务端,就是由四台服务器组成的集群,向前端集群提供服务),我们希望客户端每次请求服务端都可以找到服务端集群中某一台服务器,这样服务端就可以向客户端提供客户端所需的服务.对于这种场景,我们的程序中一定有一份这组服务器的列表,每次客户端请求时候,都是从这份列表里读取这份服务器列表.那么这分列表显然不能存储在一台单节点的服务器上,否则这个节点挂掉了,整个集群都会发生故障,我们希望这份列表时高可用的.高可用的解决方案是:这份列表是分布式存储的,它是由存储这份列表的服务器共同管理的,如果存储列表里的某台服务器坏掉了,其他服务器马上可以替代坏掉的服务器,并且可以把坏掉的服务器从列表里删除掉,让故障服务器退出整个集群的运行,而这一切的操作又不会由故障的服务器来操作,而是集群里正常的服务器来完成.这是一种主动的分布式数据结构,能够在外部情况发生变化时候主动修改数据项状态的数据机构.Zookeeper框架提供了这种服务.这种服务名字就是:统一命名服务,它和javaEE里的JNDI服务很像.
场景二:分布式锁服务.当分布式系统操作数据,例如:读取数据、分析数据、最后修改数据.在分布式系统里这些操作可能会分散到集群里不同的节点上,那么这时候就存在数据操作过程中一致性的问题,如果不一致,我们将会得到一个错误的运算结果,在单一进程的程序里,一致性的问题很好解决,但是到了分布式系统就比较困难,因为分布式系统里不同服务器的运算都是在独立的进程里,运算的中间结果和过程还要通过网络进行传递,那么想做到数据操作一致性要困难的多.Zookeeper提供了一个锁服务解决了这样的问题,能让我们在做分布式数据运算时候,保证数据操作的一致性.
场景三:配置管理.在分布式系统里,我们会把一个服务应用分别部署到n台服务器上,这些服务器的配置文件是相同的(例如:我设计的分布式网站框架里,服务端就有4台服务器,4台服务器上的程序都是一样,配置文件都是一样),如果配置文件的配置选项发生变化,那么我们就得一个个去改这些配置文件,如果我们需要改的服务器比较少,这些操作还不是太麻烦,如果我们分布式的服务器特别多,比如某些大型互联网公司的hadoop集群有数千台服务器,那么更改配置选项就是一件麻烦而且危险的事情.这时候zookeeper就可以派上用场了,我们可以把zookeeper当成一个高可用的配置存储器,把这样的事情交给zookeeper进行管理,我们将集群的配置文件拷贝到zookeeper的文件系统的某个节点上,然后用zookeeper监控所有分布式系统里配置文件的状态,一旦发现有配置文件发生了变化,每台服务器都会收到zookeeper的通知,让每台服务器同步zookeeper里的配置文件,zookeeper服务也会保证同步操作原子性,确保每个服务器的配置文件都能被正确的更新.
场景四:为分布式系统提供故障修复的功能.集群管理是很困难的,在分布式系统里加入了zookeeper服务,能让我们很容易的对集群进行管理.集群管理最麻烦的事情就是节点故障管理,zookeeper可以让集群选出一个健康的节点作为master,master节点会知道当前集群的每台服务器的运行状况,一旦某个节点发生故障,master会把这个情况通知给集群其他服务器,从而重新分配不同节点的计算任务.Zookeeper不仅可以发现故障,也会对有故障的服务器进行甄别,看故障服务器是什么样的故障,如果该故障可以修复,zookeeper可以自动修复或者告诉系统管理员错误的原因让管理员迅速定位问题,修复节点的故障.大家也许还会有个疑问,master故障了,那怎么办了?zookeeper也考虑到了这点,zookeeper内部有一个”选举领导者的算法”,master可以动态选择,当master故障时候,zookeeper能马上选出新的master对集群进行管理.
下面我要讲讲zookeeper的特点:
zookeeper是一个精简的文件系统.这点它和hadoop有点像,但是zookeeper这个文件系统是管理小文件的,而hadoop是管理超大文件的.
zookeeper提供了丰富的”构件”,这些构件可以实现很多协调数据结构和协议的操作.例如:分布式队列、分布式锁以及一组同级节点的”领导者选举”算法.
zookeeper是高可用的,它本身的稳定性是相当之好,分布式集群完全可以依赖zookeeper集群的管理,利用zookeeper避免分布式系统的单点故障的问题.
zookeeper采用了松耦合的交互模式.这点在zookeeper提供分布式锁上表现最为明显,zookeeper可以被用作一个约会机制,让参入的进程不在了解其他进程的(或网络)的情况下能够彼此发现并进行交互,参入的各方甚至不必同时存在,只要在zookeeper留下一条消息,在该进程结束后,另外一个进程还可以读取这条信息,从而解耦了各个节点之间的关系.
zookeeper为集群提供了一个共享存储库,集群可以从这里集中读写共享的信息,避免了每个节点的共享操作编程,减轻了分布式系统的开发难度.
zookeeper的设计采用的是观察者的设计模式,zookeeper主要是负责存储和管理大家关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式.
由此可见zookeeper很利于分布式系统开发,它能让分布式系统更加健壮和高效.
前不久我参加了部门的hadoop兴趣小组,测试环境的hadoop、mapreduce、hive及hbase都是我来安装的,安装hbase时候安装要预先安装zookeeper,最早我是在四台服务器上都安装了zookeeper,但是同事说安装四台和安装三台是一回事,这是因为zookeeper要求半数以上的机器可用,zookeeper才能提供服务,所以3台的半数以上就是2台了,4台的半数以上也是两台,因此装了三台服务器完全可以达到4台服务器的效果,这个问题说明zookeeper进行安装的时候通常选择奇数台服务器.在学习hadoop的过程中,我感觉zookeeper是最难理解的一个子项目,原因倒不是它技术负责,而是它的应用方向很让我困惑,所以我有关hadoop技术第一篇文章就从zookeeper开始,也不讲具体技术实现,而从zookeeper的应用场景讲起,理解了zookeeper应用的领域,我想再学习zookeeper就会更加事半功倍.
之所以今天要谈谈zookeeper,也是为我上一篇文章分布式网站框架的补充.虽然我设计网站架构是分布式结构,也做了简单的故障处理机制,比如:心跳机制,但是对集群的单点故障还是没有办法的,如果某一台服务器坏掉了,客户端任然会尝试连接这个服务器,导致部分请求的阻塞,也会导致服务器资源的浪费.不过我目前也不想去修改自己的框架,因为我总觉得在现有的服务上添加zookeeper服务会影响网站的效率,如果有独立的服务器集群部署zookeeper还是值得考虑的,但是服务器资源太宝贵了,这个可能性不大.幸好我们部门也发现了这样的问题,我们部门将开发一个强大的远程调用框架,将集群管理和通讯管理这块剥离出来,集中式提供高效可用的服务,等部门的远程框架开发完毕,我们的网站加入新的服务,我想我们的网站将会更加稳定和高效.
一、ZooKeeper是什么?
ZooKeeper is a distributed, open-source coordination service for distributed applications.
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题.
它能提供基于类似于文件系统的目录节点树方式的数据存储.
但是 Zookeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化.
通过监控这些数据状态的变化,从而可以达到基于数据的集群管理.
ZooKeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目.ZooKeeper提供一个简单的原语集合,以便于分布式应用可以在它之上构建更高层次的同步服务.ZooKeeper的设计非常易于编程,它使用的是类似于文件系统那样的树形数据结构.
(A、我不明白,它像标准的文件系统那样设计,那么ZooKeeper是一个文件系统吗?它不就是一个管理若干server的service吗?它为什么要这样的设计??)
想正确的实现一个协作服务是出了名的难,最常见的错误就是竞争条件和死锁.ZooKeeper的动机就是解放那些从事开发分布式应用的程序员,让他们避免从零开始实现协作服务.(B、ZooKeeper数据是放到内存中的,这样的设计对分布式系统有什么帮助?)
HBase中会默认使用ZooKeeper.
图示1 ZooKeeper的数据结构
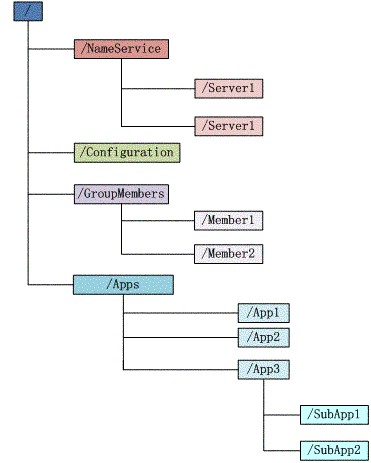
ZooKeeper数据结构的特点:
每个子目录项如 NameService 都被称作为 znode,这个 znode 是被它所在的路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1;
znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录(因为它是临时节点);
znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据
znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了
znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍二、设计目标
2.1 ZooKeeper is simple. 简单
ZooKeeper 维护着一个hierarchal的名字空间(整个文件系统所共享的),这个名字空间的组织形式很像标准文件系统(C、哪种文件系统?HDFS还是EXT3还是FAT还是NTFS?EXT3文件系统).分布式的进程可以通过操作这个共享的名字空间来协作. ZooKeeper的名字空间由称作znodes的data register组成,znodes和文件,路径很像(D、znodes到底是和文件相似还是和路径相似???翻译的害死人阿!).但是不同于典型的文件系统,ZooKeeper的数据都存放在内存中,这意味着ZooKeeper 的吞吐量会很高,同时latency会比较低.(E、这样设计对我们整体的分布式系统有什么益处?你想想,Hadoop在shuffling期间的快速排序也是将数据放入内存中,但我们的内存空间是有限的,大会都把数据放到内存中,对系统的整体性能造成的影响有多大???)
ZooKeeper的实现更重视high performance, highly available, strictly ordered access. 也就是说ZooKeeper要能够用于大型的分布式系统,同时要避免出现单点故障,还能够通过自身的有序性以便让client实现复杂的同步原语.
2.2 ZooKeeper is replicated 可复制
分布式的系统不可避免的都会有备份.
ZooKeeper Service
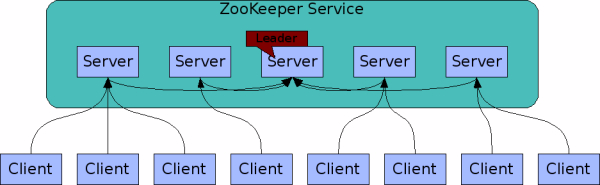
组成ZooKeeper service的所有server都必须知道其他server的存在.这些server在内存中维护着一个状态的镜像(或许就像Hadoop的NameNode一样,本身体积不大但作用很大),还有持久存储的 transaction logs和快照(在硬盘上).只要集群中多数server可访问,那么ZooKeeper服务就可用(思考:一个集群中会有各种各样的server,生产的,营销的,财务的,人力的,搜索引擎的等等,而且每个server都有自己的副本,跑了这么多的server怎么管理?我们可以搞一个管理server的service,那么这个重任就交给了ZooKeeper).
Clients 会连接到某一个ZooKeeper server上.client维护一个TCP连接,通过TCP连接, client发送请求,得到response,watch event,还有发送心跳.如果连接到某个server的TCP连接断了,client将会连接到另一个server上.
2.3 ZooKeeper is ordered. 有序
ZooKeeper给每个update操作都附上了stamp,通过stamp来反映所有transaction的顺序.
2.4 ZooKeeper is fast. 高速
ZooKeeper很快,尤其是在读操作占主导地位的服务中(靠,为什么快?因为你在内存中跑能不快么?).ZooKeeper应用可以跑在上千台机器上,当读写操作的比例为10:1时,性能达到最佳.
三、 Data model and the hierarchical namespace
ZooKeeper提供的名字空间非常像一个标准文件系统.
name的形式和Unix的路径一样,由slash隔开.ZooKeeper的名字空间中的每个node都有一个path指定.(EXT3典型的树形结构) ZooKeeper’s Hierarchical Namespace
四、 Nodes and ephemeral nodes 结点和临时结点
ZooKeeper namespace的一个特点是:每个znode都可以存放数据或者连接child(F、这里的child是个什么概念?),就好像一个文件系统的文件同时可以是路径一样.
(ZooKeeper 被设计为用来存储coordination data:包括status information,configuration,location information等等,所以每个znode存放的数据通常是很小的,数量级在KB范畴)
Znode维护着 一个stat结构,包括data changes,ACL changes的version number,还有timestamp.这样可以检查cache的有效性以及coordinated updates.每当一个znode的data改变了,version number就会增加.例如,只要一个client取了data,那么它同时也会受到这个data的version.
对每个znode中存储的data的读写操作都是原子的.读操作会拿到这个znode所关联的所有data bytes.而写操作会覆盖掉所有的data.每个node都有一个Access Control List来限制谁能做什么操作.
ZooKeeper还有临时node(ephemeral node)的概念.这种ephemeral znode只存在于创建该znode的session中.session结束了,这个znode也就被删除了.
五、 Conditional updates and watches
ZooKeeper 支持watches.Clients可以在某个znode上设置一个watch.这个znode发生的任何变化都会触发这个watch,随后watch被删除.当watch被触发时,client会接收到一个packet说该znode已经被修改了.如果client和ZooKeeper server的连接断了,那么client会接收到一个local notification.
六、 Guarantees
ZooKeeper非常快,用起来也很简单.由于它的目标是作为更复杂的服务的基础架构,所以它提供了一系列的guarantee,包括:
Sequential Consistency序列一致性: 从同一个client来的updates动作会按照这些updates发送时的顺序执行.
Atomicity原子性:Updates要么成功,要么失败.不会有部分成功的结果.
Single System Image单系统镜像:无论client连接到了哪个server,只会看到相同的view.
Reliability可靠性: 只要一个update成功执行了,那么在一个client覆盖此次update之前,该update的结果一直有效.
Timeliness时效性: 保证clients在一个确定的时限内能够观察到最新的系统数据.25.2.1 ZooKeeper - The King of Coordination
https://www.elastic.co/blog/found-zookeeper-king-of-coordination
- How Does It Work?
Three or more independent servers form a ZooKeeper cluster and elect a master. The master receives all writes and publishes changes to the other servers in an ordered fashion. The other servers provide redundancy in case the master fails and offload the master of read requests and client notifications. The concept of ordering is important in order to understand the quality of service that ZooKeeper provides. All operations are ordered as they are received and this ordering is maintained as information flows through the ZooKeeper cluster to other clients, even in the event of a master node failure. Two clients might not have the exact same point in time view of the world at any given time, but they will observe all changes in the same order.
25.2.3 The CAP Theorem
Consistency, Availability and Partition tolerance are the the three properties considered in the CAP theorem. The theorem states that a distributed system can only provide two of these three properties. ZooKeeper is a CP system with regard to the CAP theorem. This implies that it sacrifices availabilty in order to achieve consistency and partition tolerance. In other words, if it cannot guarantee correct behaviour it will not respond to queries.
25.2.4 Consistency Algorithm
Although ZooKeeper provides similar functionality to the Paxos algorithm, the core consensus algorithm of ZooKeeper is not Paxos. The algorithm used in ZooKeeper is called ZAB, short for ZooKeeper Atomic Broadcast. Like Paxos, it relies on a quorum for durability. The differences can be summed up as: only one promoter at a time, whereas Paxos may have many promoters of issues concurrently; a much stronger focus on a total ordering of all changes; and every election of a new leader is followed by a synchronization phase before any new changes are accepted. If you want to read up on the specifics of the algorithm, I recommend the paper: Zab: High-performance broadcast for primary-backup systems
What everyone running ZooKeeper in production needs to know, is that having a quorum means that more than half of the number of nodes are up and running. If your client is connecting with a ZooKeeper server which does not participate in a quorum, then it will not be able to answer any queries. This is the only way ZooKeeper is capable of protecting itself against split brains in case of a network partition.
http://stackoverflow.com/questions/3662995/explaining-apache-zookeeper
http://stackoverflow.com/questions/1106984/avoiding-split-brain-votes-and-quorum
25.3 hbase
http://hbase.apache.org/book.html#quickstart
Download: http://www-us.apache.org/dist/hbase/1.3.0/
HMaster + HRegionServer + ZooKeeper
https://www.mapr.com/blog/in-depth-look-hbase-architecture
standalone mode is to use operation system file system.
下面是我standalone模式的进程截图,可以看出hbase只启动了hmaster进程,regional server和zookeeper都没有启动.
$pstree -a
systemd noprompt
├─bash /opt/hbase/bin/hbase-daemon.sh --config /opt/hbase/conf foreground_start master
│ └─java -Dproc_master -XX:OnOutOfMemoryError=kill -9 %p -XX:+UseConcMarkSweepGC -XX:PermSize=128m-XX:MaxPermSize=
│ └─209*[{java}]
├─java -Dproc_namenode -Xmx1000m -Djava.library.path=/opt/hadoop/lib/native -Djava.net.preferIPv4Stack=true-Dhad
│ └─41*[{java}]
├─java -Dproc_datanode -Xmx1000m -Djava.library.path=/opt/hadoop/lib/native -Djava.net.preferIPv4Stack=true-Dhad
│ └─42*[{java}]
├─java -Dproc_secondarynamenode -Xmx1000m -Djava.library.path=/opt/hadoop/lib/native-Djava.net.preferIPv4Stack=t
│ └─18*[{java}]
├─java -Dproc_resourcemanager -Xmx1000m -Dhadoop.log.dir=/opt/hadoop-2.7.3/logs-Dyarn.log.dir=/opt/hadoop-2.7.3/
│ └─198*[{java}]
├─java -Dproc_nodemanager -Xmx1000m -Dhadoop.log.dir=/opt/hadoop-2.7.3/logs-Dyarn.log.dir=/opt/hadoop-2.7.3/logs
│ └─65*[{java}]
...再看看存在磁盘上的文件是什么样子的?
[580][ubuntu][0][-bash](16:03:36)[0](root) : /opt/hbase/hbase_rootdir
$ll
total 36
drwxr-xr-x 7 root root 4096 Feb 18 15:57 ./
drwxr-xr-x 11 root root 4096 Feb 18 15:44 ../
drwxr-xr-x 4 root root 4096 Feb 18 15:28 data/
-rw-r--r-- 1 root root 42 Feb 18 15:28 hbase.id
-rw-r--r-- 1 root root 7 Feb 18 15:28 hbase.version
drwxr-xr-x 2 root root 4096 Feb 18 15:58 MasterProcWALs/
drwxr-xr-x 2 root root 4096 Feb 18 16:02 oldWALs/
drwxr-xr-x 3 root root 4096 Feb 18 15:58 .tmp/
drwxr-xr-x 3 root root 4096 Feb 18 15:57 WALs/
[581][ubuntu][0][-bash](16:03:36)[0](root) : /opt/hbase/hbase_rootdir
$tree
.
├── data
│ ├── default
│ │ └── test
│ │ └── e73e2d1b06aa17672849e524ec6a9792
│ │ ├── cf
│ │ │ └── f7946df140b1496083fecf8e667476ca
│ │ └── recovered.edits
│ │ └── 11.seqid
│ └── hbase
│ ├── meta
│ │ └── 1588230740
│ │ ├── info
│ │ │ ├── 8cf3d8e0e65d4a1fac254ce92a5f8e9e
│ │ │ └── e2c7f736fd17461193dc4477a5b7dcbc
│ │ └── recovered.edits
│ │ └── 21.seqid
│ └── namespace
│ └── 2b7721fc42718d1c9dbb21cf616f40b6
│ ├── info
│ │ └── 84973be2bf9544aca8f6b20ca04c4050
│ └── recovered.edits
│ └── 13.seqid
├── hbase.id
├── hbase.version
├── MasterProcWALs
│ └── state-00000000000000000003.log
├── oldWALs
│ ├── ubuntu%2C37125%2C1487462251107.1487462255574
│ └── ubuntu%2C37125%2C1487462251107.meta.1487462256643.meta
└── WALs
└── ubuntu,37125,1487462251107
19 directories, 12 filespseudo distributed mode is to use HDFS.