Chapter 27 Spark
streaming_processing
27.1 Samza
https://www.safaribooksonline.com/library/view/learning-hadoop-2/9781783285518/ch04.html
For Samza, perhaps the most significant difference is its assumptions about message delivery. Many systems work very hard to reduce the latency of each message, sometimes with an assumption that the goal is to get the message into and out of the system as fast as possible. Samza assumes almost the opposite; its streams are persistent and resilient and any message written to a stream can be re-read for a period of time after its first arrival. As we will see, this gives significant capability around fault tolerance. Samza also builds on this model to allow each of its tasks to hold resilient local state.
27.1.1 Samza high-level architecture
Samza views the world as having three main layers or components: the streaming, execution, and processing layers.

The streaming layer provides access to the data streams, both for consumption and publication. The execution layer provides the means by which Samza applications can be run, have resources such as CPU and memory allocated, and have their life cycles managed. The processing layer is the actual Samza framework itself, and its interfaces allow per-message functionality.
Samza provides pluggable interfaces to support the first two layers though the current main implementations use Kafka for streaming and YARN for execution. We’ll discuss these further in the following sections.
27.1.2 Samza’s best friend – Apache Kafka
Samza itself does not implement the actual message stream. Instead, it provides an interface for a message system with which it then integrates. The default stream implementation is built upon Apache Kafka (http://kafka.apache.org), a messaging system also built at LinkedIn but now a successful and widely adopted open source project.
Kafka can be viewed as a message broker akin to something like RabbitMQ or ActiveMQ, but as mentioned earlier, it writes all messages to disk and scales out across multiple hosts as a core part of its design. Kafka uses the concept of a publish/subscribe model through named topics to which producers write messages and from which consumers read messages. These work much like topics in any other messaging system.
Because Kafka writes all messages to disk, it might not have the same ultra-low latency message throughput as other messaging systems, which focus on getting the message processed as fast as possible and don’t aim to store the message long term. Kafka can, however, scale exceptionally well and its ability to replay a message stream can be extremely useful. For example, if a consuming client fails, then it can re-read messages from a known good point in time, or if a downstream algorithm changes, then traffic can be replayed to utilize the new functionality.
When scaling across hosts, Kafka partitions topics and supports partition replication for fault tolerance. Each Kafka message has a key associated with the message and this is used to decide to which partition a given message is sent. This allows semantically useful partitioning, for example, if the key is a user ID in the system, then all messages for a given user will be sent to the same partition. Kafka guarantees ordered delivery within each partition so that any client reading a partition can know that they are receiving all messages for each key in that partition in the order in which they are written by the producer.
Samza periodically writes out checkpoints of the position upto which it has read in all the streams it is consuming. These checkpoint messages are themselves written to a Kafka topic. Thus, when a Samza job starts up, each task can reread its checkpoint stream to know from which position in the stream to start processing messages. This means that in effect Kafka also acts as a buffer; if a Samza job crashes or is taken down for upgrade, no messages will be lost. Instead, the job will just restart from the last checkpointed position when it restarts. This buffer functionality is also important, as it makes it easier for multiple Samza jobs to run as part of a complex workflow. When Kafka topics are the points of coordination between the jobs, one job might consume a topic being written to by another; in such cases, Kafka can help smooth out issues caused due to any given job running slower than others. Traditionally, the back pressure caused by a slow running job can be a real issue in a system comprised of multiple job stages, but Kafka as the resilient buffer allows each job to read and write at its own rate. Note that this is analogous to how multiple coordinating MapReduce jobs will use HDFS for similar purposes.
Kafka provides at-least once message delivery semantics, that is to say that any message written to Kafka will be guaranteed to be available to a client of the particular partition. Messages might be processed between checkpoints however; it is possible for duplicate messages to be received by the client. There are application-specific mechanisms to mitigate this, and both Kafka and Samza have exactly-once semantics on their roadmaps, but for now it is something you should take into consideration when designing jobs.
We won’t explain Kafka further beyond what we need to demonstrate Samza. If you are interested, check out its website and wiki; there is a lot of good information, including some excellent papers and presentations.
27.1.3 YARN integration
As mentioned earlier, just as Samza utilizes Kafka for its streaming layer implementation, it uses YARN for the execution layer. Just like any YARN application described in Chapter 3, Processing – MapReduce and Beyond, Samza provides an implementation of both an ApplicationMaster, which controls the life cycle of the overall job, plus implementations of Samza-specific functionality (called tasks) that are executed in each container. Just as Kafka partitions its topics, tasks are the mechanism by which Samza partitions its processing. Each Kafka partition will be read by a single Samza task. If a Samza job consumes multiple streams, then a given task will be the only consumer within the job for every stream partition assigned to it.
The Samza framework is told by each job configuration about the Kafka streams that are of interest to the job, and Samza continuously polls these streams to determine if any new messages have arrived. When a new message is available, the Samza task invokes a user-defined callback to process the message, a model that shouldn’t look too alien to MapReduce developers. This method is defined in an interface called StreamTask and has the following signature:
public void process(IncomingMessageEnvelope envelope,
MessageCollector collector,
TaskCoordinator coordinator)This is the core of each Samza task and defines the functionality to be applied to received messages. The received message that is to be processed is wrapped in the IncomingMessageEnvelope; output messages can be written to the MessageCollector, and task management (such as Shutdown) can be performed via the TaskCoordinator.
As mentioned, Samza creates one task instance for each partition in the underlying Kafka topic. Each YARN container will manage one or more of these tasks. The overall model then is of the Samza Application Master coordinating multiple containers, each of which is responsible for one or more StreamTask instances.
27.1.4 An independent model
Though we will talk exclusively of Kafka and YARN as the providers of Samza’s streaming and execution layers in this chapter, it is important to remember that the core Samza system uses well-defined interfaces for both the stream and execution systems. There are implementations of multiple stream sources (we’ll see one in the next section) and alongside the YARN support, Samza ships with a LocalJobRunner class. This alternative method of running tasks can execute StreamTask instances in-process on the JVM instead of requiring a full YARN cluster, which can sometimes be a useful testing and debugging tool. There is also a discussion of Samza implementations on top of other cluster manager or virtualization frameworks.
27.1.5 Hello Samza!
Since not everyone already has ZooKeeper, Kafka, and YARN clusters ready to be used, the Samza team has created a wonderful way to get started with the product. Instead of just having a Hello world! program, there is a repository called Hello Samza, which is available by cloning the repository at git://git.apache.org/samza-hello-samza.git.
This will download and install dedicated instances of ZooKeeper, Kafka, and YARN (the 3 major prerequisites for Samza), creating a full stack upon which you can submit Samza jobs.
There are also a number of example Samza jobs that process data from Wikipedia edit notifications. Take a look at the page at http://samza.apache.org/startup/hello-samza/0.8/ and follow the instructions given there. (At the time of writing, Samza is still a relatively young project and we’d rather not include direct information about the examples, which might be subject to change).
For the remainder of the Samza examples in this chapter, we’ll assume you are either using the Hello Samza package to provide the necessary components (ZooKeeper/Kafka/YARN) or you have integrated with other instances of each.
This example has three different Samza jobs that build upon each other. The first reads the Wikipedia edits, the second parses these records, and the third produces statistics based on the processed records. We’ll build our own multistream workflow shortly.
One interesting point is the WikipediaFeed example here; it uses Wikipedia as its message source instead of Kafka. Specifically, it provides another implementation of the Samza SystemConsumer interface to allow Samza to read messages from an external system. As mentioned earlier, Samza is not tied to Kafka and, as this example shows, building a new stream implementation does not have to be against a generic infrastructure component; it can be quite job-specific, as the work required is not huge.
Tip
Note that the default configuration for both ZooKeeper and Kafka will write system data to directories under /tmp, which will be what you have set if you use Hello Samza. Be careful if you are using a Linux distribution that purges the contents of this directory on a reboot. If you plan to carry out any significant testing, then it’s best to reconfigure these components to use less ephemeral locations. Change the relevant config files for each service; they are located in the service directory under the hello-samza/deploy directory.
27.1.6 Building a tweet parsing job
Let’s build our own simple job implementation to show the full code required. We’ll use parsing of the Twitter stream as the examples in this chapter and will later set up a pipe from our client consuming messages from the Twitter API into a Kafka topic. So, we need a Samza task that will read the stream of JSON messages, extract the actual tweet text, and write these to a topic of tweets.
Here is the main code from TwitterParseStreamTask.java, available at https://github.com/learninghadoop2/book-examples/blob/master/ch4/src/main/java/com/learninghadoop2/samza/tasks/TwitterParseStreamTask.java:
package com.learninghadoop2.samza.tasks;
public class TwitterParseStreamTask implements StreamTask {
@Override
public void process(IncomingMessageEnvelope envelope,
MessageCollector collector, TaskCoordinator coordinator) {
String msg = ((String) envelope.getMessage());
try {
JSONParser parser = new JSONParser();
Object obj = parser.parse(msg);
JSONObject jsonObj = (JSONObject) obj;
String text = (String) jsonObj.get("text");
collector.send(new OutgoingMessageEnvelope(
new SystemStream("kafka", "tweets-parsed"), text));
} catch (ParseException pe) {}
}
}
}The code is largely self-explanatory, but there are a few points of interest. We use JSON Simple (http://code.google.com/p/json-simple/) for our relatively straightforward JSON parsing requirements; we’ll also use it later in this book.
The IncomingMessageEnvelope and its corresponding OutputMessageEnvelope are the main structures concerned with the actual message data. Along with the message payload, the envelope will also have data concerning the system, topic name, and (optionally) partition number in addition to other metadata. For our purposes, we just extract the message body from the incoming message and send the tweet text we extract from it via a new OutgoingMessageEnvelope to a topic called tweets-parsed within a system called kafka. Note the lower case name—we’ll explain this in a moment.
The type of message in the IncomingMessageEnvelope is java.lang.Object. Samza does not currently enforce a data model and hence does not have strongly-typed message bodies. Therefore, when extracting the message contents, an explicit cast is usually required. Since each task needs to know the expected message format of the streams it processes, this is not the oddity that it may appear to be.
27.1.7 The configuration file
There was nothing in the previous code that said where the messages came from; the framework just presents them to the StreamTask implementation, but obviously Samza needs to know from where to fetch messages. There is a configuration file for each job that defines this and more. The following can be found as twitter-parse.properties at https://github.com/learninghadoop2/book-examples/blob/master/ch4/src/main/resources/twitter-parser.properties:
# Job
job.factory.class=org.apache.samza.job.yarn.YarnJobFactory
job.name=twitter-parser
# YARN
yarn.package.path=file:///home/gturkington/samza/build/distributions/learninghadoop2-0.1.tar.gz
# Task
task.class=com.learninghadoop2.samza.tasks.TwitterParseStreamTask
task.inputs=kafka.tweets
task.checkpoint.factory=org.apache.samza.checkpoint.kafka.KafkaCheckpointManagerFactory
task.checkpoint.system=kafka
# Normally, this would be 3, but we have only one broker.
task.checkpoint.replication.factor=1
# Serializers
serializers.registry.string.class=org.apache.samza.serializers.StringSerdeFactory
# Systems
systems.kafka.samza.factory=org.apache.samza.system.kafka.KafkaSystemFactory
systems.kafka.streams.tweets.samza.msg.serde=string
systems.kafka.streams.tweets-parsed.samza.msg.serde=string
systems.kafka.consumer.zookeeper.connect=localhost:2181/
systems.kafka.consumer.auto.offset.reset=largest
systems.kafka.producer.metadata.broker.list=localhost:9092
systems.kafka.producer.producer.type=sync
systems.kafka.producer.batch.num.messages=1This may look like a lot, but for now we’ll just consider the high-level structure and some key settings. The job section sets YARN as the execution framework (as opposed to the local job runner class) and gives the job a name. If we were to run multiple copies of this same job, we would also give each copy a unique ID. The task section specifies the implementation class of our task and also the name of the streams for which it should receive messages. Serializers tell Samza how to read and write messages to and from the stream and the system section defines systems by name and associates implementation classes with them.
In our case, we define only one system called kafka and we refer to this system when sending our message in the preceding task. Note that this name is arbitrary and we could call it whatever we want. Obviously, for clarity it makes sense to call the Kafka system by the same name but this is only a convention. In particular, sometimes you will need to give different names when dealing with multiple systems that are similar to each other, or sometimes even when treating the same system differently in different parts of a configuration file.
In this section, we will also specify the SerDe to be associated with the streams used by the task. Recall that Kafka messages have a body and an optional key that is used to determine to which partition the message is sent. Samza needs to know how to treat the contents of the keys and messages for these streams. Samza has support to treat these as raw bytes or specific types such as string, integer, and JSON, as mentioned earlier.
The rest of the configuration will be mostly unchanged from job to job, as it includes things such as the location of the ZooKeeper ensemble and Kafka clusters, and specifies how streams are to be checkpointed. Samza allows a wide variety of customizations and the full configuration options are detailed at http://samza.apache.org/learn/documentation/0.8/jobs/configuration-table.html.
27.1.8 Getting Twitter data into Kafka
Before we run the job, we do need to get some tweets into Kafka. Let’s create a new Kafka topic called tweets to which we’ll write the tweets.
To perform this and other Kafka-related operations, we’ll use command-line tools located within the bin directory of the Kafka distribution. If you are running a job from within the stack created as part of the Hello Samza application; this will be deploy/kafka/bin.
kafka-topics.sh is a general-purpose tool that can be used to create, update, and describe topics. Most of its usages require arguments to specify the location of the local ZooKeeper cluster, where Kafka brokers store their details, and the name of the topic to be operated upon. To create a new topic, run the following command:
$ kafka-topics.sh --zookeeper localhost:2181 \
--create –topic tweets --partitions 1 --replication-factor 1This creates a topic called tweets and explicitly sets its number of partitions and replication factor to 1. This is suitable if you are running Kafka within a local test VM, but clearly production deployments will have more partitions to scale out the load across multiple brokers and a replication factor of at least 2 to provide fault tolerance.
Use the list option of the kafka-topics.sh tool to simply show the topics in the system, or use describe to get more detailed information on specific topics:
$ kafka-topics.sh --zookeeper localhost:2181 --describe --topic tweets
Topic:tweets PartitionCount:1 ReplicationFactor:1 Configs:
Topic: tweets Partition: 0 Leader: 0 Replicas: 0 Isr: 0The multiple 0s are possibly confusing as these are labels and not counts. Each broker in the system has an ID that usually starts from 0, as do the partitions within each topic. The preceding output is telling us that the topic called tweets has a single partition with ID 0, the broker acting as the leader for that partition is broker 0, and the set of in-sync replicas (ISR) for this partition is again only broker 0. This last value is particularly important when dealing with replication.
We’ll use our Python utility from previous chapters to pull JSON tweets from the Twitter feed, and then use a Kafka CLI message producer to write the messages to a Kafka topic. This isn’t a terribly efficient way of doing things, but it is suitable for illustration purposes. Assuming our Python script is in our home directory, run the following command from within the Kafka bin directory:
$ python ~/stream.py –j | ./kafka-console-producer.sh \
--broker-list localhost:9092 --topic tweetsThis will run indefinitely so be careful not to leave it running overnight on a test VM with small disk space, not that the authors have ever done such a thing.
27.1.9 Running a Samza job
To run a Samza job, we need our code to be packaged along with the Samza components required to execute it into a .tar.gz archive that will be read by the YARN NodeManager. This is the file referred to by the yarn.file.package property in the Samza task configuration file.
When using the single node Hello Samza we can just use an absolute path on the filesystem, as seen in the previous configuration example. For jobs on larger YARN grids, the easiest way is to put the package onto HDFS and refer to it by an hdfs:// URI or on a web server (Samza provides a mechanism to allow YARN to read the file via HTTP).
Because Samza has multiple subcomponents and each subcomponent has its own dependencies, the full YARN package can end up containing a lot of JAR files (over 100!). In addition, you need to include your custom code for the Samza task as well as some scripts from within the Samza distribution. It’s not something to be done by hand. In the sample code for this chapter, found at https://github.com/learninghadoop2/book-examples/tree/master/ch4, we have set up a sample structure to hold the code and config files and provided some automation via Gradle to build the necessary task archive and start the tasks.
When in the root of the Samza example code directory for this book, perform the following command to build a single file archive containing all the classes of this chapter compiled together and bundled with all the other required files:
$ ./gradlew targzThis Gradle task will not only create the necessary .tar.gz archive in the build/distributions directory, but will also store an expanded version of the archive under build/samza-package. This will be useful, as we will use Samza scripts stored in the bin directory of the archive to actually submit the task to YARN.
So now, let’s run our job. We need to have file paths for two things: the Samza run-job.sh script to submit a job to YARN and the configuration file for our job. Since our created job package has all the compiled tasks bundled together, it is by using a different configuration file that specifies a specific task implementation class in the task.class property that we tell Samza which task to run. To actually run the task, we can run the following command from within the exploded project archive under build/samza-archives:
$ bin/run-job.sh \
--config-factory=org.apache.samza.config.factories.PropertiesConfigFactory \
--config-path=]config/twitter-parser.propertiesFor convenience, we added a Gradle task to run this job:
$ ./gradlew runTwitterParserTo see the output of the job, we’ll use the Kafka CLI client to consume messages:
$ ./kafka-console-consumer.sh –zookeeper localhost:2181 –topic tweets-parsedYou should see a continuous stream of tweets appearing on the client.
Note
Note that we did not explicitly create the topic called tweets-parsed. Kafka can allow topics to be created dynamically when either a producer or consumer tries to use the topic. In many situations, though the default partitioning and replication values may not be suitable, and explicit topic creation will be required to ensure these critical topic attributes are correctly defined.
27.1.10 Samza and HDFS
You may have noticed that we just mentioned HDFS for the first time in our discussion of Samza. Though Samza integrates tightly with YARN, it has no direct integration with HDFS. At a logical level, Samza’s stream-implementing systems (such as Kafka) are providing the storage layer that is usually provided by HDFS for traditional Hadoop workloads. In the terminology of Samza’s architecture, as described earlier, YARN is the execution layer in both models, whereas Samza uses a streaming layer for its source and destination data, frameworks such as MapReduce use HDFS. This is a good example of how YARN enables alternative computational models that not only process data very differently than batch-oriented MapReduce, but that can also use entirely different storage systems for their source data.
27.1.11 Windowing functions
It’s frequently useful to generate some data based on the messages received on a stream over a certain time window. An example of this may be to record the top n attribute values measured every minute. Samza supports this through the WindowableTask interface, which has the following single method to be implemented:
public void window(MessageCollector collector, TaskCoordinator coordinator);This should look similar to the process method in the StreamTask interface. However, because the method is called on a time schedule, its invocation is not associated with a received message. The MessageCollector and TaskCoordinator parameters are still there, however, as most windowable tasks will produce output messages and may also wish to perform some task management actions.
Let’s take our previous task and add a window function that will output the number of tweets received in each windowed time period. This is the main class implementation of TwitterStatisticsStreamTask.java found at https://github.com/learninghadoop2/book-examples/blob/master/ch4/src/main/java/com/learninghadoop2/samza/tasks/TwitterStatisticsStreamTask.java:
public class TwitterStatisticsStreamTask implements StreamTask, WindowableTask {
private int tweets = 0;
@Override
public void process(IncomingMessageEnvelope envelope,
MessageCollector collector,
TaskCoordinator coordinator)
{
tweets++;
}
@Override
public void window(MessageCollector collector, TaskCoordinator coordinator) {
collector.send(new OutgoingMessageEnvelope(
new SystemStream("kafka", "tweet-stats"), "" + tweets));
// Reset counts after windowing.
tweets = 0;
}
}The TwitterStatisticsStreamTask class has a private member variable called tweets that is initialized to 0 and is incremented in every call to the process method. We therefore know that this variable will be incremented for each message passed to the task from the underlying stream implementation. Each Samza container has a single thread running in a loop that executes the process and window methods on all the tasks within the container. This means that we do not need to guard instance variables against concurrent modifications; only one method on each task within a container will be executing simultaneously.
In our window method, we send a message to a new topic we call tweet-stats and then reset the tweets variable. This is pretty straightforward and the only missing piece is how Samza will know when to call the window method. We specify this in the configuration file:
task.window.ms=5000This tells Samza to call the window method on each task instance every 5 seconds. To run the window task, there is a Gradle task:
$ ./gradlew runTwitterStatisticsIf we use kafka-console-consumer.sh to listen on the tweet-stats stream now, we will see the following output:
Number of tweets: 5012
Number of tweets: 5398Note Note that the term window in this context refers to Samza conceptually slicing the stream of messages into time ranges and providing a mechanism to perform processing at each range boundary. Samza does not directly provide an implementation of the other use of the term with regards to sliding windows, where a series of values is held and processed over time. However, the windowable task interface does provide the plumbing to implement such sliding windows.
27.1.12 Multijob workflows
As we saw with the Hello Samza examples, some of the real power of Samza comes from composition of multiple jobs and we’ll use a text cleanup job to start demonstrating this capability.
In the following section, we’ll perform tweet sentiment analysis by comparing tweets with a set of English positive and negative words. Simply applying this to the raw Twitter feed will have very patchy results, however, given how richly multilingual the Twitter stream is. We also need to consider things such as text cleanup, capitalization, frequent contractions, and so on. As anyone who has worked with any non-trivial dataset knows, the act of making the data fit for processing is usually where a large amount of effort (often the majority!) goes.
So before we try and detect tweet sentiments, let’s do some simple text cleanup; in particular, we’ll select only English language tweets and we will force their text to be lower case before sending them to a new output stream.
Language detection is a difficult problem and for this we’ll use a feature of the Apache Tika library (http://tika.apache.org). Tika provides a wide array of functionality to extract text from various sources and then to extract further information from that text. If using our Gradle scripts, the Tika dependency is already specified and will automatically be included in the generated job package. If building through another mechanism, you will need to download the Tika JAR file from the home page and add it to your YARN job package. The following code can be found as TextCleanupStreamTask.java at https://github.com/learninghadoop2/book-examples/blob/master/ch4/src/main/java/com/learninghadoop2/samza/tasks/TextCleanupStreamTask.java:
public class TextCleanupStreamTask implements StreamTask {
@Override
public void process(IncomingMessageEnvelope envelope,
MessageCollector collector, TaskCoordinator coordinator)
{
String rawtext = ((String) envelope.getMessage());
if ("en".equals(detectLanguage(rawtext))) {
collector.send(new OutgoingMessageEnvelope(
new SystemStream("kafka", "english-tweets"),
rawtext.toLowerCase()));
}
}
private String detectLanguage(String text) {
LanguageIdentifier li = new LanguageIdentifier(text);
return li.getLanguage();
}
}This task is quite straightforward thanks to the heavy lifting performed by Tika. We create a utility method that wraps the creation and use of a Tika, LanguageDetector, and then we call this method on the message body of each incoming message in the process method. We only write to the output stream if the result of applying this utility method is “en”, that is, the two-letter code for English.
The configuration file for this task is similar to that of our previous task, with the specific values for the task name and implementing class. It is in the repository as textcleanup.properties at https://github.com/learninghadoop2/book-examples/blob/master/ch4/src/main/resources/textcleanup.properties. We also need to specify the input stream:
task.inputs=kafka.tweets-parsedThis is important because we need this task to parse the tweet text that was extracted in the earlier task and avoid duplicating the JSON parsing logic that is best encapsulated in one place. We can run this task with the following command:
$ ./gradlew runTextCleanupNow, we can run all three tasks together; TwitterParseStreamTask and TwitterStatisticsStreamTask will consume the raw tweet stream, while TextCleanupStreamTask will consume the output from TwitterParseStreamTask.
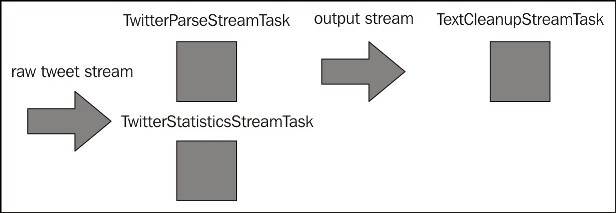
Data processing on streams
27.1.13 Tweet sentiment analysis
We’ll now implement a task to perform tweet sentiment analysis similar to what we did using MapReduce in the previous chapter. This will also show us a useful mechanism offered by Samza: bootstrap streams.
27.1.13.1 Bootstrap streams
Generally speaking, most stream-processing jobs (in Samza or another framework) will start processing messages that arrive after they start up and generally ignore historical messages. Because of its concept of replayable streams, Samza doesn’t have this limitation.
In our sentiment analysis job, we had two sets of reference terms: positive and negative words. Though we’ve not shown it so far, Samza can consume messages from multiple streams and the underlying machinery will poll all named streams and provide their messages, one at a time, to the process method. We can therefore create streams for the positive and negative words and push the datasets onto those streams. At first glance, we could plan to rewind these two streams to the earliest point and read tweets as they arrive. The problem is that Samza won’t guarantee ordering of messages from multiple streams, and even though there is a mechanism to give streams higher priority, we can’t assume that all negative and positive words will be processed before the first tweet arrives.
For such types of scenarios, Samza has the concept of bootstrap streams. If a task has any bootstrap streams defined, then it will read these streams from the earliest offset until they are fully processed (technically, it will read the streams till they get caught up, so that any new words sent to either stream will be treated without priority and will arrive interleaved between tweets).
We’ll now create a new job called TweetSentimentStreamTask that reads two bootstrap streams, collects their contents into HashMaps, gathers running counts for sentiment trends, and uses a window function to output this data at intervals. This code can be found at https://github.com/learninghadoop2/book-examples/blob/master/ch4/src/main/java/com/learninghadoop2/samza/tasks/TwitterSentimentStreamTask.java:
public class TwitterSentimentStreamTask implements StreamTask, WindowableTask {
private Set<String> positiveWords = new HashSet<String>();
private Set<String> negativeWords = new HashSet<String>();
private int tweets = 0;
private int positiveTweets = 0;
private int negativeTweets = 0;
private int maxPositive = 0;
private int maxNegative = 0;
@Override
public void process(IncomingMessageEnvelope envelope,
MessageCollector collector,
TaskCoordinator coordinator)
{
if ("positive-words".equals(envelope.getSystemStreamPartition().getStream())) {
positiveWords.add(((String) envelope.getMessage()));
} else if ("negative-words".equals(
envelope.getSystemStreamPartition().getStream())) {
negativeWords.add(((String) envelope.getMessage()));
} else if ("english-tweets".equals(
envelope.getSystemStreamPartition().getStream())) {
tweets++;
int positive = 0;
int negative = 0;
String words = ((String) envelope.getMessage());
for (String word : words.split(" ")) {
if (positiveWords.contains(word)) {
positive++;
} else if (negativeWords.contains(word)) {
negative++;
}
}
if (positive > negative) {
positiveTweets++;
}
if (negative > positive) {
negativeTweets++;
}
if (positive > maxPositive) {
maxPositive = positive;
}
if (negative > maxNegative) {
maxNegative = negative;
}
}
}
@Override
public void window(MessageCollector collector, TaskCoordinator coordinator) {
String msg = String.format(
"Tweets: %d Positive: %d Negative: %d MaxPositive: %d MinPositive: %d",
tweets, positiveTweets, negativeTweets, maxPositive, maxNegative);
collector.send(new OutgoingMessageEnvelope(
new SystemStream("kafka", "tweet-sentiment-stats"), msg));
// Reset counts after windowing.
tweets = 0;
positiveTweets = 0;
negativeTweets = 0;
maxPositive = 0;
maxNegative = 0;
}
}In this task, we add a number of private member variables that we will use to keep a running count of the number of overall tweets, how many were positive and negative, and the maximum positive and negative counts seen in a single tweet.
This task consumes from three Kafka topics. Even though we will configure two to be used as bootstrap streams, they are all still exactly the same type of Kafka topic from which messages are received; the only difference with bootstrap streams is that we tell Samza to use Kafka’s rewinding capabilities to fully re-read each message in the stream. For the other stream of tweets, we just start reading new messages as they arrive.
As hinted earlier, if a task subscribes to multiple streams, the same process method will receive messages from each stream. That is why we use envelope.getSystemStreamPartition().getStream() to extract the stream name for each given message and then act accordingly. If the message is from either of the bootstrapped streams, we add its contents to the appropriate hashmap. We break a tweet message into its constituent words, test each word for positive or negative sentiment, and then update counts accordingly. As you can see, this task doesn’t output the received tweets to another topic.
Since we don’t perform any direct processing, there is no point in doing so; any other task that wishes to consume messages can just subscribe directly to the incoming tweets stream. However, a possible modification could be to write positive and negative sentiment tweets to dedicated streams for each.
The window method outputs a series of counts and then resets the variables (as it did before). Note that Samza does have support to directly expose metrics through JMX, which could possibly be a better fit for such simple windowing examples. However, we won’t have space to cover that aspect of the project in this book.
To run this job, we need to modify the configuration file by setting the job and task names as usual, but we also need to specify multiple input streams now:
task.inputs=kafka.english-tweets,kafka.positive-words,kafka.negative-wordsThen, we need to specify that two of our streams are bootstrap streams that should be read from the earliest offset. Specifically, we set three properties for the streams. We say they are to be bootstrapped, that is, fully read before other streams, and this is achieved by specifying that the offset on each stream needs to be reset to the oldest (first) position:
systems.kafka.streams.positive-words.samza.bootstrap=true
systems.kafka.streams.positive-words.samza.reset.offset=true
systems.kafka.streams.positive-words.samza.offset.default=oldest
systems.kafka.streams.negative-words.samza.bootstrap=true
systems.kafka.streams.negative-words.samza.reset.offset=true
systems.kafka.streams.negative-words.samza.offset.default=oldestWe can run this job with the following command:
$ ./gradlew runTwitterSentimentAfter starting the job, look at the output of the messages on the tweet-sentiment-stats topic.
The sentiment detection job will bootstrap the positive and negative word streams before reading any of our newly detected lower-case English tweets.
With the sentiment detection job, we can now visualize our four collaborating jobs as shown in the following diagram:
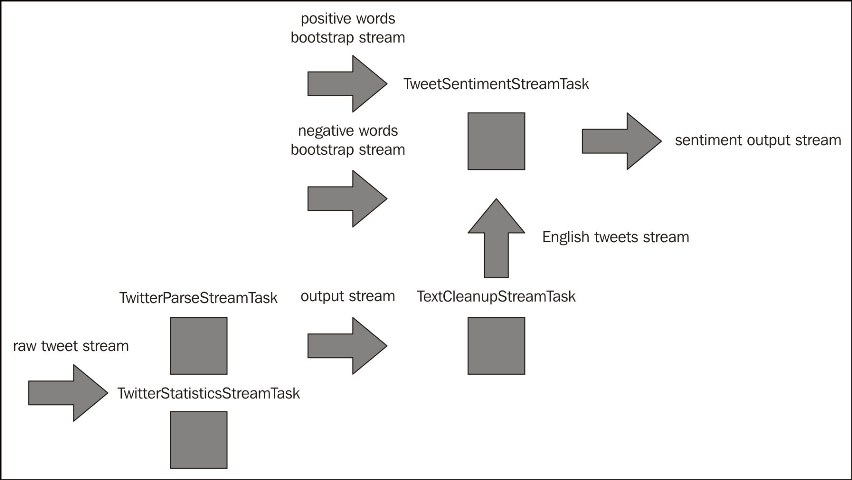
Bootstrap streams and collaborating tasks
Tip To correctly run the jobs, it may seem necessary to start the JSON parser job followed by the cleanup job before finally starting the sentiment job, but this is not the case. Any unread messages remain buffered in Kafka, so it doesn’t matter in which order the jobs of a multi-job workflow are started. Of course, the sentiment job will output counts of 0 tweets until it starts receiving data, but nothing will break if a stream job starts before those it depends on.
27.1.14 Stateful tasks
The final aspect of Samza that we will explore is how it allows the tasks processing stream partitions to have persistent local state. In the previous example, we used private variables to keep a track of running totals, but sometimes it is useful for a task to have richer local state. An example could be the act of performing a logical join on two streams, where it is useful to build up a state model from one stream and compare this with the other.
Note
Note that Samza can utilize its concept of partitioned streams to greatly optimize the act of joining streams. If each stream to be joined uses the same partition key (for example, a user ID), then each task consuming these streams will receive all messages associated with each ID across all the streams.
Samza has another abstraction similar to its notion of the framework to manage its jobs and that which implements its tasks. It defines an abstract key-value store that can have multiple concrete implementations. Samza uses existing open source projects for the on-disk implementations and used LevelDB as of v0.7 and added RocksDB as of v0.8. There is also an in-memory store that does not persist the key-value data but that may be useful in testing or potentially very specific production workloads.
Each task can write to this key-value store and Samza manages its persistence to the local implementation. To support persistent states, the store is also modeled as a stream and all writes to the store are also pushed into a stream. If a task fails, then on restart, it can recover the state of its local key-value store by replaying the messages in the backing topic. An obvious concern here will be the number of messages that need to be replayed; however, when using Kafka, for example, it compacts messages with the same key so that only the latest update remains in the topic.
We’ll modify our previous tweet sentiment example to add a lifetime count of the maximum positive and negative sentiment seen in any tweet. The following code can be found as TwitterStatefulSentimentStateTask.java at https://github.com/learninghadoop2/book-examples/blob/master/ch4/src/main/java/com/learninghadoop2/samza/tasks/TwitterStatefulSentimentStreamTask.java. Note that the process method is the same as TwitterSentimentStateTask.java, so we have omitted it here for space reasons:
public class TwitterStatefulSentimentStreamTask
implements StreamTask, WindowableTask, InitableTask
{
private Set<String> positiveWords = new HashSet<String>();
private Set<String> negativeWords = new HashSet<String>();
private int tweets = 0;
private int positiveTweets = 0;
private int negativeTweets = 0;
private int maxPositive = 0;
private int maxNegative = 0;
private KeyValueStore<String, Integer> store;
@SuppressWarnings("unchecked")
@Override
public void init(Config config, TaskContext context) {
this.store = (KeyValueStore<String, Integer>) context.getStore("tweet-store");
}
@Override
public void process(IncomingMessageEnvelope envelope,
MessageCollector collector, TaskCoordinator coordinator) {
...
}
@Override
public void window(MessageCollector collector, TaskCoordinator coordinator) {
Integer lifetimeMaxPositive = store.get("lifetimeMaxPositive");
Integer lifetimeMaxNegative = store.get("lifetimeMaxNegative");
if ((lifetimeMaxPositive == null) || (maxPositive > lifetimeMaxPositive)) {
lifetimeMaxPositive = maxPositive;
store.put("lifetimeMaxPositive", lifetimeMaxPositive);
}
if ((lifetimeMaxNegative == null) || (maxNegative > lifetimeMaxNegative)) {
lifetimeMaxNegative = maxNegative;
store.put("lifetimeMaxNegative", lifetimeMaxNegative);
}
String msg = String.format(
"Tweets: %d Positive: %d Negative: %d MaxPositive: %d "+
"MaxNegative: %d LifetimeMaxPositive: %d LifetimeMaxNegative: %d",
tweets, positiveTweets, negativeTweets, maxPositive,
maxNegative, lifetimeMaxPositive,
lifetimeMaxNegative);
collector.send(new OutgoingMessageEnvelope(
new SystemStream("kafka", "tweet-stateful-sentiment-stats"), msg));
// Reset counts after windowing.
tweets = 0;
positiveTweets = 0;
negativeTweets = 0;
maxPositive = 0;
maxNegative = 0;
}
}This class implements a new interface called InitableTask. This has a single method called init and is used when a task needs to configure aspects of its configuration before it begins execution. We use the init() method here to create an instance of the KeyValueStore class and store it in a private member variable.
KeyValueStore, as the name suggests, provides a familiar put/get type interface. In this case, we specify that the keys are of the type String and the values are Integers. In our window method, we retrieve any previously stored values for the maximum positive and negative sentiment and if the count in the current window is higher, update the store accordingly. Then, we just output the results of the window method as before.
As you can see, the user does not need to deal with the details of either the local or remote persistence of the KeyValueStore instance; this is all handled by Samza. The efficiency of the mechanism also makes it tractable for tasks to hold sizeable amount of local state, which can be particularly valuable in cases such as long-running aggregations or stream joins.
The configuration file for the job can be found at https://github.com/learninghadoop2/book-examples/blob/master/ch4/src/main/resources/twitter-stateful-sentiment.properties. It needs to have a few entries added, which are as follows:
stores.tweet-store.factory=org.apache.samza.storage.kv.KeyValueStorageEngineFactory
stores.tweet-store.changelog=kafka.twitter-stats-state
stores.tweet-store.key.serde=string
stores.tweet-store.msg.serde=integerThe first line specifies the implementation class for the store, the second line specifies the Kafka topic to be used for persistent state, and the last two lines specify the type of the store key and value.
To run this job, use the following command:
$ ./gradlew runTwitterStatefulSentimentFor convenience, the following command will start up four jobs: the JSON parser, the text cleanup, the statistics job and the stateful sentiment jobs:
$ ./gradlew runTasksSamza is a pure stream-processing system that provides pluggable implementations of its storage and execution layers. The most commonly used plugins are YARN and Kafka, and these demonstrate how Samza can integrate tightly with Hadoop YARN while using a completely different storage layer. Samza is still a relatively new project and the current features are only a subset of what is envisaged. It is recommended to consult its webpage to get the latest information on its current status.
From: https://www.safaribooksonline.com/library/view/learning-hadoop-2/9781783285518/ch04.html