Chapter 24 Storm
24.1 Theory
http://www.cnblogs.com/Jack47/p/storm_intro-1.html
今天在文章正式开始前,跟大家八卦一下Storm的作者Nathan Marz吧.
Storm的作者是Nathan Marz,Nathan Marz在BackType公司工作的时候有了Storm的点子并独自一人实现了Storm.在2011年Twitter准备收购BackType之际,Nathan Marz为了提高Twitter对BackType的估值,在一篇博客里向外界介绍了Storm.Twitter对这项技术非常感兴趣,因此在Twitter收购BackType的时候Storm发挥了重大作用.后来Nathan Marz开源Storm时,也借着Twitter的品牌影响力而让Storm名声大震!
Storm的特点之一是可靠的消息处理机制,这个机制中最重要的一环是设计一个算法来跟踪Storm中处理的数据,确保Storm知道消息是否被完整的处理.他创造出的这个算法,极大的简化了系统的设计.Nathan Marz说这算法是他职业生涯中开发的最出色的算法之一,也说明了受过良好的计算机科学的教育是非常重要的.有趣的是发明这个算法的那天,正好是他和不久前遇到的一个姑娘约会的日子.当天因为发明了这个算法而非常兴奋,导致他心思一直在这个算法上,毫无疑问就搞砸了和这个姑娘的约会!
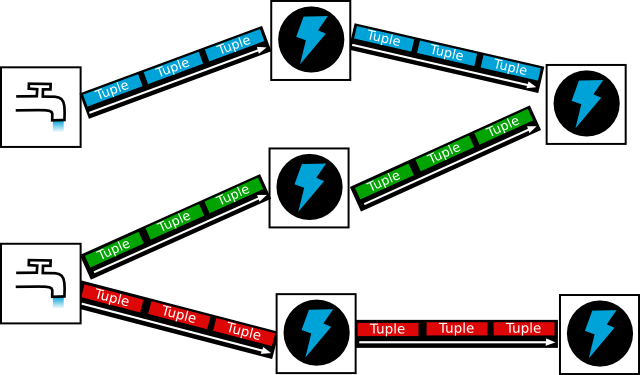
http://erhwenkuo.blogspot.com/2013/05/storm-topology.html
Guaranteeing Message Processing
- Config.TOPOLOGY_ACKERS
http://storm.apache.org/releases/current/Guaranteeing-message-processing.html
http://www.cnblogs.com/Jack47/p/guaranteeing-message-processing-in-storm.html
http://blog.jassassin.com/2014/10/22/storm/storm-ack/
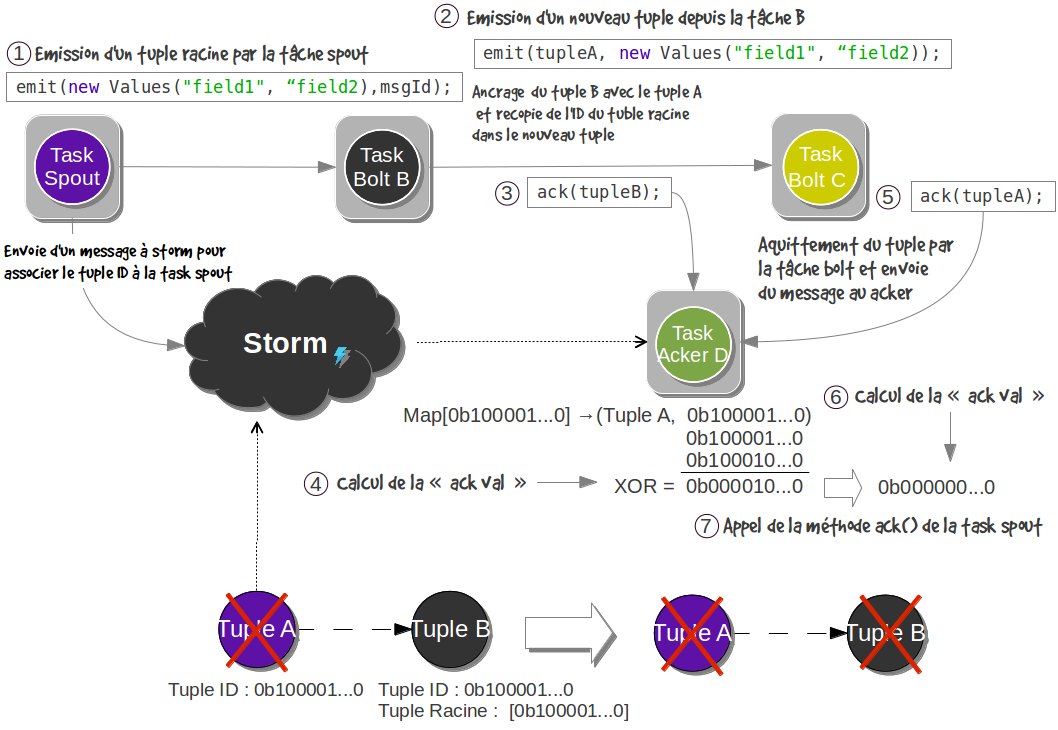
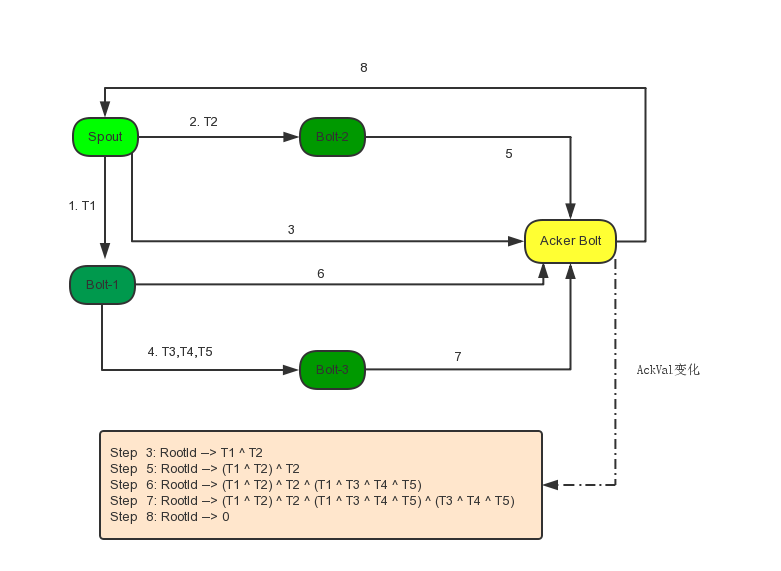
http://blog.csdn.net/suifeng3051/article/details/41682441
- Basics
Storm集群和Hadoop集群表面上看很類似.但是Hadoop上運行的是MapReduce jobs,而在Storm上運行的是拓撲(topology),這兩者之間是非常不一樣的.一個關鍵的區別是: 一個MapReduce job最終會結束, 而一個topology卻會永遠的運行(除非你手動kill掉).
在Storm的集群裡面有兩種節點: 控制節點(master node)和工作節點(worker node).控制節點上面運行一個叫Nimbus背景程式,它的作用類似Hadoop裡面的JobTracker.Nimbus負責在集群裡面分發代碼,分配計算任務給機器, 並且監控狀態.
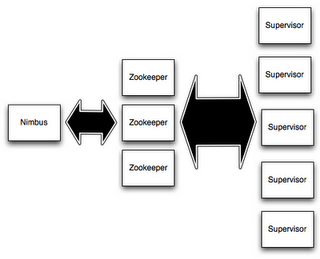
每一個工作節點上面運行一個叫做Supervisor的節點.Supervisor會監聽分配給它那台機器的工作,根據需要啟動/關閉工作進程.每一個工作進程執行一個topology的一個子集;一個運行的topology由運行在很多機器上的很多工作進程組成.
Nimbus和Supervisor之間的所有協調工作都是通過Zookeeper集群完成.另外,Nimbus進程和Supervisor進程都是快速失敗(fail-fast)和無狀態的.所有的狀態要麼在zookeeper裡面, 要麼在本地磁片上.這也就意味著你可以用kill -9來殺死Nimbus和Supervisor進程, 然後再重啟它們,就好像什麼都沒有發生過.這個設計使得Storm異常的穩定.
- Topologies
一個topology是spouts和bolts組成的圖, 通過stream groupings將圖中的spouts和bolts連接起來,如下圖:
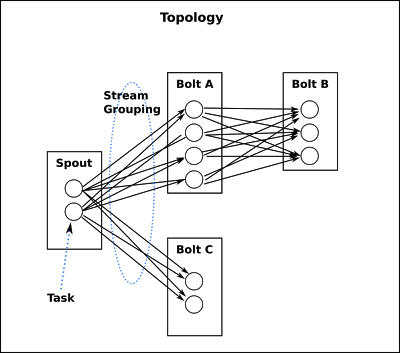
一個topology會一直運行直到你手動kill掉,Storm自動重新分配執行失敗的任務, 並且Storm可以保證你不會有資料丟失(如果開啟了高可靠性的話).如果一些機器意外停機它上面的所有任務會被轉移到其他機器上.
運行一個topology很簡單.首先,把你所有的代碼以及所依賴的jar檔都包進一個jar包.然後運行類似下面的這個命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2這個命令會運行: backtype.strom.MyTopology類別, 參數是arg1, arg2.這個類別的main函式定義這個topology並且把它提交給Nimbus.storm jar負責連接到Nimbus並且上傳jar包.
Topology的定義是一個Thrift結構,並且Nimbus就是一個Thrift服務, 你可以提交由任何語言創建的topology.上面的方面是使用JVM-based語言提交的最簡單的方法.
http://www.cnblogs.com/panfeng412/archive/2012/06/16/storm-common-patterns-of-streaming-top-n.html
24.2 Set Up Single Machine
Udacity Course at https://classroom.udacity.com/courses/ud381/lessons/2731858540/concepts/33712289620923#
一个单机版的例子:
https://github.com/shadowwalker2718/stormtest/blob/master/stormtest/LogAnalyserStorm.java
- Start Zookeeper and Storm
$ vi conf/zoo.local.cfg
tickTime=2000
dataDir=/var/lib/zk/data
clientPort=2181
initLimit=5
syncLimit=2
$zkServer.sh start zoo.local.cfg
ZooKeeper JMX enabled by default
Using config: /opt/share/zk/conf/zoo.local.cfg
Starting zookeeper ... STARTED
[15604][uu][1][bash](20:40:11)[0](root) : /opt/share/zk/conf
$#export ZOOCFGDIR=/opt/share/zk/conf- Compile:
pushd stormtest/ && javac -cp "/root/apache-storm-1.0.2/lib/*" *java && popd- Run:
java -cp .:"/root/apache-storm-1.0.2/lib/*" stormtest/LogAnalyserStorm24.3 Setting up a Storm Cluster
ansible allvm -a "mkdir -p /var/lib/storm"
ansible allvm -a "mkdir -p /var/lib/zk/data"
ansible allvm -a "mkdir -p /var/lib/zk/log"http://storm.apache.org/releases/1.1.1/Setting-up-a-Storm-cluster.html
http://www.ilanni.com/?p=11393
Set up ZK cluster:
ssh u3 "echo '1'>/var/lib/zk/data/myid"
ssh u4 "echo '2'>/var/lib/zk/data/myid"
ssh u5 "echo '3'>/var/lib/zk/data/myid"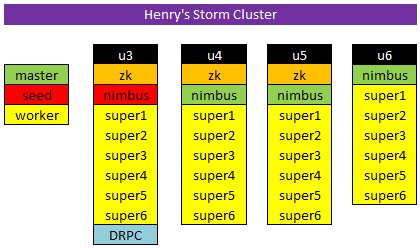
- Start KVM
$alias startstorm='for i in `seq 3 6`; do virsh start u$i; done
[523][HenryMoo][19][-bash](18:34:20)[0](root) : /opt/share/kvm
$startstorm
Domain u3 started
Domain u4 started
Domain u5 started
Domain u6 startedAbout virsh command: https://help.ubuntu.com/community/KVM/Virsh
- Start Zookeeper
ansible zk -a "zkServer.sh start"Check status:
ansible zk -a "zkServer.sh status"
zkCli.sh -server u3:2181
# ls /
# quit
zkCli.sh -server u4:2181
...
[zk: u4:2181(CONNECTED) 1] ls /
[mesos, storm, zookeeper]
[zk: u4:2181(CONNECTED) 2] quit
Quitting...- Start Storm
for i in `seq 3 6`; do
ssh -n -f u$i "sh -c 'storm nimbus > /var/lib/storm/nimbus.log 2>&1 &'";
sleep 5
ssh -n -f u$i "sh -c 'storm supervisor > /var/lib/storm/supervisor.log 2>&1 &'";
done
sleep 60 # let nimbus and supervisor to launch fully
ansible storm -a "jps"
for i in `seq 3 6`; do
ssh -n -f u$i "sh -c 'storm ui > /var/lib/storm/ui.log 2>&1 &'";
ssh -n -f u$i "sh -c 'storm logviewer > /var/lib/storm/logviewer.log 2>&1 &'";
doneThen visit: http://u3:8080/
- Stop Storm
ansible storm -a "pkill -TERM -f 'org.apache.storm.daemon'"
ansible storm -a "pkill -TERM -f 'org.apache.storm.ui.core'"
# stop zookeeper
ansible zk -a "zkServer.sh stop"- Write Topology to submit to storm
Run mvn package to create jar file, and then submit:
[549][HenryMoo][20][-bash](22:55:32)[0](root) : /opt/share/sandbox/storm/client
$/opt/share/storm/bin/storm jar target/client-1.0-SNAPSHOT.jar com.quant365.www.WordCountTopology wc0
Running: java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=...
325 [main] INFO o.a.s.StormSubmitter - Generated ZooKeeper secret payload for MD5-digest: -5260498318488052828:-8495934248057155267
370 [main] INFO o.a.s.s.a.AuthUtils - Got AutoCreds []
404 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : u6:6627
420 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : u6:6627
436 [main] INFO o.a.s.StormSubmitter - Uploading topology jar target/client-1.0-SNAPSHOT.jar to assigned location: /var/lib/storm/data/nimbus/inbox/stormjar-3107b2a6-77f9-4150-bc5a-a0b294701ff9.jar
456 [main] INFO o.a.s.StormSubmitter - Successfully uploaded topology jar to assigned location: /var/lib/storm/data/nimbus/inbox/stormjar-3107b2a6-77f9-4150-bc5a-a0b294701ff9.jar
466 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : u6:6627
467 [main] INFO o.a.s.StormSubmitter - Submitting topology wc0 in distributed mode with conf {"storm.zookeeper.topology.auth.scheme":"digest","storm.zookeeper.topology.auth.payload":"-5260498318488052828:-8495934248057155267","topology.workers":3,"topology.debug":true}
869 [main] INFO o.a.s.StormSubmitter - Finished submitting topology: wc0http://storm.apache.org/releases/1.0.3/Running-topologies-on-a-production-cluster.html
http://stackoverflow.com/questions/20799178/how-to-programmatically-kill-a-storm-topology
Kill a topology:
[554][HenryMoo][20][-bash](23:22:27)[0](root) : /opt/share/sandbox/storm/client
$/opt/share/storm/bin/storm kill wc0
Running: java -client -Ddaemon.name... org.apache.storm.command.kill_topology wc0
1415 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : u6:6627
1485 [main] INFO o.a.s.c.kill-topology - Killed topology: wc0- Shutdown && Poweroff
[562][HenryMoo][20][-bash](00:02:20)[0](root) : /opt/share/playbook
$ansible zk -a "zkServer.sh stop"
192.168.122.104 | SUCCESS | rc=0 >>
Stopping zookeeper ... STOPPEDZooKeeper JMX enabled by default
Using config: ../conf/zoo.cfg
192.168.122.103 | SUCCESS | rc=0 >>
Stopping zookeeper ... STOPPEDZooKeeper JMX enabled by default
Using config: ../conf/zoo.cfg
192.168.122.105 | SUCCESS | rc=0 >>
Stopping zookeeper ... STOPPEDZooKeeper JMX enabled by default
Using config: ../conf/zoo.cfg
[563][HenryMoo][20][-bash](00:03:16)[0](root) : /opt/share/playbook
$ansible storm -a "poweroff"
192.168.122.104 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh.",
"unreachable": true
}
192.168.122.105 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh.",
"unreachable": true
}
192.168.122.103 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh.",
"unreachable": true
}
192.168.122.106 | UNREACHABLE! => {
"changed": false,
"msg": "Failed to connect to the host via ssh.",
"unreachable": true
}- Workd Setting
We can set the number of worker to 6 in WordCountTopology.java:
//parallelism hint to set the number of workers
conf.setNumWorkers(6);
//submit the topology
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());We can use ansible to check the number of worker. It is exactly 6!
$ansible storm -a "jps" |gp worker |wc -l
6我们还可以看到在105上有1个worker,106上2个,104上1个,103上2个,总共是6个.
$ansible storm -a "jps"
192.168.122.105 | SUCCESS | rc=0 >>
1952 logviewer
1905 core
1858 Supervisor
1811 nimbus
3367 worker
3355 LogWriter
1660 QuorumPeerMain
3934 Jps
192.168.122.106 | SUCCESS | rc=0 >>
4048 worker
4051 worker
1717 nimbus
1861 logviewer
1814 core
1767 Supervisor
4024 LogWriter
4712 Jps
4025 LogWriter
192.168.122.104 | SUCCESS | rc=0 >>
4710 Jps
1959 logviewer
4104 worker
1912 core
1672 QuorumPeerMain
1865 Supervisor
1818 nimbus
4092 LogWriter
192.168.122.103 | SUCCESS | rc=0 >>
1872 Supervisor
4209 LogWriter
5057 Jps
1825 nimbus
4214 LogWriter
4233 worker
4237 worker
1966 logviewer
1679 QuorumPeerMain
1919 coreRun pstree -pa in u6, we can see:
├─java,1767 -server -Ddaemon.name=supervisor -Dstorm.options= -Dstorm.home=/opt/share/apache-storm-1.0.3...
│ ├─java,4024 -cp...
│ │ ├─java,4051 -server -Dlogging.sensitivity=S3 -Dlogfile.name=worker.log ...
│ │ │ ├─{java},4053
│ │ │ ├─{java},4056
│ │ │ ├─{java},4058
│ │ │ ├─{java},4059比较上面的ansible的输出,可以看到supervisor(1767) spawns Logwriter(4024) and Logwriter spawns worker(4051), and worker created many threads.
In u5, you can see worker.log is increading:
[473][u5][0][-bash](02:20:08)[0](root) : /var/lib/storm/data/workers/3c166d0d-4e79-4192-befb-338c858eafb0/artifacts
$tail -f worker.log
2017-03-04 02:20:05.669 c.q.w.WordCount Thread-11-count-executor[16 16] [INFO] Emitting a count of 7018 for word apple
2017-03-04 02:20:05.670 c.q.w.WordCount Thread-11-count-executor[16 16] [INFO] Emitting a count of 7018 for word away
2017-03-04 02:20:05.670 c.q.w.WordCount Thread-11-count-executor[16 16] [INFO] Emitting a count of 7018 for word keeps
2017-03-04 02:20:05.670 c.q.w.WordCount Thread-11-count-executor[16 16] [INFO] Emitting a count of 7048 for word years
2017-03-04 02:20:05.670 c.q.w.WordCount Thread-13-count-executor[10 10] [INFO] Emitting a count of 7173 for word am
2017-03-04 02:20:10.670 c.q.w.WordCount Thread-11-count-executor[16 16] [INFO] Emitting a count of 7025 for word apple
2017-03-04 02:20:10.670 c.q.w.WordCount Thread-11-count-executor[16 16] [INFO] Emitting a count of 7025 for word away
2017-03-04 02:20:10.670 c.q.w.WordCount Thread-11-count-executor[16 16] [INFO] Emitting a count of 7025 for word keeps
2017-03-04 02:20:10.670 c.q.w.WordCount Thread-11-count-executor[16 16] [INFO] Emitting a count of 7055 for word years
...storm本地运行只需要storm的jar包就可以了,结果可以在控制台直接看到,storm集群运行,结果要在log日志里看,或者存储下来.
24.4 Code
storm_src
mstsc.exe to remote desktop to linux. nginx to reverse proxy to storm ui.[not perfect]
- WordCountTopology.java
package com.quant365.www;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import com.quant365.www.RandomSentenceSpout;
public class WordCountTopology {
//Entry point for the topology
public static void main(String[] args) throws Exception {
//Used to build the topology
TopologyBuilder builder = new TopologyBuilder();
//Add the spout, with a name of 'spout'
//and parallelism hint of 5 executors
builder.setSpout("spout", new RandomSentenceSpout(), 5);
//Add the SplitSentence bolt, with a name of 'split'
//and parallelism hint of 8 executors
//shufflegrouping subscribes to the spout, and equally distributes
//tuples (sentences) across instances of the SplitSentence bolt
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
//Add the counter, with a name of 'count'
//and parallelism hint of 12 executors
//fieldsgrouping subscribes to the split bolt, and
//ensures that the same word is sent to the same instance (group by field 'word')
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
//new configuration
Config conf = new Config();
//Set to false to disable debug information when
// running in production on a cluster
conf.setDebug(false);
//If there are arguments, we are running on a cluster
if (args != null && args.length > 0) {
//parallelism hint to set the number of workers
conf.setNumWorkers(6);
//submit the topology
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
}
//Otherwise, we are running locally
else {
//Cap the maximum number of executors that can be spawned
//for a component to 3
conf.setMaxTaskParallelism(3);
//LocalCluster is used to run locally
LocalCluster cluster = new LocalCluster();
//submit the topology
cluster.submitTopology("word-count", conf, builder.createTopology());
//sleep
Thread.sleep(10000);
//shut down the cluster
cluster.shutdown();
}
}
}- WordCount.java
package com.quant365.www;
import java.util.HashMap;
import java.util.Map;
import java.util.Iterator;
import org.apache.storm.Constants;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.Config;
// For logging
import org.apache.logging.log4j.Logger;
import org.apache.logging.log4j.LogManager;
//There are a variety of bolt types. In this case, use BaseBasicBolt
public class WordCount extends BaseBasicBolt {
//Create logger for this class
private static final Logger logger = LogManager.getLogger(WordCount.class);
//For holding words and counts
Map<String, Integer> counts = new HashMap<String, Integer>();
//How often to emit a count of words
private Integer emitFrequency;
// Default constructor
public WordCount() {
emitFrequency=5; // Default to 60 seconds
}
// Constructor that sets emit frequency
public WordCount(Integer frequency) {
emitFrequency=frequency;
}
//Configure frequency of tick tuples for this bolt
//This delivers a 'tick' tuple on a specific interval,
//which is used to trigger certain actions
@Override
public Map<String, Object> getComponentConfiguration() {
Config conf = new Config();
conf.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, emitFrequency);
return conf;
}
//execute is called to process tuples
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//If it's a tick tuple, emit all words and counts
if(tuple.getSourceComponent().equals(Constants.SYSTEM_COMPONENT_ID)
&& tuple.getSourceStreamId().equals(Constants.SYSTEM_TICK_STREAM_ID)) {
for(String word : counts.keySet()) {
Integer count = counts.get(word);
collector.emit(new Values(word, count));
logger.info("Emitting a count of " + count + " for word " + word);
}
} else {
//Get the word contents from the tuple
String word = tuple.getString(0);
//Have we counted any already?
Integer count = counts.get(word);
if (count == null)
count = 0;
//Increment the count and store it
count++;
counts.put(word, count);
}
}
//Declare that this emits a tuple containing two fields; word and count
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}- SplitSentence.java
package com.quant365.www;
import java.text.BreakIterator;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
//There are a variety of bolt types. In this case, use BaseBasicBolt
public class SplitSentence extends BaseBasicBolt {
//Execute is called to process tuples
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//Get the sentence content from the tuple
String sentence = tuple.getString(0);
//An iterator to get each word
BreakIterator boundary=BreakIterator.getWordInstance();
//Give the iterator the sentence
boundary.setText(sentence);
//Find the beginning first word
int start=boundary.first();
//Iterate over each word and emit it to the output stream
for (int end=boundary.next(); end != BreakIterator.DONE; start=end, end=boundary.next()) {
//get the word
String word=sentence.substring(start,end);
//If a word is whitespace characters, replace it with empty
word=word.replaceAll("\\s+","");
//if it's an actual word, emit it
if (!word.equals("")) {
collector.emit(new Values(word));
}
}
}
//Declare that emitted tuples contain a word field
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}- RandomSentenceSpout.java
package com.quant365.www;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
//This spout randomly emits sentences
public class RandomSentenceSpout extends BaseRichSpout {
//Collector used to emit output
SpoutOutputCollector _collector;
//Used to generate a random number
Random _rand;
//Open is called when an instance of the class is created
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
//Set the instance collector to the one passed in
_collector = collector;
//For randomness
_rand = new Random();
}
//Emit data to the stream
@Override
public void nextTuple() {
//Sleep for a bit
Utils.sleep(500);
//The sentences that are randomly emitted
String[] sentences = new String[]{ "the cow jumped over the moon",
"an apple a day keeps the doctor away",
"four score and seven years ago",
"snow white and the seven dwarfs",
"i am at two with nature" };
//Randomly pick a sentence
String sentence = sentences[_rand.nextInt(sentences.length)];
//Emit the sentence
_collector.emit(new Values(sentence));
}
//Ack is not implemented since this is a basic example
@Override
public void ack(Object id) {
}
//Fail is not implemented since this is a basic example
@Override
public void fail(Object id) {
}
//Declare the output fields. In this case, an sentence
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}24.5 Online Course
https://www.safaribooksonline.com/library/view/machine-learning-/10000LCASTORM/AS_15.html
https://www.safaribooksonline.com/library/view/machine-learning-/10000LCASTORM/AS_28.html
24.6 Trident
A key difference between Trident and Storm is that Trident processes the stream in mini batches, referred to as “transactions.” This is different from Storm in that Storm performs tuple-by-tuple processing. This concept is very similar to database transactions; every transaction is assigned a transaction ID. Once all processing for a transaction is successfully completed, the transaction is considered successful, however, a failure in processing one of the transaction’s tuples will cause the entire transaction to be retransmitted. For each State, Trident will call beginCommit at the beginning of the transaction, and commit at the end of it.
http://storm.apache.org/releases/1.1.1/Trident-tutorial.html
24.7 Flux
Flux is a new framework available with Storm 0.10.0 and higher, which allows you to separate configuration from implementation. Your components are still defined in Java, but the topology is defined using a YAML file. You can package a default topology definition with your project, or use a standalone file when submitting the topology. When submitting the topology to Storm, you can use environment variables or configuration files to populate values in the YAML topology definition.
The YAML file defines the components to use for the topology and the data flow between them. You can include a YAML file as part of the jar file or you can use an external YAML file.
24.8 Heron
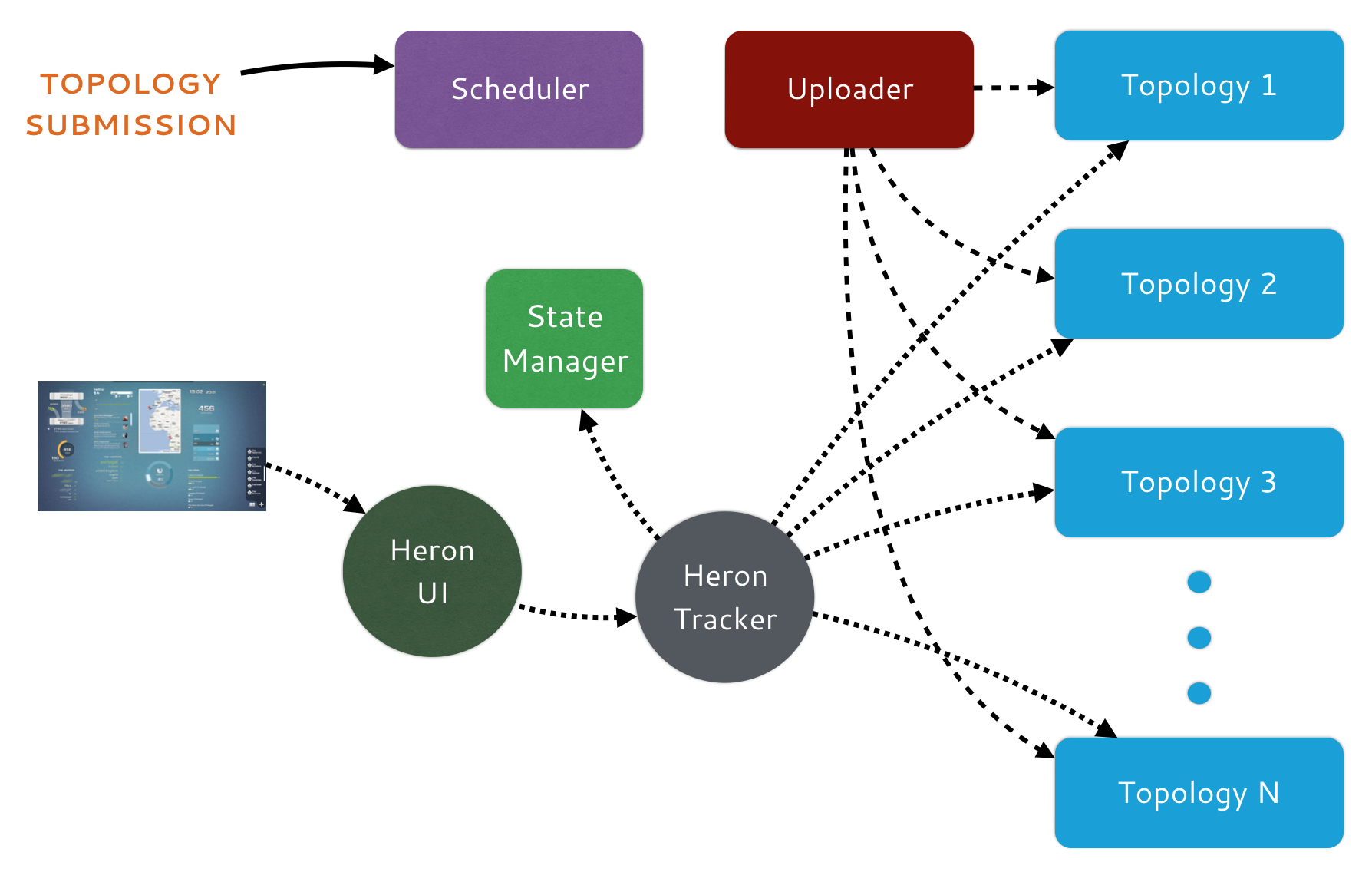
24.8.1 Build
https://twitter.github.io/heron/docs/developers/compiling/linux/
bazel --output_base=/opt/share/heron build --config=ubuntu heron/...